 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Mar 26, 2026On-policy distillation (OPD) is appealing for large language model (LLM) post-training because it evaluates teacher feedback on student-generated rollouts rather than fixed teacher traces. In long-horizon settings, however, the common sampled-token variant is fragile: it reduces distribution matching to a one-token signal and becomes increasingly unreliable as rollouts drift away from prefixes the teacher commonly visits. We revisit OPD from the estimator and implementation sides. Theoretically, token-level OPD is biased relative to sequence-level reverse-KL, but it has a much tighter worst-case variance bound; our toy study shows the same tradeoff empirically, with stronger future-reward coupling producing higher gradient variance and less stable learning. Empirically, we identify three failure modes of sampled-token OPD: an imbalanced one-token signal, unreliable teacher guidance on student-generated prefixes, and distortions caused by tokenizer or special-token mismatch. We address these issues with teacher top-K local support matching, implemented as truncated reverse-KL with top-p rollout sampling and special-token masking. Across single-task math reasoning and multi-task agentic-plus-math training, this objective yields more stable optimization and better downstream performance than sampled-token OPD.
Instant Expressive Gaussian Head Avatar via 3D-Aware Expression Distillation
Dec 18, 2025Portrait animation has witnessed tremendous quality improvements thanks to recent advances in video diffusion models. However, these 2D methods often compromise 3D consistency and speed, limiting their applicability in real-world scenarios, such as digital twins or telepresence. In contrast, 3D-aware facial animation feedforward methods -- built upon explicit 3D representations, such as neural radiance fields or Gaussian splatting -- ensure 3D consistency and achieve faster inference speed, but come with inferior expression details. In this paper, we aim to combine their strengths by distilling knowledge from a 2D diffusion-based method into a feed-forward encoder, which instantly converts an in-the-wild single image into a 3D-consistent, fast yet expressive animatable representation. Our animation representation is decoupled from the face's 3D representation and learns motion implicitly from data, eliminating the dependency on pre-defined parametric models that often constrain animation capabilities. Unlike previous computationally intensive global fusion mechanisms (e.g., multiple attention layers) for fusing 3D structural and animation information, our design employs an efficient lightweight local fusion strategy to achieve high animation expressivity. As a result, our method runs at 107.31 FPS for animation and pose control while achieving comparable animation quality to the state-of-the-art, surpassing alternative designs that trade speed for quality or vice versa. Project website is https://research.nvidia.com/labs/amri/projects/instant4d
MS-GS: Multi-Appearance Sparse-View 3D Gaussian Splatting in the Wild
Sep 19, 2025
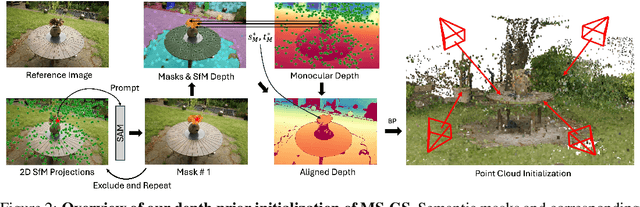
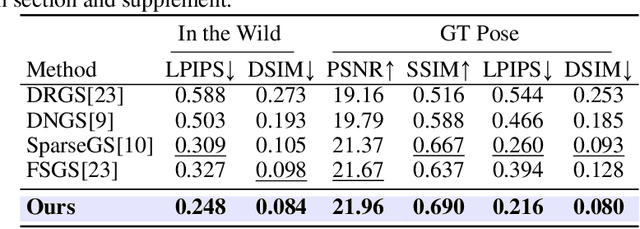
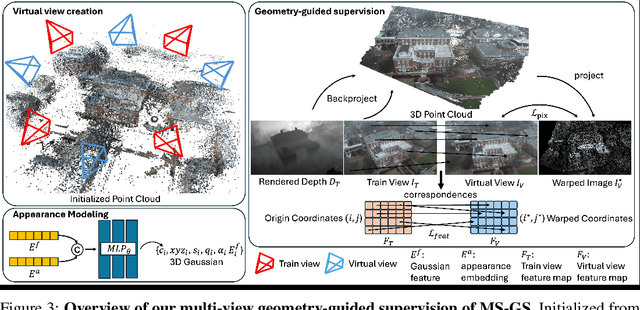
In-the-wild photo collections often contain limited volumes of imagery and exhibit multiple appearances, e.g., taken at different times of day or seasons, posing significant challenges to scene reconstruction and novel view synthesis. Although recent adaptations of Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have improved in these areas, they tend to oversmooth and are prone to overfitting. In this paper, we present MS-GS, a novel framework designed with Multi-appearance capabilities in Sparse-view scenarios using 3DGS. To address the lack of support due to sparse initializations, our approach is built on the geometric priors elicited from monocular depth estimations. The key lies in extracting and utilizing local semantic regions with a Structure-from-Motion (SfM) points anchored algorithm for reliable alignment and geometry cues. Then, to introduce multi-view constraints, we propose a series of geometry-guided supervision at virtual views in a fine-grained and coarse scheme to encourage 3D consistency and reduce overfitting. We also introduce a dataset and an in-the-wild experiment setting to set up more realistic benchmarks. We demonstrate that MS-GS achieves photorealistic renderings under various challenging sparse-view and multi-appearance conditions and outperforms existing approaches significantly across different datasets.
LIPM-Guided Reinforcement Learning for Stable and Perceptive Locomotion in Bipedal Robots
Sep 11, 2025Achieving stable and robust perceptive locomotion for bipedal robots in unstructured outdoor environments remains a critical challenge due to complex terrain geometry and susceptibility to external disturbances. In this work, we propose a novel reward design inspired by the Linear Inverted Pendulum Model (LIPM) to enable perceptive and stable locomotion in the wild. The LIPM provides theoretical guidance for dynamic balance by regulating the center of mass (CoM) height and the torso orientation. These are key factors for terrain-aware locomotion, as they help ensure a stable viewpoint for the robot's camera. Building on this insight, we design a reward function that promotes balance and dynamic stability while encouraging accurate CoM trajectory tracking. To adaptively trade off between velocity tracking and stability, we leverage the Reward Fusion Module (RFM) approach that prioritizes stability when needed. A double-critic architecture is adopted to separately evaluate stability and locomotion objectives, improving training efficiency and robustness. We validate our approach through extensive experiments on a bipedal robot in both simulation and real-world outdoor environments. The results demonstrate superior terrain adaptability, disturbance rejection, and consistent performance across a wide range of speeds and perceptual conditions.
Learning Whole-Body Loco-Manipulation for Omni-Directional Task Space Pose Tracking with a Wheeled-Quadrupedal-Manipulator
Dec 04, 2024



In this paper, we study the whole-body loco-manipulation problem using reinforcement learning (RL). Specifically, we focus on the problem of how to coordinate the floating base and the robotic arm of a wheeled-quadrupedal manipulator robot to achieve direct six-dimensional (6D) end-effector (EE) pose tracking in task space. Different from conventional whole-body loco-manipulation problems that track both floating-base and end-effector commands, the direct EE pose tracking problem requires inherent balance among redundant degrees of freedom in the whole-body motion. We leverage RL to solve this challenging problem. To address the associated difficulties, we develop a novel reward fusion module (RFM) that systematically integrates reward terms corresponding to different tasks in a nonlinear manner. In such a way, the inherent multi-stage and hierarchical feature of the loco-manipulation problem can be carefully accommodated. By combining the proposed RFM with the a teacher-student RL training paradigm, we present a complete RL scheme to achieve 6D EE pose tracking for the wheeled-quadruped manipulator robot. Extensive simulation and hardware experiments demonstrate the significance of the RFM. In particular, we enable smooth and precise tracking performance, achieving state-of-the-art tracking position error of less than 5 cm, and rotation error of less than 0.1 rad. Please refer to https://clearlab-sustech.github.io/RFM_loco_mani/ for more experimental videos.
Geometry Field Splatting with Gaussian Surfels
Nov 26, 2024Geometric reconstruction of opaque surfaces from images is a longstanding challenge in computer vision, with renewed interest from volumetric view synthesis algorithms using radiance fields. We leverage the geometry field proposed in recent work for stochastic opaque surfaces, which can then be converted to volume densities. We adapt Gaussian kernels or surfels to splat the geometry field rather than the volume, enabling precise reconstruction of opaque solids. Our first contribution is to derive an efficient and almost exact differentiable rendering algorithm for geometry fields parameterized by Gaussian surfels, while removing current approximations involving Taylor series and no self-attenuation. Next, we address the discontinuous loss landscape when surfels cluster near geometry, showing how to guarantee that the rendered color is a continuous function of the colors of the kernels, irrespective of ordering. Finally, we use latent representations with spherical harmonics encoded reflection vectors rather than spherical harmonics encoded colors to better address specular surfaces. We demonstrate significant improvement in the quality of reconstructed 3D surfaces on widely-used datasets.
Real-time 3D-aware Portrait Video Relighting
Oct 24, 2024Synthesizing realistic videos of talking faces under custom lighting conditions and viewing angles benefits various downstream applications like video conferencing. However, most existing relighting methods are either time-consuming or unable to adjust the viewpoints. In this paper, we present the first real-time 3D-aware method for relighting in-the-wild videos of talking faces based on Neural Radiance Fields (NeRF). Given an input portrait video, our method can synthesize talking faces under both novel views and novel lighting conditions with a photo-realistic and disentangled 3D representation. Specifically, we infer an albedo tri-plane, as well as a shading tri-plane based on a desired lighting condition for each video frame with fast dual-encoders. We also leverage a temporal consistency network to ensure smooth transitions and reduce flickering artifacts. Our method runs at 32.98 fps on consumer-level hardware and achieves state-of-the-art results in terms of reconstruction quality, lighting error, lighting instability, temporal consistency and inference speed. We demonstrate the effectiveness and interactivity of our method on various portrait videos with diverse lighting and viewing conditions.
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
May 06, 2024Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset.
Equirectangular image construction method for standard CNNs for Semantic Segmentation
Oct 13, 2023
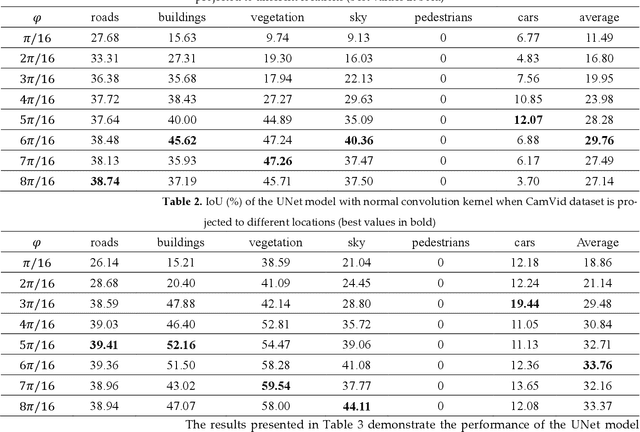
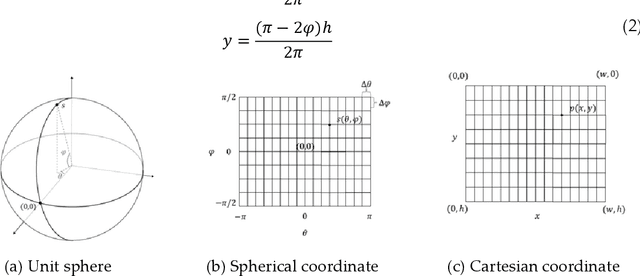
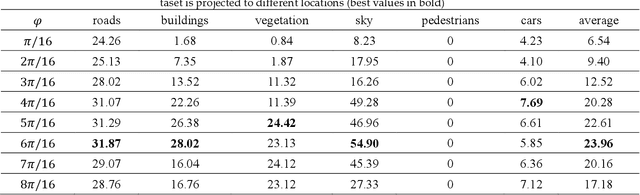
360{\deg} spherical images have advantages of wide view field, and are typically projected on a planar plane for processing, which is known as equirectangular image. The object shape in equirectangular images can be distorted and lack translation invariance. In addition, there are few publicly dataset of equirectangular images with labels, which presents a challenge for standard CNNs models to process equirectangular images effectively. To tackle this problem, we propose a methodology for converting a perspective image into equirectangular image. The inverse transformation of the spherical center projection and the equidistant cylindrical projection are employed. This enables the standard CNNs to learn the distortion features at different positions in the equirectangular image and thereby gain the ability to semantically the equirectangular image. The parameter, {\phi}, which determines the projection position of the perspective image, has been analyzed using various datasets and models, such as UNet, UNet++, SegNet, PSPNet, and DeepLab v3+. The experiments demonstrate that an optimal value of {\phi} for effective semantic segmentation of equirectangular images is 6{\pi}/16 for standard CNNs. Compared with the other three types of methods (supervised learning, unsupervised learning and data augmentation), the method proposed in this paper has the best average IoU value of 43.76%. This value is 23.85%, 10.7% and 17.23% higher than those of other three methods, respectively.
NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
Nov 15, 2022



Recent methods for synthesizing 3D-aware face images have achieved rapid development thanks to neural radiance fields, allowing for high quality and fast inference speed. However, existing solutions for editing facial geometry and appearance independently usually require retraining and are not optimized for the recent work of generation, thus tending to lag behind the generation process. To address these issues, we introduce NeRFFaceEditing, which enables editing and decoupling geometry and appearance in the pretrained tri-plane-based neural radiance field while retaining its high quality and fast inference speed. Our key idea for disentanglement is to use the statistics of the tri-plane to represent the high-level appearance of its corresponding facial volume. Moreover, we leverage a generated 3D-continuous semantic mask as an intermediary for geometry editing. We devise a geometry decoder (whose output is unchanged when the appearance changes) and an appearance decoder. The geometry decoder aligns the original facial volume with the semantic mask volume. We also enhance the disentanglement by explicitly regularizing rendered images with the same appearance but different geometry to be similar in terms of color distribution for each facial component separately. Our method allows users to edit via semantic masks with decoupled control of geometry and appearance. Both qualitative and quantitative evaluations show the superior geometry and appearance control abilities of our method compared to existing and alternative solutions.