 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSylber 2.0: A Universal Syllable Embedding
Jan 29, 2026Scaling spoken language modeling requires speech tokens that are both efficient and universal. Recent work has proposed syllables as promising speech tokens at low temporal resolution, but existing models are constrained to English and fail to capture sufficient acoustic detail. To address this gap, we present Sylber 2.0, a self-supervised framework for coding speech at the syllable level that enables efficient temporal compression and high-fidelity reconstruction. Sylber 2.0 achieves a very low token frequency around 5 Hz, while retaining both linguistic and acoustic detail across multiple languages and expressive styles. Experiments show that it performs on par with previous models operating on high-frequency baselines. Furthermore, Sylber 2.0 enables efficient TTS modeling which can generate speech with competitive intelligibility and quality with SOTA models using only 72M parameters. Moreover, the universality of Sylber 2.0 provides more effective features for low resource ASR than previous speech coding frameworks. In sum, we establish an effective syllable-level abstraction for general spoken language.
Scaling Spoken Language Models with Syllabic Speech Tokenization
Sep 30, 2025Spoken language models (SLMs) typically discretize speech into high-frame-rate tokens extracted from SSL speech models. As the most successful LMs are based on the Transformer architecture, processing these long token streams with self-attention is expensive, as attention scales quadratically with sequence length. A recent SSL work introduces acoustic tokenization of speech at the syllable level, which is more interpretable and potentially more scalable with significant compression in token lengths (4-5 Hz). Yet, their value for spoken language modeling is not yet fully explored. We present the first systematic study of syllabic tokenization for spoken language modeling, evaluating models on a suite of SLU benchmarks while varying training data scale. Syllabic tokens can match or surpass the previous high-frame rate tokens while significantly cutting training and inference costs, achieving more than a 2x reduction in training time and a 5x reduction in FLOPs. Our findings highlight syllable-level language modeling as a promising path to efficient long-context spoken language models.
Deep Speech Synthesis from Multimodal Articulatory Representations
Dec 17, 2024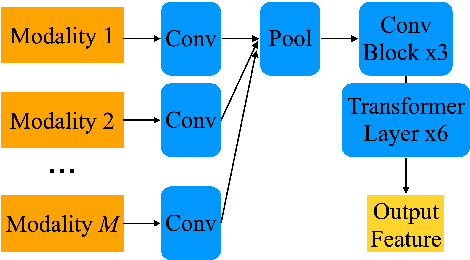
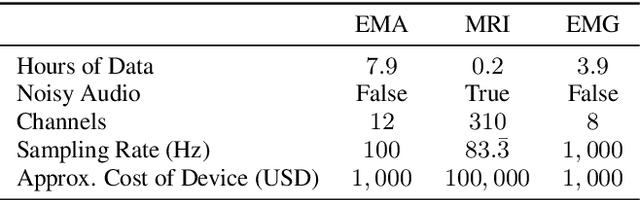
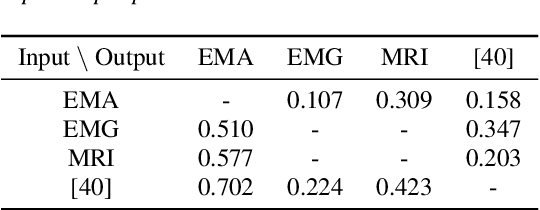

The amount of articulatory data available for training deep learning models is much less compared to acoustic speech data. In order to improve articulatory-to-acoustic synthesis performance in these low-resource settings, we propose a multimodal pre-training framework. On single-speaker speech synthesis tasks from real-time magnetic resonance imaging and surface electromyography inputs, the intelligibility of synthesized outputs improves noticeably. For example, compared to prior work, utilizing our proposed transfer learning methods improves the MRI-to-speech performance by 36% word error rate. In addition to these intelligibility results, our multimodal pre-trained models consistently outperform unimodal baselines on three objective and subjective synthesis quality metrics.
Sylber: Syllabic Embedding Representation of Speech from Raw Audio
Oct 09, 2024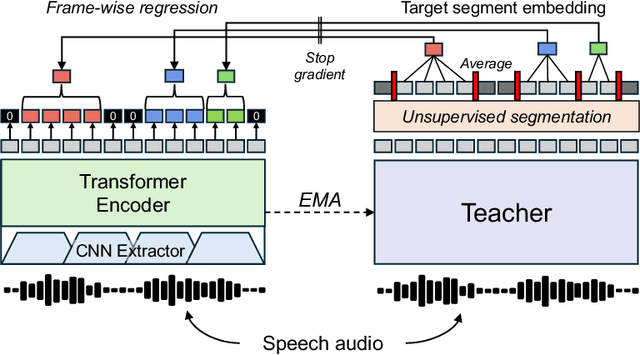
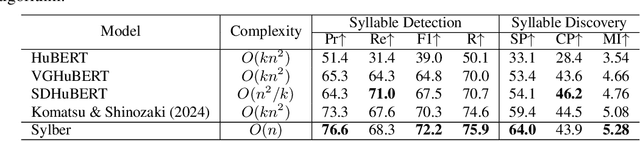
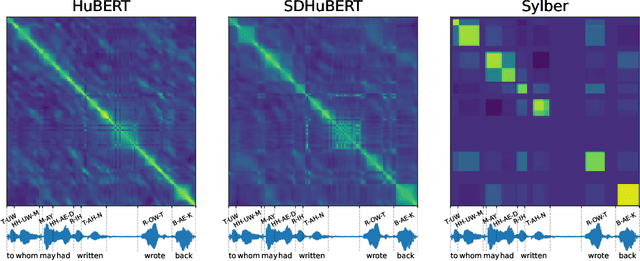
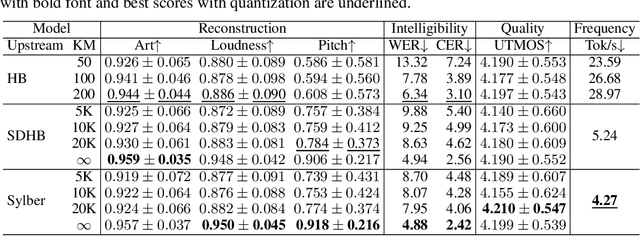
Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.
Articulatory Encodec: Vocal Tract Kinematics as a Codec for Speech
Jun 18, 2024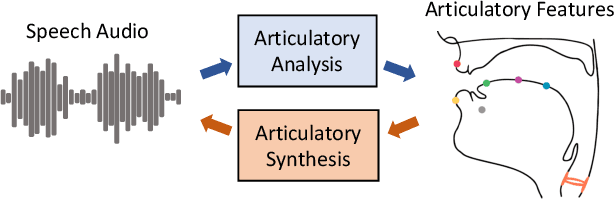
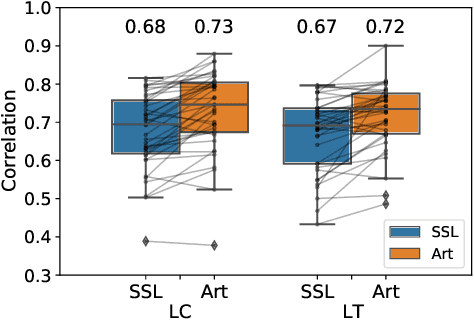
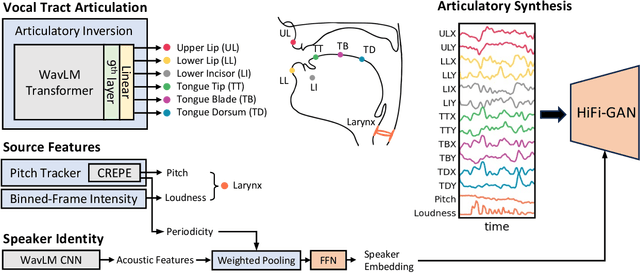

Vocal tract articulation is a natural, grounded control space of speech production. The spatiotemporal coordination of articulators combined with the vocal source shapes intelligible speech sounds to enable effective spoken communication. Based on this physiological grounding of speech, we propose a new framework of neural encoding-decoding of speech -- articulatory encodec. The articulatory encodec comprises an articulatory analysis model that infers articulatory features from speech audio, and an articulatory synthesis model that synthesizes speech audio from articulatory features. The articulatory features are kinematic traces of vocal tract articulators and source features, which are intuitively interpretable and controllable, being the actual physical interface of speech production. An additional speaker identity encoder is jointly trained with the articulatory synthesizer to inform the voice texture of individual speakers. By training on large-scale speech data, we achieve a fully intelligible, high-quality articulatory synthesizer that generalizes to unseen speakers. Furthermore, the speaker embedding is effectively disentangled from articulations, which enables accent-perserving zero-shot voice conversion. To the best of our knowledge, this is the first demonstration of universal, high-performance articulatory inference and synthesis, suggesting the proposed framework as a powerful coding system of speech.
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023
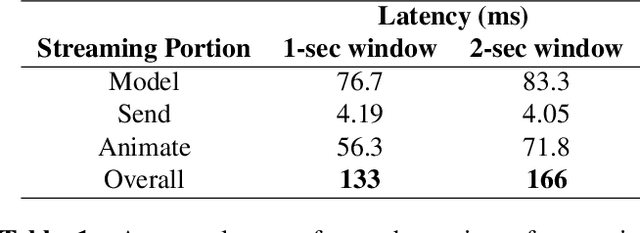
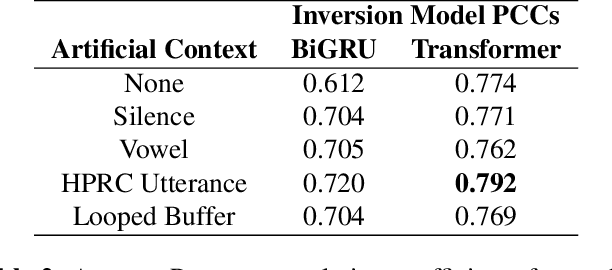

Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
SD-HuBERT: Self-Distillation Induces Syllabic Organization in HuBERT
Oct 16, 2023



Data-driven unit discovery in self-supervised learning (SSL) of speech has embarked on a new era of spoken language processing. Yet, the discovered units often remain in phonetic space, limiting the utility of SSL representations. Here, we demonstrate that a syllabic organization emerges in learning sentence-level representation of speech. In particular, we adopt "self-distillation" objective to fine-tune the pretrained HuBERT with an aggregator token that summarizes the entire sentence. Without any supervision, the resulting model draws definite boundaries in speech, and the representations across frames show salient syllabic structures. We demonstrate that this emergent structure largely corresponds to the ground truth syllables. Furthermore, we propose a new benchmark task, Spoken Speech ABX, for evaluating sentence-level representation of speech. When compared to previous models, our model outperforms in both unsupervised syllable discovery and learning sentence-level representation. Together, we demonstrate that the self-distillation of HuBERT gives rise to syllabic organization without relying on external labels or modalities, and potentially provides novel data-driven units for spoken language modeling.
Self-Supervised Models of Speech Infer Universal Articulatory Kinematics
Oct 16, 2023



Self-Supervised Learning (SSL) based models of speech have shown remarkable performance on a range of downstream tasks. These state-of-the-art models have remained blackboxes, but many recent studies have begun "probing" models like HuBERT, to correlate their internal representations to different aspects of speech. In this paper, we show "inference of articulatory kinematics" as fundamental property of SSL models, i.e., the ability of these models to transform acoustics into the causal articulatory dynamics underlying the speech signal. We also show that this abstraction is largely overlapping across the language of the data used to train the model, with preference to the language with similar phonological system. Furthermore, we show that with simple affine transformations, Acoustic-to-Articulatory inversion (AAI) is transferrable across speakers, even across genders, languages, and dialects, showing the generalizability of this property. Together, these results shed new light on the internals of SSL models that are critical to their superior performance, and open up new avenues into language-agnostic universal models for speech engineering, that are interpretable and grounded in speech science.
CiwaGAN: Articulatory information exchange
Sep 14, 2023



Humans encode information into sounds by controlling articulators and decode information from sounds using the auditory apparatus. This paper introduces CiwaGAN, a model of human spoken language acquisition that combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. While prior research includes unsupervised articulatory modeling and information exchange separately, our model is the first to combine the two components. The paper also proposes an improved articulatory model with more interpretable internal representations. The proposed CiwaGAN model is the most realistic approximation of human spoken language acquisition using deep learning. As such, it is useful for cognitively plausible simulations of the human speech act.
Neural Latent Aligner: Cross-trial Alignment for Learning Representations of Complex, Naturalistic Neural Data
Aug 12, 2023



Understanding the neural implementation of complex human behaviors is one of the major goals in neuroscience. To this end, it is crucial to find a true representation of the neural data, which is challenging due to the high complexity of behaviors and the low signal-to-ratio (SNR) of the signals. Here, we propose a novel unsupervised learning framework, Neural Latent Aligner (NLA), to find well-constrained, behaviorally relevant neural representations of complex behaviors. The key idea is to align representations across repeated trials to learn cross-trial consistent information. Furthermore, we propose a novel, fully differentiable time warping model (TWM) to resolve the temporal misalignment of trials. When applied to intracranial electrocorticography (ECoG) of natural speaking, our model learns better representations for decoding behaviors than the baseline models, especially in lower dimensional space. The TWM is empirically validated by measuring behavioral coherence between aligned trials. The proposed framework learns more cross-trial consistent representations than the baselines, and when visualized, the manifold reveals shared neural trajectories across trials.
* Accepted at ICML 2023