 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircular Reasoning: Understanding Self-Reinforcing Loops in Large Reasoning Models
Jan 09, 2026Despite the success of test-time scaling, Large Reasoning Models (LRMs) frequently encounter repetitive loops that lead to computational waste and inference failure. In this paper, we identify a distinct failure mode termed Circular Reasoning. Unlike traditional model degeneration, this phenomenon manifests as a self-reinforcing trap where generated content acts as a logical premise for its own recurrence, compelling the reiteration of preceding text. To systematically analyze this phenomenon, we introduce LoopBench, a dataset designed to capture two distinct loop typologies: numerical loops and statement loops. Mechanistically, we characterize circular reasoning as a state collapse exhibiting distinct boundaries, where semantic repetition precedes textual repetition. We reveal that reasoning impasses trigger the loop onset, which subsequently persists as an inescapable cycle driven by a self-reinforcing V-shaped attention mechanism. Guided by these findings, we employ the Cumulative Sum (CUSUM) algorithm to capture these precursors for early loop prediction. Experiments across diverse LRMs validate its accuracy and elucidate the stability of long-chain reasoning.
Deploying Models to Non-participating Clients in Federated Learning without Fine-tuning: A Hypernetwork-based Approach
Aug 18, 2025Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving collaborative learning, yet data heterogeneity remains a critical challenge. While existing methods achieve progress in addressing data heterogeneity for participating clients, they fail to generalize to non-participating clients with in-domain distribution shifts and resource constraints. To mitigate this issue, we present HyperFedZero, a novel method that dynamically generates specialized models via a hypernetwork conditioned on distribution-aware embeddings. Our approach explicitly incorporates distribution-aware inductive biases into the model's forward pass, extracting robust distribution embeddings using a NoisyEmbed-enhanced extractor with a Balancing Penalty, effectively preventing feature collapse. The hypernetwork then leverages these embeddings to generate specialized models chunk-by-chunk for non-participating clients, ensuring adaptability to their unique data distributions. Extensive experiments on multiple datasets and models demonstrate HyperFedZero's remarkable performance, surpassing competing methods consistently with minimal computational, storage, and communication overhead. Moreover, ablation studies and visualizations further validate the necessity of each component, confirming meaningful adaptations and validating the effectiveness of HyperFedZero.
GPS: Distilling Compact Memories via Grid-based Patch Sampling for Efficient Online Class-Incremental Learning
Apr 15, 2025Online class-incremental learning aims to enable models to continuously adapt to new classes with limited access to past data, while mitigating catastrophic forgetting. Replay-based methods address this by maintaining a small memory buffer of previous samples, achieving competitive performance. For effective replay under constrained storage, recent approaches leverage distilled data to enhance the informativeness of memory. However, such approaches often involve significant computational overhead due to the use of bi-level optimization. Motivated by these limitations, we introduce Grid-based Patch Sampling (GPS), a lightweight and effective strategy for distilling informative memory samples without relying on a trainable model. GPS generates informative samples by sampling a subset of pixels from the original image, yielding compact low-resolution representations that preserve both semantic content and structural information. During replay, these representations are reassembled to support training and evaluation. Experiments on extensive benchmarks demonstrate that GRS can be seamlessly integrated into existing replay frameworks, leading to 3%-4% improvements in average end accuracy under memory-constrained settings, with limited computational overhead.
Style Quantization for Data-Efficient GAN Training
Mar 31, 2025Under limited data setting, GANs often struggle to navigate and effectively exploit the input latent space. Consequently, images generated from adjacent variables in a sparse input latent space may exhibit significant discrepancies in realism, leading to suboptimal consistency regularization (CR) outcomes. To address this, we propose \textit{SQ-GAN}, a novel approach that enhances CR by introducing a style space quantization scheme. This method transforms the sparse, continuous input latent space into a compact, structured discrete proxy space, allowing each element to correspond to a specific real data point, thereby improving CR performance. Instead of direct quantization, we first map the input latent variables into a less entangled ``style'' space and apply quantization using a learnable codebook. This enables each quantized code to control distinct factors of variation. Additionally, we optimize the optimal transport distance to align the codebook codes with features extracted from the training data by a foundation model, embedding external knowledge into the codebook and establishing a semantically rich vocabulary that properly describes the training dataset. Extensive experiments demonstrate significant improvements in both discriminator robustness and generation quality with our method.
Ferret: An Efficient Online Continual Learning Framework under Varying Memory Constraints
Mar 15, 2025In the realm of high-frequency data streams, achieving real-time learning within varying memory constraints is paramount. This paper presents Ferret, a comprehensive framework designed to enhance online accuracy of Online Continual Learning (OCL) algorithms while dynamically adapting to varying memory budgets. Ferret employs a fine-grained pipeline parallelism strategy combined with an iterative gradient compensation algorithm, ensuring seamless handling of high-frequency data with minimal latency, and effectively counteracting the challenge of stale gradients in parallel training. To adapt to varying memory budgets, its automated model partitioning and pipeline planning optimizes performance regardless of memory limitations. Extensive experiments across 20 benchmarks and 5 integrated OCL algorithms show Ferret's remarkable efficiency, achieving up to 3.7$\times$ lower memory overhead to reach the same online accuracy compared to competing methods. Furthermore, Ferret consistently outperforms these methods across diverse memory budgets, underscoring its superior adaptability. These findings position Ferret as a premier solution for efficient and adaptive OCL framework in real-time environments.
E-3SFC: Communication-Efficient Federated Learning with Double-way Features Synthesizing
Feb 05, 2025The exponential growth in model sizes has significantly increased the communication burden in Federated Learning (FL). Existing methods to alleviate this burden by transmitting compressed gradients often face high compression errors, which slow down the model's convergence. To simultaneously achieve high compression effectiveness and lower compression errors, we study the gradient compression problem from a novel perspective. Specifically, we propose a systematical algorithm termed Extended Single-Step Synthetic Features Compressing (E-3SFC), which consists of three sub-components, i.e., the Single-Step Synthetic Features Compressor (3SFC), a double-way compression algorithm, and a communication budget scheduler. First, we regard the process of gradient computation of a model as decompressing gradients from corresponding inputs, while the inverse process is considered as compressing the gradients. Based on this, we introduce a novel gradient compression method termed 3SFC, which utilizes the model itself as a decompressor, leveraging training priors such as model weights and objective functions. 3SFC compresses raw gradients into tiny synthetic features in a single-step simulation, incorporating error feedback to minimize overall compression errors. To further reduce communication overhead, 3SFC is extended to E-3SFC, allowing double-way compression and dynamic communication budget scheduling. Our theoretical analysis under both strongly convex and non-convex conditions demonstrates that 3SFC achieves linear and sub-linear convergence rates with aggregation noise. Extensive experiments across six datasets and six models reveal that 3SFC outperforms state-of-the-art methods by up to 13.4% while reducing communication costs by 111.6 times. These findings suggest that 3SFC can significantly enhance communication efficiency in FL without compromising model performance.
Learning Locally, Revising Globally: Global Reviser for Federated Learning with Noisy Labels
Nov 30, 2024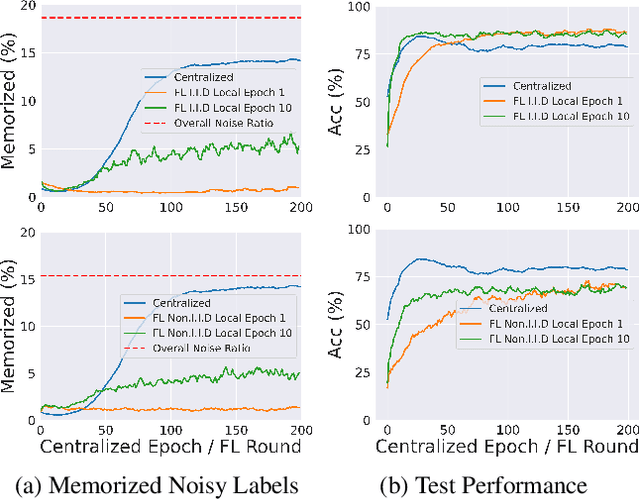
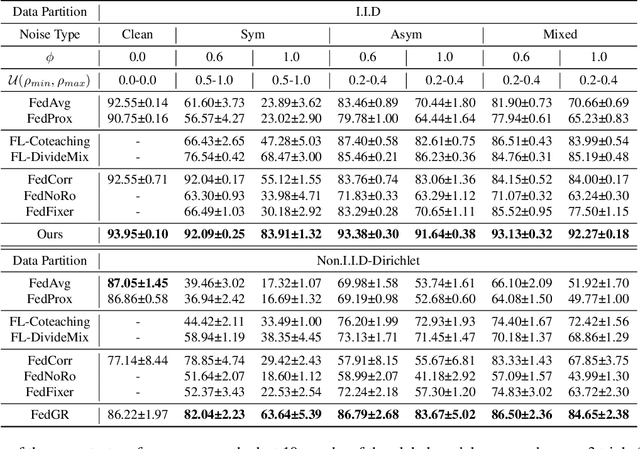
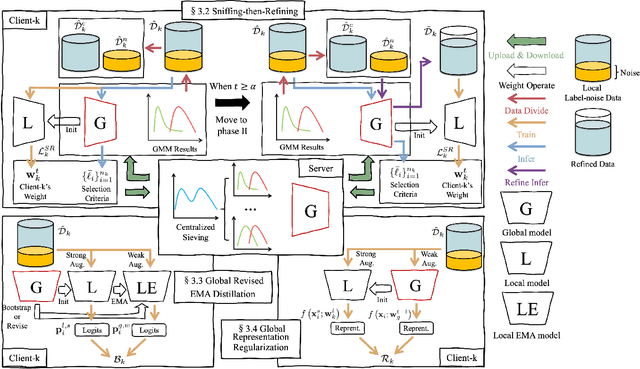
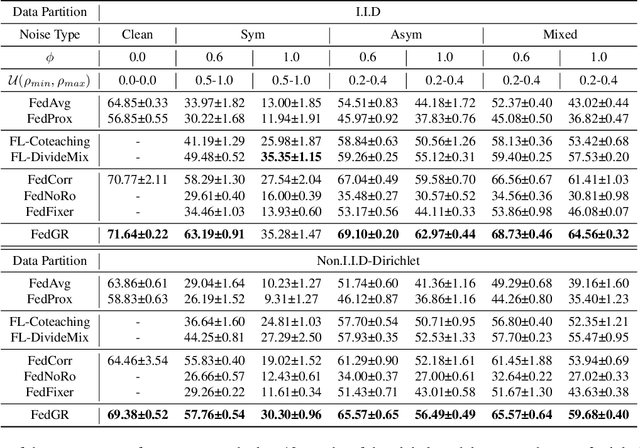
The success of most federated learning (FL) methods heavily depends on label quality, which is often inaccessible in real-world scenarios, such as medicine, leading to the federated label-noise (F-LN) problem. In this study, we observe that the global model of FL memorizes the noisy labels slowly. Based on the observations, we propose a novel approach dubbed Global Reviser for Federated Learning with Noisy Labels (FedGR) to enhance the label-noise robustness of FL. In brief, FedGR employs three novel modules to achieve noisy label sniffing and refining, local knowledge revising, and local model regularization. Specifically, the global model is adopted to infer local data proxies for global sample selection and refine incorrect labels. To maximize the utilization of local knowledge, we leverage the global model to revise the local exponential moving average (EMA) model of each client and distill it into the clients' models. Additionally, we introduce a global-to-local representation regularization to mitigate the overfitting of noisy labels. Extensive experiments on three F-LNL benchmarks against seven baseline methods demonstrate the effectiveness of the proposed FedGR.
MS$^3$D: A RG Flow-Based Regularization for GAN Training with Limited Data
Aug 20, 2024


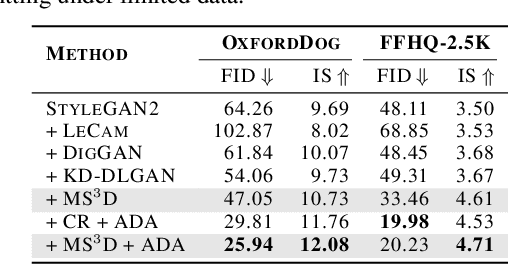
Generative adversarial networks (GANs) have made impressive advances in image generation, but they often require large-scale training data to avoid degradation caused by discriminator overfitting. To tackle this issue, we investigate the challenge of training GANs with limited data, and propose a novel regularization method based on the idea of renormalization group (RG) in physics.We observe that in the limited data setting, the gradient pattern that the generator obtains from the discriminator becomes more aggregated over time. In RG context, this aggregated pattern exhibits a high discrepancy from its coarse-grained versions, which implies a high-capacity and sensitive system, prone to overfitting and collapse. To address this problem, we introduce a \textbf{m}ulti-\textbf{s}cale \textbf{s}tructural \textbf{s}elf-\textbf{d}issimilarity (MS$^3$D) regularization, which constrains the gradient field to have a consistent pattern across different scales, thereby fostering a more redundant and robust system. We show that our method can effectively enhance the performance and stability of GANs under limited data scenarios, and even allow them to generate high-quality images with very few data.
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Mar 13, 2024Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
Federated cINN Clustering for Accurate Clustered Federated Learning
Sep 04, 2023Federated Learning (FL) presents an innovative approach to privacy-preserving distributed machine learning and enables efficient crowd intelligence on a large scale. However, a significant challenge arises when coordinating FL with crowd intelligence which diverse client groups possess disparate objectives due to data heterogeneity or distinct tasks. To address this challenge, we propose the Federated cINN Clustering Algorithm (FCCA) to robustly cluster clients into different groups, avoiding mutual interference between clients with data heterogeneity, and thereby enhancing the performance of the global model. Specifically, FCCA utilizes a global encoder to transform each client's private data into multivariate Gaussian distributions. It then employs a generative model to learn encoded latent features through maximum likelihood estimation, which eases optimization and avoids mode collapse. Finally, the central server collects converged local models to approximate similarities between clients and thus partition them into distinct clusters. Extensive experimental results demonstrate FCCA's superiority over other state-of-the-art clustered federated learning algorithms, evaluated on various models and datasets. These results suggest that our approach has substantial potential to enhance the efficiency and accuracy of real-world federated learning tasks.