 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-RGBT Person Retrieval: Multilevel Global-Local Cross-Modal Alignment and A High-quality Benchmark
Mar 11, 2025The performance of traditional text-image person retrieval task is easily affected by lighting variations due to imaging limitations of visible spectrum sensors. In this work, we design a novel task called text-RGBT person retrieval that integrates complementary benefits from thermal and visible modalities for robust person retrieval in challenging environments. Aligning text and multi-modal visual representations is the key issue in text-RGBT person retrieval, but the heterogeneity between visible and thermal modalities may interfere with the alignment of visual and text modalities. To handle this problem, we propose a Multi-level Global-local cross-modal Alignment Network (MGANet), which sufficiently mines the relationships between modality-specific and modality-collaborative visual with the text, for text-RGBT person retrieval. To promote the research and development of this field, we create a high-quality text-RGBT person retrieval dataset, RGBT-PEDES. RGBT-PEDES contains 1,822 identities from different age groups and genders with 4,723 pairs of calibrated RGB and thermal images, and covers high-diverse scenes from both daytime and nighttime with a various of challenges such as occlusion, weak alignment and adverse lighting conditions. Additionally, we carefully annotate 7,987 fine-grained textual descriptions for all RGBT person image pairs. Extensive experiments on RGBT-PEDES demonstrate that our method outperforms existing text-image person retrieval methods. The code and dataset will be released upon the acceptance.
GLC-SLAM: Gaussian Splatting SLAM with Efficient Loop Closure
Sep 17, 2024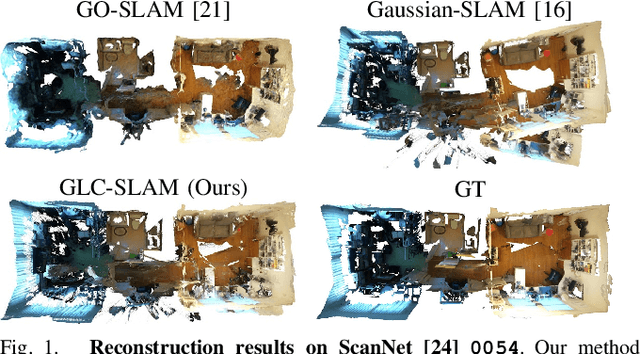
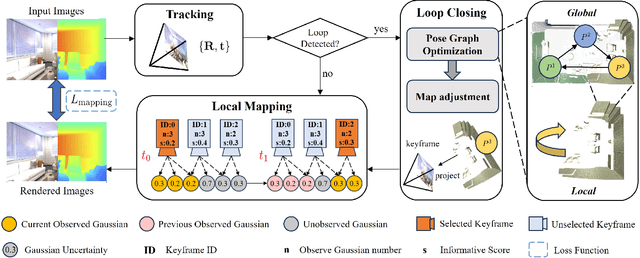

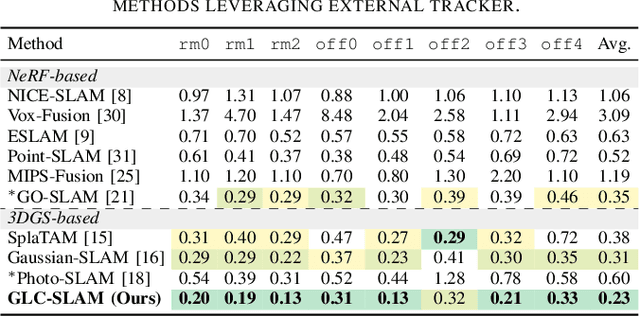
3D Gaussian Splatting (3DGS) has gained significant attention for its application in dense Simultaneous Localization and Mapping (SLAM), enabling real-time rendering and high-fidelity mapping. However, existing 3DGS-based SLAM methods often suffer from accumulated tracking errors and map drift, particularly in large-scale environments. To address these issues, we introduce GLC-SLAM, a Gaussian Splatting SLAM system that integrates global optimization of camera poses and scene models. Our approach employs frame-to-model tracking and triggers hierarchical loop closure using a global-to-local strategy to minimize drift accumulation. By dividing the scene into 3D Gaussian submaps, we facilitate efficient map updates following loop corrections in large scenes. Additionally, our uncertainty-minimized keyframe selection strategy prioritizes keyframes observing more valuable 3D Gaussians to enhance submap optimization. Experimental results on various datasets demonstrate that GLC-SLAM achieves superior or competitive tracking and mapping performance compared to state-of-the-art dense RGB-D SLAM systems.
NID-SLAM: Neural Implicit Representation-based RGB-D SLAM in dynamic environments
Jan 02, 2024Neural implicit representations have been explored to enhance visual SLAM algorithms, especially in providing high-fidelity dense map. Existing methods operate robustly in static scenes but struggle with the disruption caused by moving objects. In this paper we present NID-SLAM, which significantly improves the performance of neural SLAM in dynamic environments. We propose a new approach to enhance inaccurate regions in semantic masks, particularly in marginal areas. Utilizing the geometric information present in depth images, this method enables accurate removal of dynamic objects, thereby reducing the probability of camera drift. Additionally, we introduce a keyframe selection strategy for dynamic scenes, which enhances camera tracking robustness against large-scale objects and improves the efficiency of mapping. Experiments on publicly available RGB-D datasets demonstrate that our method outperforms competitive neural SLAM approaches in tracking accuracy and mapping quality in dynamic environments.
Equirectangular image construction method for standard CNNs for Semantic Segmentation
Oct 13, 2023
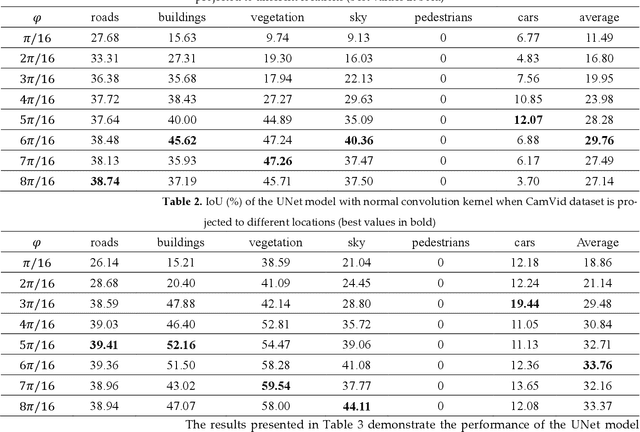
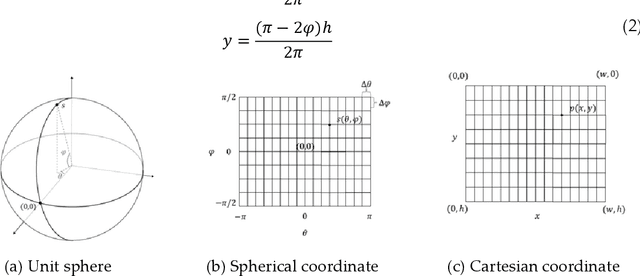
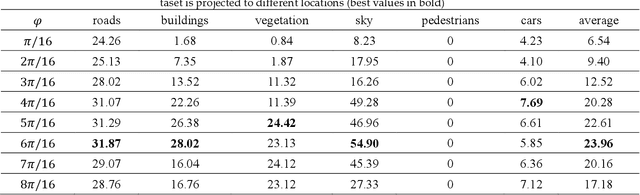
360{\deg} spherical images have advantages of wide view field, and are typically projected on a planar plane for processing, which is known as equirectangular image. The object shape in equirectangular images can be distorted and lack translation invariance. In addition, there are few publicly dataset of equirectangular images with labels, which presents a challenge for standard CNNs models to process equirectangular images effectively. To tackle this problem, we propose a methodology for converting a perspective image into equirectangular image. The inverse transformation of the spherical center projection and the equidistant cylindrical projection are employed. This enables the standard CNNs to learn the distortion features at different positions in the equirectangular image and thereby gain the ability to semantically the equirectangular image. The parameter, {\phi}, which determines the projection position of the perspective image, has been analyzed using various datasets and models, such as UNet, UNet++, SegNet, PSPNet, and DeepLab v3+. The experiments demonstrate that an optimal value of {\phi} for effective semantic segmentation of equirectangular images is 6{\pi}/16 for standard CNNs. Compared with the other three types of methods (supervised learning, unsupervised learning and data augmentation), the method proposed in this paper has the best average IoU value of 43.76%. This value is 23.85%, 10.7% and 17.23% higher than those of other three methods, respectively.
HUGE2: a Highly Untangled Generative-model Engine for Edge-computing
Jul 25, 2019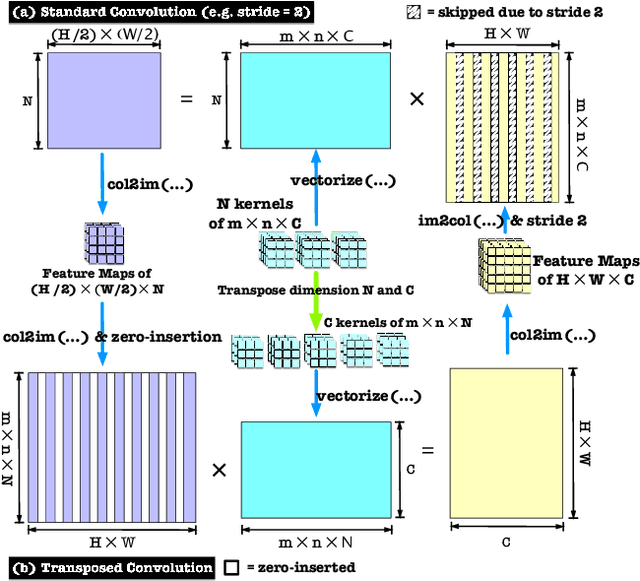
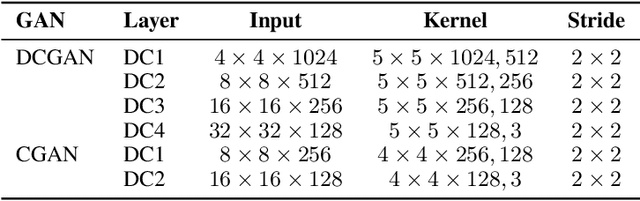

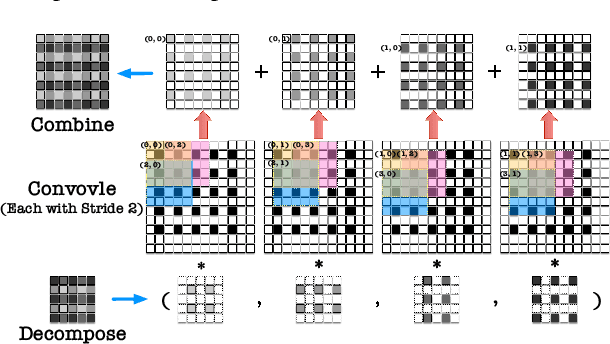
As a type of prominent studies in deep learning, generative models have been widely investigated in research recently. Two research branches of the deep learning models, the Generative Networks (GANs, VAE) and the Semantic Segmentation, rely highly on the upsampling operations, especially the transposed convolution and the dilated convolution. However, these two types of convolutions are intrinsically different from standard convolution regarding the insertion of zeros in input feature maps or in kernels respectively. This distinct nature severely degrades the performance of the existing deep learning engine or frameworks, such as Darknet, Tensorflow, and PyTorch, which are mainly developed for the standard convolution. Another trend in deep learning realm is to deploy the model onto edge/ embedded devices, in which the memory resource is scarce. In this work, we propose a Highly Untangled Generative-model Engine for Edge-computing or HUGE2 for accelerating these two special convolutions on the edge-computing platform by decomposing the kernels and untangling these smaller convolutions by performing basic matrix multiplications. The methods we propose use much smaller memory footprint, hence much fewer memory accesses, and the data access patterns also dramatically increase the reusability of the data already fetched in caches, hence increasing the localities of caches. Our engine achieves a speedup of nearly 5x on embedded CPUs, and around 10x on embedded GPUs, and more than 50% reduction of memory access.