 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquirectangular image construction method for standard CNNs for Semantic Segmentation
Paper and Code
Oct 13, 2023
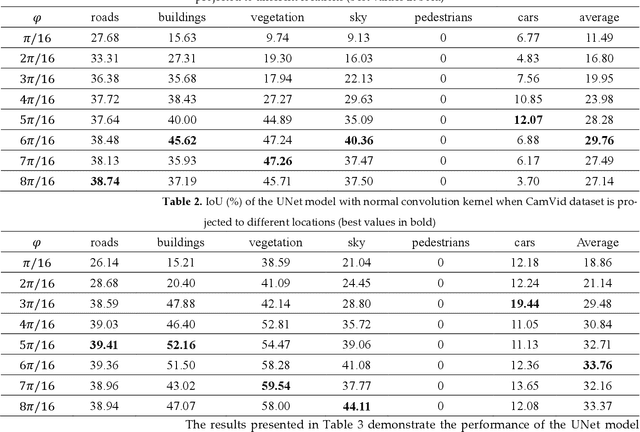
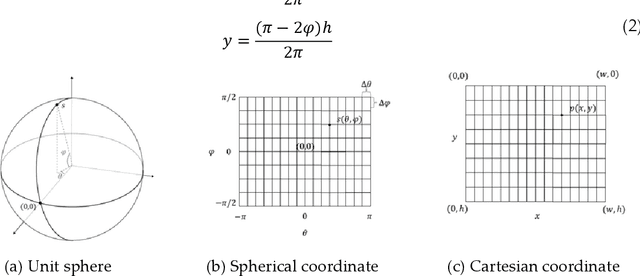
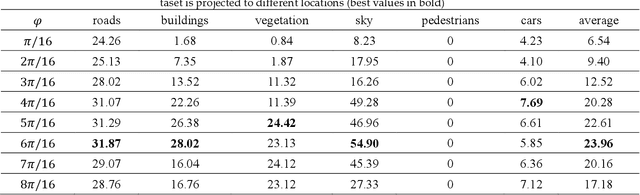
360{\deg} spherical images have advantages of wide view field, and are typically projected on a planar plane for processing, which is known as equirectangular image. The object shape in equirectangular images can be distorted and lack translation invariance. In addition, there are few publicly dataset of equirectangular images with labels, which presents a challenge for standard CNNs models to process equirectangular images effectively. To tackle this problem, we propose a methodology for converting a perspective image into equirectangular image. The inverse transformation of the spherical center projection and the equidistant cylindrical projection are employed. This enables the standard CNNs to learn the distortion features at different positions in the equirectangular image and thereby gain the ability to semantically the equirectangular image. The parameter, {\phi}, which determines the projection position of the perspective image, has been analyzed using various datasets and models, such as UNet, UNet++, SegNet, PSPNet, and DeepLab v3+. The experiments demonstrate that an optimal value of {\phi} for effective semantic segmentation of equirectangular images is 6{\pi}/16 for standard CNNs. Compared with the other three types of methods (supervised learning, unsupervised learning and data augmentation), the method proposed in this paper has the best average IoU value of 43.76%. This value is 23.85%, 10.7% and 17.23% higher than those of other three methods, respectively.