 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Job Shop Scheduling Under Structural Uncertainty
Jan 29, 2026The Job-Shop Scheduling Problem (JSSP), under various forms of manufacturing uncertainty, has recently attracted considerable research attention. Most existing studies focus on parameter uncertainty, such as variable processing times, and typically adopt the actor-critic framework. In this paper, we explore a different but prevalent form of uncertainty in JSSP: structural uncertainty. Structural uncertainty arises when a job may follow one of several routing paths, and the selection is determined not by policy, but by situational factors (e.g., the quality of intermediate products) that cannot be known in advance. Existing methods struggle to address this challenge due to incorrect credit assignment: a high-quality action may be unfairly penalized if it is followed by a time-consuming path. To address this problem, we propose a novel method named UP-AAC. In contrast to conventional actor-critic methods, UP-AAC employs an asymmetric architecture. While its actor receives a standard stochastic state, the critic is crucially provided with a deterministic state reconstructed in hindsight. This design allows the critic to learn a more accurate value function, which in turn provides a lower-variance policy gradient to the actor, leading to more stable learning. In addition, we design an attention-based Uncertainty Perception Model (UPM) to enhance the actor's scheduling decisions. Extensive experiments demonstrate that our method outperforms existing approaches in reducing makespan on benchmark instances.
Enhancing Visual Representation with Textual Semantics: Textual Semantics-Powered Prototypes for Heterogeneous Federated Learning
Mar 16, 2025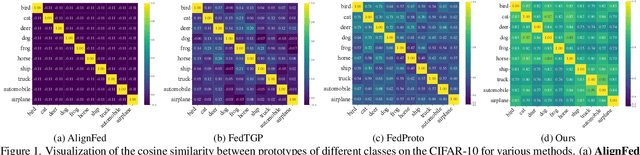
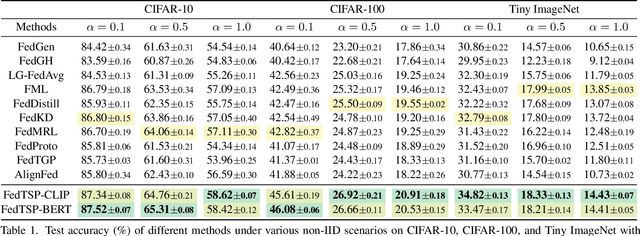
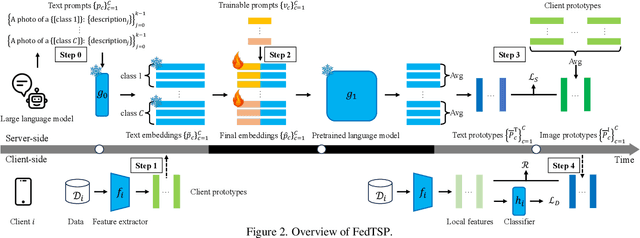
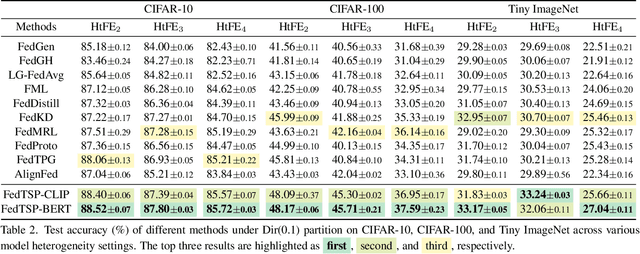
Federated Prototype Learning (FedPL) has emerged as an effective strategy for handling data heterogeneity in Federated Learning (FL). In FedPL, clients collaboratively construct a set of global feature centers (prototypes), and let local features align with these prototypes to mitigate the effects of data heterogeneity. The performance of FedPL highly depends on the quality of prototypes. Existing methods assume that larger inter-class distances among prototypes yield better performance, and thus design different methods to increase these distances. However, we observe that while these methods increase prototype distances to enhance class discrimination, they inevitably disrupt essential semantic relationships among classes, which are crucial for model generalization. This raises an important question: how to construct prototypes that inherently preserve semantic relationships among classes? Directly learning these relationships from limited and heterogeneous client data can be problematic in FL. Recently, the success of pre-trained language models (PLMs) demonstrates their ability to capture semantic relationships from vast textual corpora. Motivated by this, we propose FedTSP, a novel method that leverages PLMs to construct semantically enriched prototypes from the textual modality, enabling more effective collaboration in heterogeneous data settings. We first use a large language model (LLM) to generate fine-grained textual descriptions for each class, which are then processed by a PLM on the server to form textual prototypes. To address the modality gap between client image models and the PLM, we introduce trainable prompts, allowing prototypes to adapt better to client tasks. Extensive experiments demonstrate that FedTSP mitigates data heterogeneity while significantly accelerating convergence.
The Other Side of the Coin: Unveiling the Downsides of Model Aggregation in Federated Learning from a Layer-peeled Perspective
Feb 05, 2025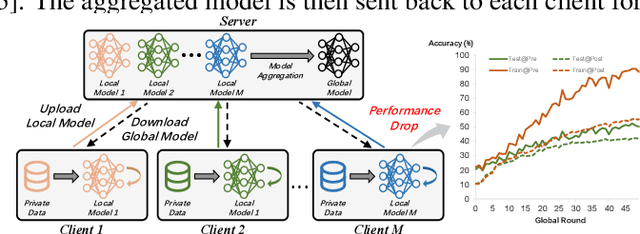
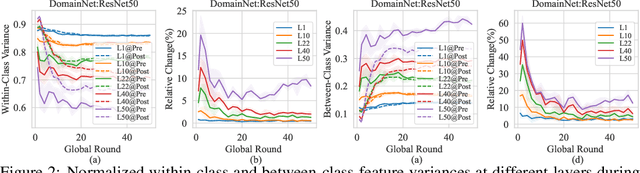
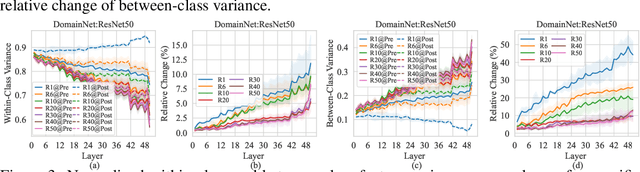
In federated learning (FL), model aggregation is a critical step by which multiple clients share their knowledge with one another. However, it is also widely recognized that the aggregated model, when sent back to each client, performs poorly on local data until after several rounds of local training. This temporary performance drop can potentially slow down the convergence of the FL model. Most research in FL regards this performance drop as an inherent cost of knowledge sharing among clients and does not give it special attention. While some studies directly focus on designing techniques to alleviate the issue, an in-depth investigation of the reasons behind this performance drop has yet to be conducted.To address this gap, we conduct a layer-peeled analysis of model aggregation across various datasets and model architectures. Our findings reveal that the performance drop can be attributed to two major consequences of the aggregation process: (1) it disrupts feature variability suppression in deep neural networks (DNNs), and (2) it weakens the coupling between features and subsequent parameters.Based on these findings, we propose several simple yet effective strategies to mitigate the negative impacts of model aggregation while still enjoying the benefit it brings. To the best of our knowledge, our work is the first to conduct a layer-peeled analysis of model aggregation, potentially paving the way for the development of more effective FL algorithms.
Breaking the Stage Barrier: A Novel Single-Stage Approach to Long Context Extension for Large Language Models
Dec 10, 2024Recently, Large language models (LLMs) have revolutionized Natural Language Processing (NLP). Pretrained LLMs, due to limited training context size, struggle with handling long token sequences, limiting their performance on various downstream tasks. Current solutions toward long context modeling often employ multi-stage continual pertaining, which progressively increases the effective context length through several continual pretraining stages. However, those approaches require extensive manual tuning and human expertise. In this paper, we introduce a novel single-stage continual pretraining method, Head-Adaptive Rotary Position Encoding (HARPE), to equip LLMs with long context modeling capabilities while simplifying the training process. Our HARPE leverages different Rotary Position Encoding (RoPE) base frequency values across different attention heads and directly trains LLMs on the target context length. Extensive experiments on 4 language modeling benchmarks, including the latest RULER benchmark, demonstrate that HARPE excels in understanding and integrating long-context tasks with single-stage training, matching and even outperforming existing multi-stage methods. Our results highlight that HARPE successfully breaks the stage barrier for training LLMs with long context modeling capabilities.
LBPE: Long-token-first Tokenization to Improve Large Language Models
Nov 08, 2024



The prevalent use of Byte Pair Encoding (BPE) in Large Language Models (LLMs) facilitates robust handling of subword units and avoids issues of out-of-vocabulary words. Despite its success, a critical challenge persists: long tokens, rich in semantic information, have fewer occurrences in tokenized datasets compared to short tokens, which can result in imbalanced learning issue across different tokens. To address that, we propose LBPE, which prioritizes long tokens during the encoding process. LBPE generates tokens according to their reverse ranks of token length rather than their ranks in the vocabulary, granting longer tokens higher priority during the encoding process. Consequently, LBPE smooths the frequency differences between short and long tokens, and thus mitigates the learning imbalance. Extensive experiments across diverse language modeling tasks demonstrate that LBPE consistently outperforms the original BPE, well demonstrating its effectiveness.
Why Go Full? Elevating Federated Learning Through Partial Network Updates
Oct 15, 2024



Federated learning is a distributed machine learning paradigm designed to protect user data privacy, which has been successfully implemented across various scenarios. In traditional federated learning, the entire parameter set of local models is updated and averaged in each training round. Although this full network update method maximizes knowledge acquisition and sharing for each model layer, it prevents the layers of the global model from cooperating effectively to complete the tasks of each client, a challenge we refer to as layer mismatch. This mismatch problem recurs after every parameter averaging, consequently slowing down model convergence and degrading overall performance. To address the layer mismatch issue, we introduce the FedPart method, which restricts model updates to either a single layer or a few layers during each communication round. Furthermore, to maintain the efficiency of knowledge acquisition and sharing, we develop several strategies to select trainable layers in each round, including sequential updating and multi-round cycle training. Through both theoretical analysis and experiments, our findings demonstrate that the FedPart method significantly surpasses conventional full network update strategies in terms of convergence speed and accuracy, while also reducing communication and computational overheads.
GLC-SLAM: Gaussian Splatting SLAM with Efficient Loop Closure
Sep 17, 2024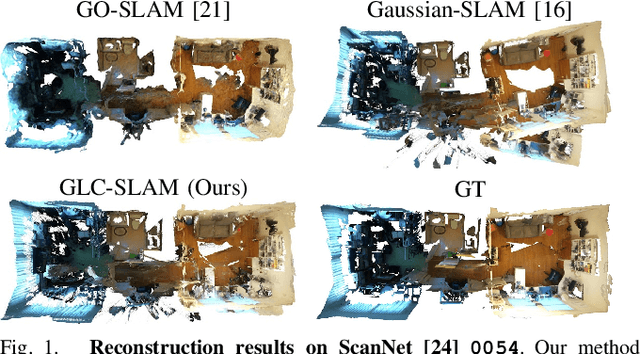
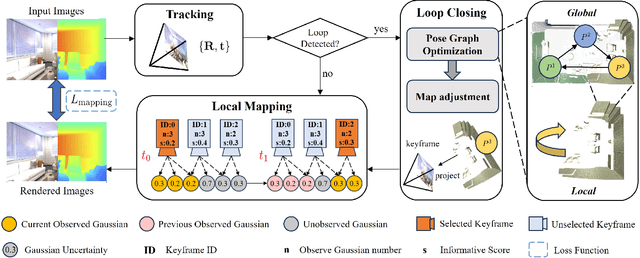

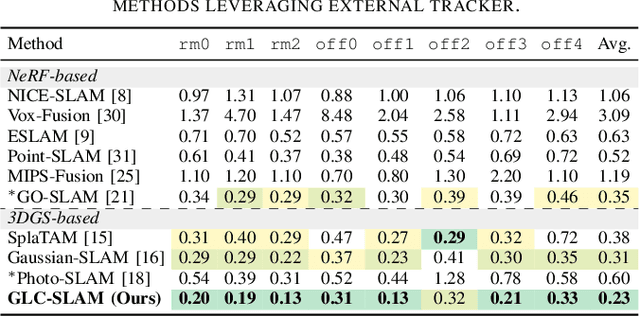
3D Gaussian Splatting (3DGS) has gained significant attention for its application in dense Simultaneous Localization and Mapping (SLAM), enabling real-time rendering and high-fidelity mapping. However, existing 3DGS-based SLAM methods often suffer from accumulated tracking errors and map drift, particularly in large-scale environments. To address these issues, we introduce GLC-SLAM, a Gaussian Splatting SLAM system that integrates global optimization of camera poses and scene models. Our approach employs frame-to-model tracking and triggers hierarchical loop closure using a global-to-local strategy to minimize drift accumulation. By dividing the scene into 3D Gaussian submaps, we facilitate efficient map updates following loop corrections in large scenes. Additionally, our uncertainty-minimized keyframe selection strategy prioritizes keyframes observing more valuable 3D Gaussians to enhance submap optimization. Experimental results on various datasets demonstrate that GLC-SLAM achieves superior or competitive tracking and mapping performance compared to state-of-the-art dense RGB-D SLAM systems.
GuidedNet: Semi-Supervised Multi-Organ Segmentation via Labeled Data Guide Unlabeled Data
Aug 09, 2024Semi-supervised multi-organ medical image segmentation aids physicians in improving disease diagnosis and treatment planning and reduces the time and effort required for organ annotation.Existing state-of-the-art methods train the labeled data with ground truths and train the unlabeled data with pseudo-labels. However, the two training flows are separate, which does not reflect the interrelationship between labeled and unlabeled data.To address this issue, we propose a semi-supervised multi-organ segmentation method called GuidedNet, which leverages the knowledge from labeled data to guide the training of unlabeled data. The primary goals of this study are to improve the quality of pseudo-labels for unlabeled data and to enhance the network's learning capability for both small and complex organs.A key concept is that voxel features from labeled and unlabeled data that are close to each other in the feature space are more likely to belong to the same class.On this basis, a 3D Consistent Gaussian Mixture Model (3D-CGMM) is designed to leverage the feature distributions from labeled data to rectify the generated pseudo-labels.Furthermore, we introduce a Knowledge Transfer Cross Pseudo Supervision (KT-CPS) strategy, which leverages the prior knowledge obtained from the labeled data to guide the training of the unlabeled data, thereby improving the segmentation accuracy for both small and complex organs. Extensive experiments on two public datasets, FLARE22 and AMOS, demonstrated that GuidedNet is capable of achieving state-of-the-art performance.
DualFed: Enjoying both Generalization and Personalization in Federated Learning via Hierachical Representations
Jul 25, 2024



In personalized federated learning (PFL), it is widely recognized that achieving both high model generalization and effective personalization poses a significant challenge due to their conflicting nature. As a result, existing PFL methods can only manage a trade-off between these two objectives. This raises an interesting question: Is it feasible to develop a model capable of achieving both objectives simultaneously? Our paper presents an affirmative answer, and the key lies in the observation that deep models inherently exhibit hierarchical architectures, which produce representations with various levels of generalization and personalization at different stages. A straightforward approach stemming from this observation is to select multiple representations from these layers and combine them to concurrently achieve generalization and personalization. However, the number of candidate representations is commonly huge, which makes this method infeasible due to high computational costs.To address this problem, we propose DualFed, a new method that can directly yield dual representations correspond to generalization and personalization respectively, thereby simplifying the optimization task. Specifically, DualFed inserts a personalized projection network between the encoder and classifier. The pre-projection representations are able to capture generalized information shareable across clients, and the post-projection representations are effective to capture task-specific information on local clients. This design minimizes the mutual interference between generalization and personalization, thereby achieving a win-win situation. Extensive experiments show that DualFed can outperform other FL methods. Code is available at https://github.com/GuogangZhu/DualFed.
Tackling Feature-Classifier Mismatch in Federated Learning via Prompt-Driven Feature Transformation
Jul 23, 2024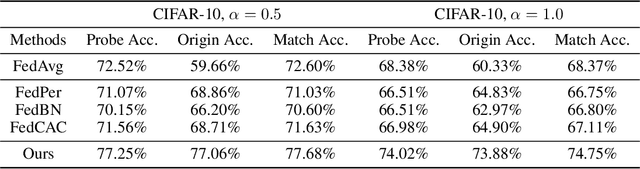
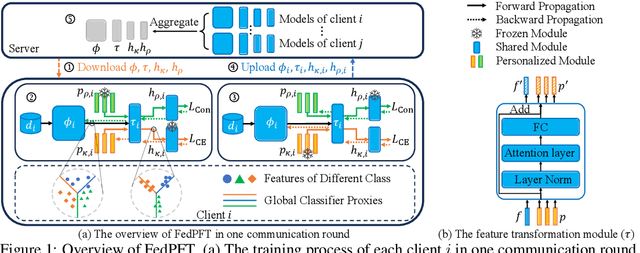
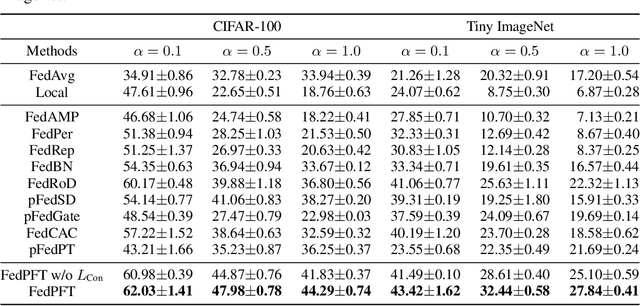
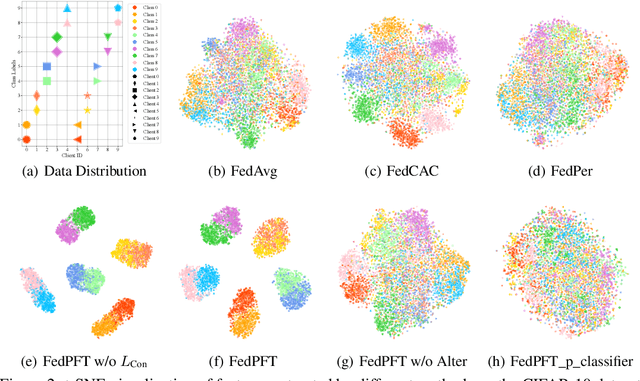
In traditional Federated Learning approaches like FedAvg, the global model underperforms when faced with data heterogeneity. Personalized Federated Learning (PFL) enables clients to train personalized models to fit their local data distribution better. However, we surprisingly find that the feature extractor in FedAvg is superior to those in most PFL methods. More interestingly, by applying a linear transformation on local features extracted by the feature extractor to align with the classifier, FedAvg can surpass the majority of PFL methods. This suggests that the primary cause of FedAvg's inadequate performance stems from the mismatch between the locally extracted features and the classifier. While current PFL methods mitigate this issue to some extent, their designs compromise the quality of the feature extractor, thus limiting the full potential of PFL. In this paper, we propose a new PFL framework called FedPFT to address the mismatch problem while enhancing the quality of the feature extractor. FedPFT integrates a feature transformation module, driven by personalized prompts, between the global feature extractor and classifier. In each round, clients first train prompts to transform local features to match the global classifier, followed by training model parameters. This approach can also align the training objectives of clients, reducing the impact of data heterogeneity on model collaboration. Moreover, FedPFT's feature transformation module is highly scalable, allowing for the use of different prompts to tailor local features to various tasks. Leveraging this, we introduce a collaborative contrastive learning task to further refine feature extractor quality. Our experiments demonstrate that FedPFT outperforms state-of-the-art methods by up to 7.08%.