 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speech Synthesis from MRI-Based Articulatory Representations
Jul 05, 2023
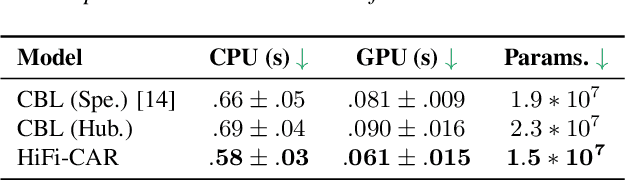
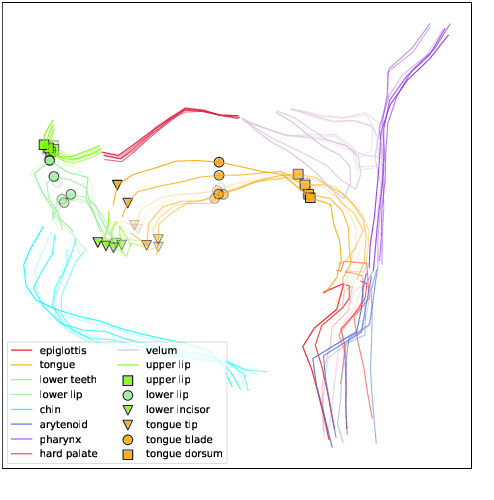
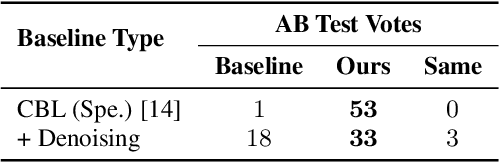
In this paper, we study articulatory synthesis, a speech synthesis method using human vocal tract information that offers a way to develop efficient, generalizable and interpretable synthesizers. While recent advances have enabled intelligible articulatory synthesis using electromagnetic articulography (EMA), these methods lack critical articulatory information like excitation and nasality, limiting generalization capabilities. To bridge this gap, we propose an alternative MRI-based feature set that covers a much more extensive articulatory space than EMA. We also introduce normalization and denoising procedures to enhance the generalizability of deep learning methods trained on MRI data. Moreover, we propose an MRI-to-speech model that improves both computational efficiency and speech fidelity. Finally, through a series of ablations, we show that the proposed MRI representation is more comprehensive than EMA and identify the most suitable MRI feature subset for articulatory synthesis.
TSGCNeXt: Dynamic-Static Multi-Graph Convolution for Efficient Skeleton-Based Action Recognition with Long-term Learning Potential
Apr 23, 2023



Skeleton-based action recognition has achieved remarkable results in human action recognition with the development of graph convolutional networks (GCNs). However, the recent works tend to construct complex learning mechanisms with redundant training and exist a bottleneck for long time-series. To solve these problems, we propose the Temporal-Spatio Graph ConvNeXt (TSGCNeXt) to explore efficient learning mechanism of long temporal skeleton sequences. Firstly, a new graph learning mechanism with simple structure, Dynamic-Static Separate Multi-graph Convolution (DS-SMG) is proposed to aggregate features of multiple independent topological graphs and avoid the node information being ignored during dynamic convolution. Next, we construct a graph convolution training acceleration mechanism to optimize the back-propagation computing of dynamic graph learning with 55.08\% speed-up. Finally, the TSGCNeXt restructure the overall structure of GCN with three Spatio-temporal learning modules,efficiently modeling long temporal features. In comparison with existing previous methods on large-scale datasets NTU RGB+D 60 and 120, TSGCNeXt outperforms on single-stream networks. In addition, with the ema model introduced into the multi-stream fusion, TSGCNeXt achieves SOTA levels. On the cross-subject and cross-set of the NTU 120, accuracies reach 90.22% and 91.74%.
Articulatory Representation Learning Via Joint Factor Analysis and Neural Matrix Factorization
Oct 29, 2022Articulatory representation learning is the fundamental research in modeling neural speech production system. Our previous work has established a deep paradigm to decompose the articulatory kinematics data into gestures, which explicitly model the phonological and linguistic structure encoded with human speech production mechanism, and corresponding gestural scores. We continue with this line of work by raising two concerns: (1) The articulators are entangled together in the original algorithm such that some of the articulators do not leverage effective moving patterns, which limits the interpretability of both gestures and gestural scores; (2) The EMA data is sparsely sampled from articulators, which limits the intelligibility of learned representations. In this work, we propose a novel articulatory representation decomposition algorithm that takes the advantage of guided factor analysis to derive the articulatory-specific factors and factor scores. A neural convolutive matrix factorization algorithm is then employed on the factor scores to derive the new gestures and gestural scores. We experiment with the rtMRI corpus that captures the fine-grained vocal tract contours. Both subjective and objective evaluation results suggest that the newly proposed system delivers the articulatory representations that are intelligible, generalizable, efficient and interpretable.