 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAPO: Information-Aware Policy Optimization for Token-Efficient Reasoning
Feb 22, 2026Large language models increasingly rely on long chains of thought to improve accuracy, yet such gains come with substantial inference-time costs. We revisit token-efficient post-training and argue that existing sequence-level reward-shaping methods offer limited control over how reasoning effort is allocated across tokens. To bridge the gap, we propose IAPO, an information-theoretic post-training framework that assigns token-wise advantages based on each token's conditional mutual information (MI) with the final answer. This yields an explicit, principled mechanism for identifying informative reasoning steps and suppressing low-utility exploration. We provide a theoretical analysis showing that our IAPO can induce monotonic reductions in reasoning verbosity without harming correctness. Empirically, IAPO consistently improves reasoning accuracy while reducing reasoning length by up to 36%, outperforming existing token-efficient RL methods across various reasoning datasets. Extensive empirical evaluations demonstrate that information-aware advantage shaping is a powerful and general direction for token-efficient post-training. The code is available at https://github.com/YinhanHe123/IAPO.
Saliency-Aware Multi-Route Thinking: Revisiting Vision-Language Reasoning
Feb 18, 2026Vision-language models (VLMs) aim to reason by jointly leveraging visual and textual modalities. While allocating additional inference-time computation has proven effective for large language models (LLMs), achieving similar scaling in VLMs remains challenging. A key obstacle is that visual inputs are typically provided only once at the start of generation, while textual reasoning (e.g., early visual summaries) is generated autoregressively, causing reasoning to become increasingly text-dominated and allowing early visual grounding errors to accumulate. Moreover, vanilla guidance for visual grounding during inference is often coarse and noisy, making it difficult to steer reasoning over long texts. To address these challenges, we propose \emph{Saliency-Aware Principle} (SAP) selection. SAP operates on high-level reasoning principles rather than token-level trajectories, which enable stable control over discrete generation under noisy feedback while allowing later reasoning steps to re-consult visual evidence when renewed grounding is required. In addition, SAP supports multi-route inference, enabling parallel exploration of diverse reasoning behaviors. SAP is model-agnostic and data-free, requiring no additional training. Empirical results show that SAP achieves competitive performance, especially in reducing object hallucination, under comparable token-generation budgets while yielding more stable reasoning and lower response latency than CoT-style long sequential reasoning.
REPA Works Until It Doesn't: Early-Stopped, Holistic Alignment Supercharges Diffusion Training
May 22, 2025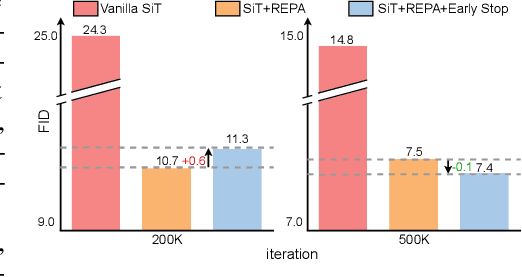
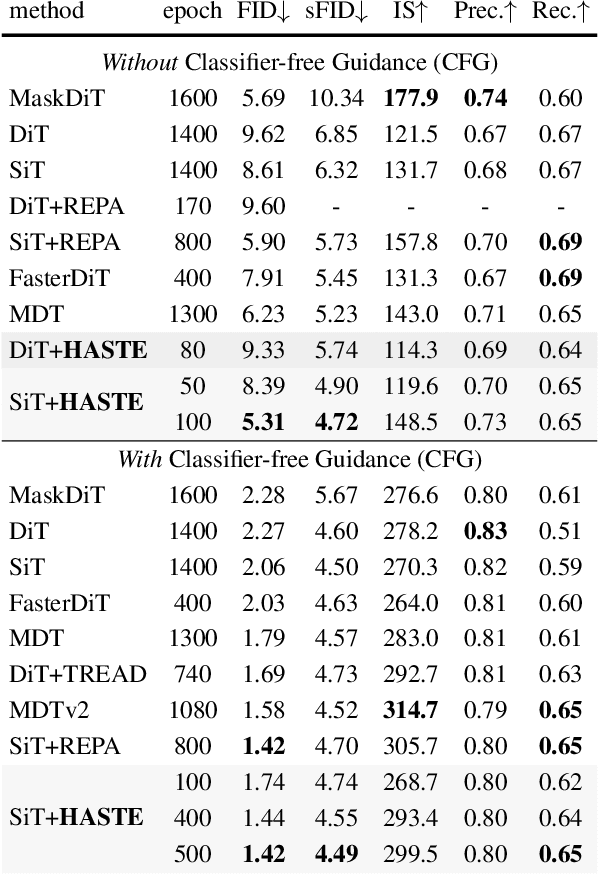

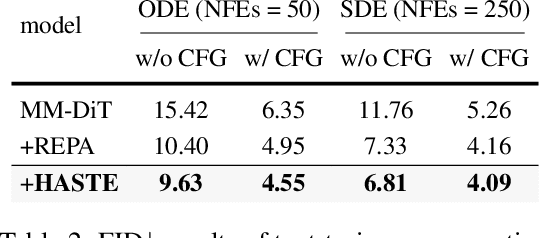
Diffusion Transformers (DiTs) deliver state-of-the-art image quality, yet their training remains notoriously slow. A recent remedy -- representation alignment (REPA) that matches DiT hidden features to those of a non-generative teacher (e.g. DINO) -- dramatically accelerates the early epochs but plateaus or even degrades performance later. We trace this failure to a capacity mismatch: once the generative student begins modelling the joint data distribution, the teacher's lower-dimensional embeddings and attention patterns become a straitjacket rather than a guide. We then introduce HASTE (Holistic Alignment with Stage-wise Termination for Efficient training), a two-phase schedule that keeps the help and drops the hindrance. Phase I applies a holistic alignment loss that simultaneously distills attention maps (relational priors) and feature projections (semantic anchors) from the teacher into mid-level layers of the DiT, yielding rapid convergence. Phase II then performs one-shot termination that deactivates the alignment loss, once a simple trigger such as a fixed iteration is hit, freeing the DiT to focus on denoising and exploit its generative capacity. HASTE speeds up training of diverse DiTs without architecture changes. On ImageNet 256X256, it reaches the vanilla SiT-XL/2 baseline FID in 50 epochs and matches REPA's best FID in 500 epochs, amounting to a 28X reduction in optimization steps. HASTE also improves text-to-image DiTs on MS-COCO, demonstrating to be a simple yet principled recipe for efficient diffusion training across various tasks. Our code is available at https://github.com/NUS-HPC-AI-Lab/HASTE .
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Ferret: An Efficient Online Continual Learning Framework under Varying Memory Constraints
Mar 15, 2025In the realm of high-frequency data streams, achieving real-time learning within varying memory constraints is paramount. This paper presents Ferret, a comprehensive framework designed to enhance online accuracy of Online Continual Learning (OCL) algorithms while dynamically adapting to varying memory budgets. Ferret employs a fine-grained pipeline parallelism strategy combined with an iterative gradient compensation algorithm, ensuring seamless handling of high-frequency data with minimal latency, and effectively counteracting the challenge of stale gradients in parallel training. To adapt to varying memory budgets, its automated model partitioning and pipeline planning optimizes performance regardless of memory limitations. Extensive experiments across 20 benchmarks and 5 integrated OCL algorithms show Ferret's remarkable efficiency, achieving up to 3.7$\times$ lower memory overhead to reach the same online accuracy compared to competing methods. Furthermore, Ferret consistently outperforms these methods across diverse memory budgets, underscoring its superior adaptability. These findings position Ferret as a premier solution for efficient and adaptive OCL framework in real-time environments.
Make Optimization Once and for All with Fine-grained Guidance
Mar 14, 2025Learning to Optimize (L2O) enhances optimization efficiency with integrated neural networks. L2O paradigms achieve great outcomes, e.g., refitting optimizer, generating unseen solutions iteratively or directly. However, conventional L2O methods require intricate design and rely on specific optimization processes, limiting scalability and generalization. Our analyses explore general framework for learning optimization, called Diff-L2O, focusing on augmenting sampled solutions from a wider view rather than local updates in real optimization process only. Meanwhile, we give the related generalization bound, showing that the sample diversity of Diff-L2O brings better performance. This bound can be simply applied to other fields, discussing diversity, mean-variance, and different tasks. Diff-L2O's strong compatibility is empirically verified with only minute-level training, comparing with other hour-levels.
GSQ-Tuning: Group-Shared Exponents Integer in Fully Quantized Training for LLMs On-Device Fine-tuning
Feb 18, 2025



Large Language Models (LLMs) fine-tuning technologies have achieved remarkable results. However, traditional LLM fine-tuning approaches face significant challenges: they require large Floating Point (FP) computation, raising privacy concerns when handling sensitive data, and are impractical for resource-constrained edge devices. While Parameter-Efficient Fine-Tuning (PEFT) techniques reduce trainable parameters, their reliance on floating-point arithmetic creates fundamental incompatibilities with edge hardware. In this work, we introduce a novel framework for on-device LLM fine-tuning that eliminates the need for floating-point operations in both inference and training, named GSQ-Tuning. At its core is the Group-Shared Exponents Integer format, which efficiently represents model parameters in integer format using shared exponents among parameter groups. When combined with LoRA-like adapters, this enables fully integer-based fine-tuning that is both memory and compute efficient. We demonstrate that our approach achieves accuracy comparable to FP16-based fine-tuning while significantly reducing memory usage (50%). Moreover, compared to FP8, our method can reduce 5x power consumption and 11x chip area with same performance, making large-scale model adaptation feasible on edge devices.
E-3SFC: Communication-Efficient Federated Learning with Double-way Features Synthesizing
Feb 05, 2025The exponential growth in model sizes has significantly increased the communication burden in Federated Learning (FL). Existing methods to alleviate this burden by transmitting compressed gradients often face high compression errors, which slow down the model's convergence. To simultaneously achieve high compression effectiveness and lower compression errors, we study the gradient compression problem from a novel perspective. Specifically, we propose a systematical algorithm termed Extended Single-Step Synthetic Features Compressing (E-3SFC), which consists of three sub-components, i.e., the Single-Step Synthetic Features Compressor (3SFC), a double-way compression algorithm, and a communication budget scheduler. First, we regard the process of gradient computation of a model as decompressing gradients from corresponding inputs, while the inverse process is considered as compressing the gradients. Based on this, we introduce a novel gradient compression method termed 3SFC, which utilizes the model itself as a decompressor, leveraging training priors such as model weights and objective functions. 3SFC compresses raw gradients into tiny synthetic features in a single-step simulation, incorporating error feedback to minimize overall compression errors. To further reduce communication overhead, 3SFC is extended to E-3SFC, allowing double-way compression and dynamic communication budget scheduling. Our theoretical analysis under both strongly convex and non-convex conditions demonstrates that 3SFC achieves linear and sub-linear convergence rates with aggregation noise. Extensive experiments across six datasets and six models reveal that 3SFC outperforms state-of-the-art methods by up to 13.4% while reducing communication costs by 111.6 times. These findings suggest that 3SFC can significantly enhance communication efficiency in FL without compromising model performance.
Faster Vision Mamba is Rebuilt in Minutes via Merged Token Re-training
Dec 17, 2024



Vision Mamba (e.g., Vim) has successfully been integrated into computer vision, and token reduction has yielded promising outcomes in Vision Transformers (ViTs). However, token reduction performs less effectively on Vision Mamba compared to ViTs. Pruning informative tokens in Mamba leads to a high loss of key knowledge and bad performance. This makes it not a good solution for enhancing efficiency in Mamba. Token merging, which preserves more token information than pruning, has demonstrated commendable performance in ViTs. Nevertheless, vanilla merging performance decreases as the reduction ratio increases either, failing to maintain the key knowledge in Mamba. Re-training the token-reduced model enhances the performance of Mamba, by effectively rebuilding the key knowledge. Empirically, pruned Vims only drop up to 0.9% accuracy on ImageNet-1K, recovered by our proposed framework R-MeeTo in our main evaluation. We show how simple and effective the fast recovery can be achieved at minute-level, in particular, a 35.9% accuracy spike over 3 epochs of training on Vim-Ti. Moreover, Vim-Ti/S/B are re-trained within 5/7/17 minutes, and Vim-S only drop 1.3% with 1.2x (up to 1.5x) speed up in inference.
Tackling Feature-Classifier Mismatch in Federated Learning via Prompt-Driven Feature Transformation
Jul 23, 2024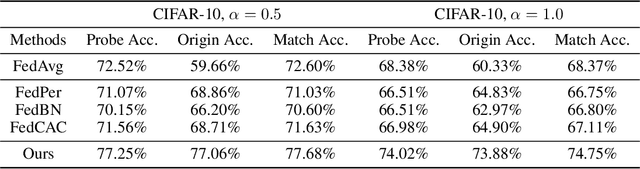
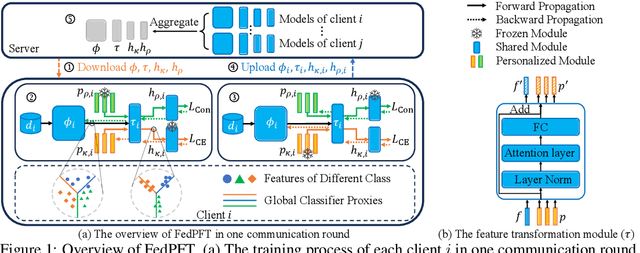
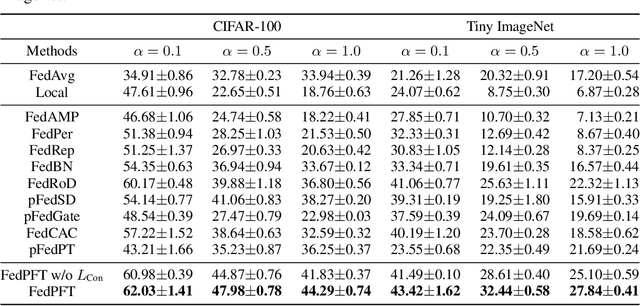
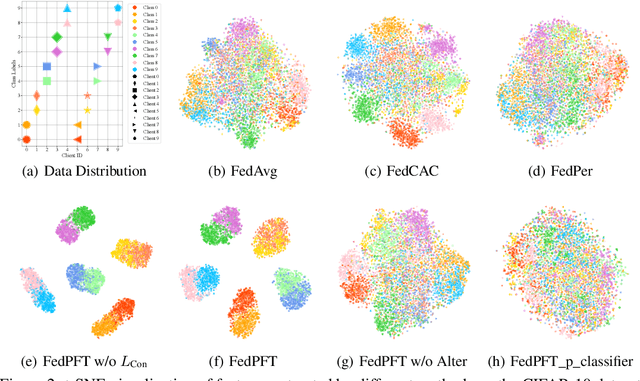
In traditional Federated Learning approaches like FedAvg, the global model underperforms when faced with data heterogeneity. Personalized Federated Learning (PFL) enables clients to train personalized models to fit their local data distribution better. However, we surprisingly find that the feature extractor in FedAvg is superior to those in most PFL methods. More interestingly, by applying a linear transformation on local features extracted by the feature extractor to align with the classifier, FedAvg can surpass the majority of PFL methods. This suggests that the primary cause of FedAvg's inadequate performance stems from the mismatch between the locally extracted features and the classifier. While current PFL methods mitigate this issue to some extent, their designs compromise the quality of the feature extractor, thus limiting the full potential of PFL. In this paper, we propose a new PFL framework called FedPFT to address the mismatch problem while enhancing the quality of the feature extractor. FedPFT integrates a feature transformation module, driven by personalized prompts, between the global feature extractor and classifier. In each round, clients first train prompts to transform local features to match the global classifier, followed by training model parameters. This approach can also align the training objectives of clients, reducing the impact of data heterogeneity on model collaboration. Moreover, FedPFT's feature transformation module is highly scalable, allowing for the use of different prompts to tailor local features to various tasks. Leveraging this, we introduce a collaborative contrastive learning task to further refine feature extractor quality. Our experiments demonstrate that FedPFT outperforms state-of-the-art methods by up to 7.08%.