 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Mar 25, 2026Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To circumvent this, previous studies simulate dysfluent speech to generate training data. However, those approaches are not comprehensive enough to simulate PPA as holistic, multi-level phenotypes, instead relying on isolated dysfluencies. To address this, we propose a novel, clinically grounded simulation framework, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate behaviors of logopenic variant of PPA (lvPPA) with varying degrees of severity. To this end, semantic, phonological, and temporal deficits of lvPPA are systematically identified by clinical experts, and simulated. We demonstrate that our framework enables more accurate and generalizable detection models.
Self-Supervised Speech Models Encode Phonetic Context via Position-dependent Orthogonal Subspaces
Mar 13, 2026Transformer-based self-supervised speech models (S3Ms) are often described as contextualized, yet what this entails remains unclear. Here, we focus on how a single frame-level S3M representation can encode phones and their surrounding context. Prior work has shown that S3Ms represent phones compositionally; for example, phonological vectors such as voicing, bilabiality, and nasality vectors are superposed in the S3M representation of [m]. We extend this view by proposing that phonological information from a sequence of neighboring phones is also compositionally encoded in a single frame, such that vectors corresponding to previous, current, and next phones are superposed within a single frame-level representation. We show that this structure has several properties, including orthogonality between relative positions, and emergence of implicit phonetic boundaries. Together, our findings advance our understanding of context-dependent S3M representations.
HuPER: A Human-Inspired Framework for Phonetic Perception
Feb 02, 2026We propose HuPER, a human-inspired framework that models phonetic perception as adaptive inference over acoustic-phonetics evidence and linguistic knowledge. With only 100 hours of training data, HuPER achieves state-of-the-art phonetic error rates on five English benchmarks and strong zero-shot transfer to 95 unseen languages. HuPER is also the first framework to enable adaptive, multi-path phonetic perception under diverse acoustic conditions. All training data, models, and code are open-sourced. Code and demo avaliable at https://github.com/HuPER29/HuPER.
Sylber 2.0: A Universal Syllable Embedding
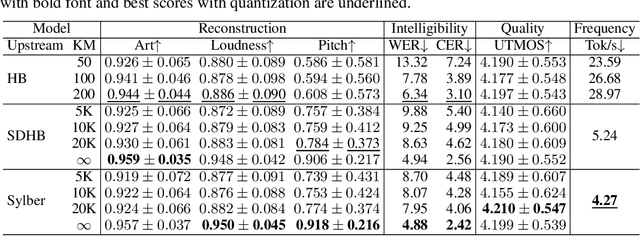
Jan 29, 2026Scaling spoken language modeling requires speech tokens that are both efficient and universal. Recent work has proposed syllables as promising speech tokens at low temporal resolution, but existing models are constrained to English and fail to capture sufficient acoustic detail. To address this gap, we present Sylber 2.0, a self-supervised framework for coding speech at the syllable level that enables efficient temporal compression and high-fidelity reconstruction. Sylber 2.0 achieves a very low token frequency around 5 Hz, while retaining both linguistic and acoustic detail across multiple languages and expressive styles. Experiments show that it performs on par with previous models operating on high-frequency baselines. Furthermore, Sylber 2.0 enables efficient TTS modeling which can generate speech with competitive intelligibility and quality with SOTA models using only 72M parameters. Moreover, the universality of Sylber 2.0 provides more effective features for low resource ASR than previous speech coding frameworks. In sum, we establish an effective syllable-level abstraction for general spoken language.
Scaling Spoken Language Models with Syllabic Speech Tokenization
Sep 30, 2025Spoken language models (SLMs) typically discretize speech into high-frame-rate tokens extracted from SSL speech models. As the most successful LMs are based on the Transformer architecture, processing these long token streams with self-attention is expensive, as attention scales quadratically with sequence length. A recent SSL work introduces acoustic tokenization of speech at the syllable level, which is more interpretable and potentially more scalable with significant compression in token lengths (4-5 Hz). Yet, their value for spoken language modeling is not yet fully explored. We present the first systematic study of syllabic tokenization for spoken language modeling, evaluating models on a suite of SLU benchmarks while varying training data scale. Syllabic tokens can match or surpass the previous high-frame rate tokens while significantly cutting training and inference costs, achieving more than a 2x reduction in training time and a 5x reduction in FLOPs. Our findings highlight syllable-level language modeling as a promising path to efficient long-context spoken language models.
LCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Aug 05, 2025Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
Analyzing The Language of Visual Tokens
Nov 07, 2024



With the introduction of transformer-based models for vision and language tasks, such as LLaVA and Chameleon, there has been renewed interest in the discrete tokenized representation of images. These models often treat image patches as discrete tokens, analogous to words in natural language, learning joint alignments between visual and human languages. However, little is known about the statistical behavior of these visual languages - whether they follow similar frequency distributions, grammatical structures, or topologies as natural languages. In this paper, we take a natural-language-centric approach to analyzing discrete visual languages and uncover striking similarities and fundamental differences. We demonstrate that, although visual languages adhere to Zipfian distributions, higher token innovation drives greater entropy and lower compression, with tokens predominantly representing object parts, indicating intermediate granularity. We also show that visual languages lack cohesive grammatical structures, leading to higher perplexity and weaker hierarchical organization compared to natural languages. Finally, we demonstrate that, while vision models align more closely with natural languages than other models, this alignment remains significantly weaker than the cohesion found within natural languages. Through these experiments, we demonstrate how understanding the statistical properties of discrete visual languages can inform the design of more effective computer vision models.
Sylber: Syllabic Embedding Representation of Speech from Raw Audio
Oct 09, 2024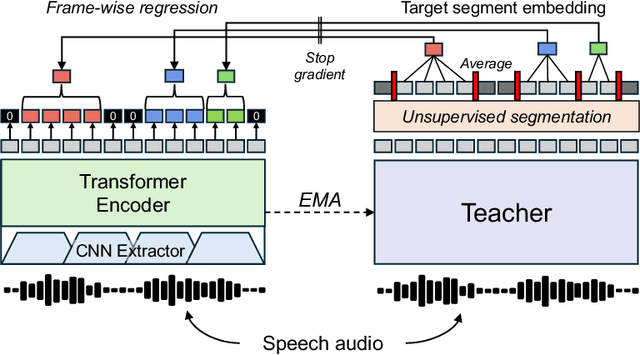
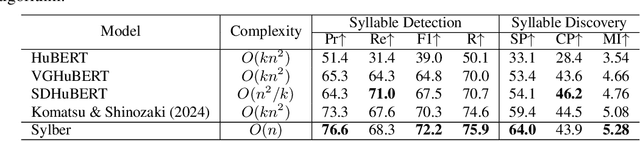
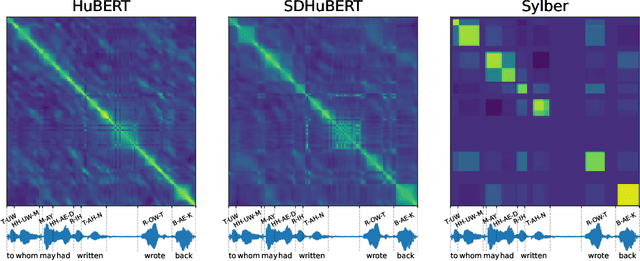
Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.
Stutter-Solver: End-to-end Multi-lingual Dysfluency Detection
Sep 15, 2024Current de-facto dysfluency modeling methods utilize template matching algorithms which are not generalizable to out-of-domain real-world dysfluencies across languages, and are not scalable with increasing amounts of training data. To handle these problems, we propose Stutter-Solver: an end-to-end framework that detects dysfluency with accurate type and time transcription, inspired by the YOLO object detection algorithm. Stutter-Solver can handle co-dysfluencies and is a natural multi-lingual dysfluency detector. To leverage scalability and boost performance, we also introduce three novel dysfluency corpora: VCTK-Pro, VCTK-Art, and AISHELL3-Pro, simulating natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation through articulatory-encodec and TTS-based methods. Our approach achieves state-of-the-art performance on all available dysfluency corpora. Code and datasets are open-sourced at https://github.com/eureka235/Stutter-Solver
Fast, High-Quality and Parameter-Efficient Articulatory Synthesis using Differentiable DSP
Sep 04, 2024



Articulatory trajectories like electromagnetic articulography (EMA) provide a low-dimensional representation of the vocal tract filter and have been used as natural, grounded features for speech synthesis. Differentiable digital signal processing (DDSP) is a parameter-efficient framework for audio synthesis. Therefore, integrating low-dimensional EMA features with DDSP can significantly enhance the computational efficiency of speech synthesis. In this paper, we propose a fast, high-quality, and parameter-efficient DDSP articulatory vocoder that can synthesize speech from EMA, F0, and loudness. We incorporate several techniques to solve the harmonics / noise imbalance problem, and add a multi-resolution adversarial loss for better synthesis quality. Our model achieves a transcription word error rate (WER) of 6.67% and a mean opinion score (MOS) of 3.74, with an improvement of 1.63% and 0.16 compared to the state-of-the-art (SOTA) baseline. Our DDSP vocoder is 4.9x faster than the baseline on CPU during inference, and can generate speech of comparable quality with only 0.4M parameters, in contrast to the 9M parameters required by the SOTA.