 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Tying Biases Token Embeddings Towards the Output Space
Mar 27, 2026Weight tying, i.e. sharing parameters between input and output embedding matrices, is common practice in language model design, yet its impact on the learned embedding space remains poorly understood. In this paper, we show that tied embedding matrices align more closely with output (unembedding) matrices than with input embeddings of comparable untied models, indicating that the shared matrix is shaped primarily for output prediction rather than input representation. This unembedding bias arises because output gradients dominate early in training. Using tuned lens analysis, we show this negatively affects early-layer computations, which contribute less effectively to the residual stream. Scaling input gradients during training reduces this bias, providing causal evidence for the role of gradient imbalance. This is mechanistic evidence that weight tying optimizes the embedding matrix for output prediction, compromising its role in input representation. These results help explain why weight tying can harm performance at scale and have implications for training smaller LLMs, where the embedding matrix contributes substantially to total parameter count.
AdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization
Feb 23, 2026The paradigm of automated program generation is shifting from one-shot generation to inference-time search, where Large Language Models (LLMs) function as semantic mutation operators within evolutionary loops. While effective, these systems are currently governed by static schedules that fail to account for the non-stationary dynamics of the search process. This rigidity results in substantial computational waste, as resources are indiscriminately allocated to stagnating populations while promising frontiers remain under-exploited. We introduce AdaEvolve, a framework that reformulates LLM-driven evolution as a hierarchical adaptive optimization problem. AdaEvolve uses an "accumulated improvement signal" to unify decisions across three levels: Local Adaptation, which dynamically modulates the exploration intensity within a population of solution candidates; Global Adaptation, which routes the global resource budget via bandit-based scheduling across different solution candidate populations; and Meta-Guidance which generates novel solution tactics based on the previously generated solutions and their corresponding improvements when the progress stalls. We demonstrate that AdaEvolve consistently outperforms the open-sourced baselines across 185 different open-ended optimization problems including combinatorial, systems optimization and algorithm design problems.
Evolutionary Strategies lead to Catastrophic Forgetting in LLMs
Jan 28, 2026One of the biggest missing capabilities in current AI systems is the ability to learn continuously after deployment. Implementing such continually learning systems have several challenges, one of which is the large memory requirement of gradient-based algorithms that are used to train state-of-the-art LLMs. Evolutionary Strategies (ES) have recently re-emerged as a gradient-free alternative to traditional learning algorithms and have shown encouraging performance on specific tasks in LLMs. In this paper, we perform a comprehensive analysis of ES and specifically evaluate its forgetting curves when training for an increasing number of update steps. We first find that ES is able to reach performance numbers close to GRPO for math and reasoning tasks with a comparable compute budget. However, and most importantly for continual learning, the performance gains in ES is accompanied by significant forgetting of prior abilities, limiting its applicability for training models online. We also explore the reason behind this behavior and show that the updates made using ES are much less sparse and have orders of magnitude larger $\ell_2$ norm compared to corresponding GRPO updates, explaining the contrasting forgetting curves between the two algorithms. With this study, we aim to highlight the issue of forgetting in gradient-free algorithms like ES and hope to inspire future work to mitigate these issues.
How Do LLMs Use Their Depth?
Oct 21, 2025



Growing evidence suggests that large language models do not use their depth uniformly, yet we still lack a fine-grained understanding of their layer-wise prediction dynamics. In this paper, we trace the intermediate representations of several open-weight models during inference and reveal a structured and nuanced use of depth. Specifically, we propose a "Guess-then-Refine" framework that explains how LLMs internally structure their computations to make predictions. We first show that the top-ranked predictions in early LLM layers are composed primarily of high-frequency tokens, which act as statistical guesses proposed by the model early on due to the lack of appropriate contextual information. As contextual information develops deeper into the model, these initial guesses get refined into contextually appropriate tokens. Even high-frequency token predictions from early layers get refined >70% of the time, indicating that correct token prediction is not "one-and-done". We then go beyond frequency-based prediction to examine the dynamic usage of layer depth across three case studies. (i) Part-of-speech analysis shows that function words are, on average, the earliest to be predicted correctly. (ii) Fact recall task analysis shows that, in a multi-token answer, the first token requires more computational depth than the rest. (iii) Multiple-choice task analysis shows that the model identifies the format of the response within the first half of the layers, but finalizes its response only toward the end. Together, our results provide a detailed view of depth usage in LLMs, shedding light on the layer-by-layer computations that underlie successful predictions and providing insights for future works to improve computational efficiency in transformer-based models.
InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction Generation
Sep 11, 2025While large-scale human motion capture datasets have advanced human motion generation, modeling and generating dynamic 3D human-object interactions (HOIs) remain challenging due to dataset limitations. Existing datasets often lack extensive, high-quality motion and annotation and exhibit artifacts such as contact penetration, floating, and incorrect hand motions. To address these issues, we introduce InterAct, a large-scale 3D HOI benchmark featuring dataset and methodological advancements. First, we consolidate and standardize 21.81 hours of HOI data from diverse sources, enriching it with detailed textual annotations. Second, we propose a unified optimization framework to enhance data quality by reducing artifacts and correcting hand motions. Leveraging the principle of contact invariance, we maintain human-object relationships while introducing motion variations, expanding the dataset to 30.70 hours. Third, we define six benchmarking tasks and develop a unified HOI generative modeling perspective, achieving state-of-the-art performance. Extensive experiments validate the utility of our dataset as a foundational resource for advancing 3D human-object interaction generation. To support continued research in this area, the dataset is publicly available at https://github.com/wzyabcas/InterAct, and will be actively maintained.
Efficient Knowledge Editing via Minimal Precomputation
Jun 04, 2025Knowledge editing methods like MEMIT are able to make data and compute efficient updates of factual knowledge by using a single sentence to update facts and their consequences. However, what is often overlooked is a "precomputation step", which requires a one-time but significant computational cost. The authors of MEMIT originally precompute approximately 44 million hidden vectors per edited layer, which requires a forward pass over 44 million tokens. For GPT-J (6B), this precomputation step takes 36 hours on a single GPU, while it takes approximately 40 hours for Llama2-7B. Additionally, this precomputation time grows with model size. In this paper, we show that this excessive computational cost is unnecessary. Knowledge editing using MEMIT and related methods, such as ROME and EMMET, can be performed by pre-computing a very small portion of the 44 million hidden vectors. We first present the theoretical minimum number of hidden vector precomputation required for solutions of these editing methods to exist. We then empirically show that knowledge editing using these methods can be done by pre-computing significantly fewer hidden vectors. Specifically, we show that the precomputation step can be done with less than 0.3% of the originally stipulated number of hidden vectors. This saves a significant amount of precomputation time and allows users to begin editing new models within a few minutes.
Norm Growth and Stability Challenges in Localized Sequential Knowledge Editing
Feb 26, 2025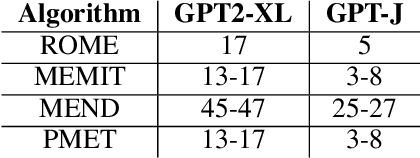



This study investigates the impact of localized updates to large language models (LLMs), specifically in the context of knowledge editing - a task aimed at incorporating or modifying specific facts without altering broader model capabilities. We first show that across different post-training interventions like continuous pre-training, full fine-tuning and LORA-based fine-tuning, the Frobenius norm of the updated matrices always increases. This increasing norm is especially detrimental for localized knowledge editing, where only a subset of matrices are updated in a model . We reveal a consistent phenomenon across various editing techniques, including fine-tuning, hypernetwork-based approaches, and locate-and-edit methods: the norm of the updated matrix invariably increases with successive updates. Such growth disrupts model balance, particularly when isolated matrices are updated while the rest of the model remains static, leading to potential instability and degradation of downstream performance. Upon deeper investigations of the intermediate activation vectors, we find that the norm of internal activations decreases and is accompanied by shifts in the subspaces occupied by these activations, which shows that these activation vectors now occupy completely different regions in the representation space compared to the unedited model. With our paper, we highlight the technical challenges with continuous and localized sequential knowledge editing and their implications for maintaining model stability and utility.
Lifelong Sequential Knowledge Editing without Model Degradation
Feb 03, 2025



Prior work in parameter-modifying knowledge editing has shown that large-scale sequential editing leads to significant model degradation. In this paper, we study the reasons behind this and scale sequential knowledge editing to 10,000 sequential edits, while maintaining the downstream performance of the original model. We first show that locate-then-edit knowledge editing methods lead to overfitting on the edited facts. We also show that continuous knowledge editing using these methods leads to disproportionate growth in the norm of the edited matrix. We then provide a crucial insight into the inner workings of locate-then-edit methods. We show that norm-growth is a hidden trick employed by these methods that gives larger importance to the output activations produced from the edited layers. With this "importance hacking", the edited layers provide a much larger contributions to the model's output. To mitigate these issues, we present ENCORE - Early stopping and Norm-Constrained Robust knowledge Editing. ENCORE controls for overfitting and the disproportionate norm-growth to enable long-term sequential editing, where we are able to perform up to 10,000 sequential edits without loss of downstream performance. ENCORE is also 61% faster than MEMIT and 64% faster than AlphaEdit on Llama3-8B.
PokerBench: Training Large Language Models to become Professional Poker Players
Jan 14, 2025



We introduce PokerBench - a benchmark for evaluating the poker-playing abilities of large language models (LLMs). As LLMs excel in traditional NLP tasks, their application to complex, strategic games like poker poses a new challenge. Poker, an incomplete information game, demands a multitude of skills such as mathematics, reasoning, planning, strategy, and a deep understanding of game theory and human psychology. This makes Poker the ideal next frontier for large language models. PokerBench consists of a comprehensive compilation of 11,000 most important scenarios, split between pre-flop and post-flop play, developed in collaboration with trained poker players. We evaluate prominent models including GPT-4, ChatGPT 3.5, and various Llama and Gemma series models, finding that all state-of-the-art LLMs underperform in playing optimal poker. However, after fine-tuning, these models show marked improvements. We validate PokerBench by having models with different scores compete with each other, demonstrating that higher scores on PokerBench lead to higher win rates in actual poker games. Through gameplay between our fine-tuned model and GPT-4, we also identify limitations of simple supervised fine-tuning for learning optimal playing strategy, suggesting the need for more advanced methodologies for effectively training language models to excel in games. PokerBench thus presents a unique benchmark for a quick and reliable evaluation of the poker-playing ability of LLMs as well as a comprehensive benchmark to study the progress of LLMs in complex game-playing scenarios. The dataset and code will be made available at: \url{https://github.com/pokerllm/pokerbench}.
Sylber: Syllabic Embedding Representation of Speech from Raw Audio
Oct 09, 2024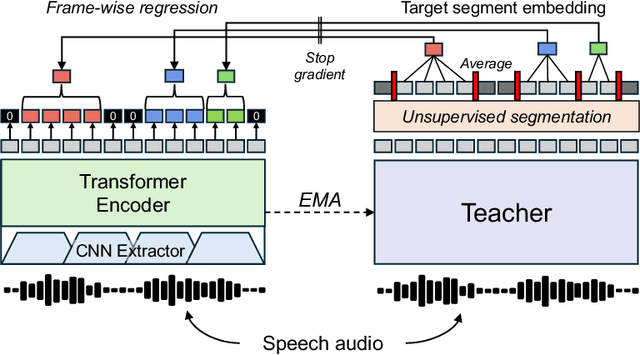
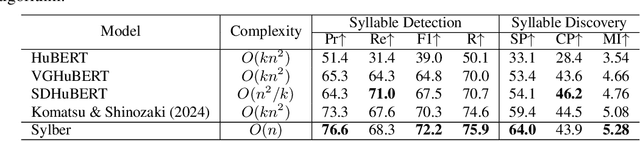
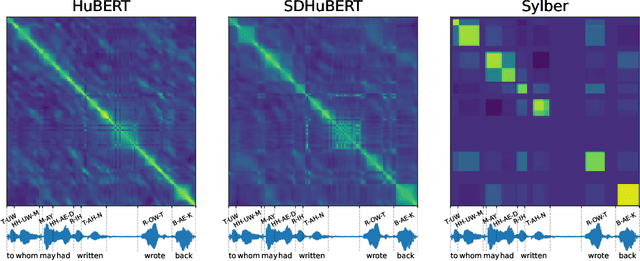
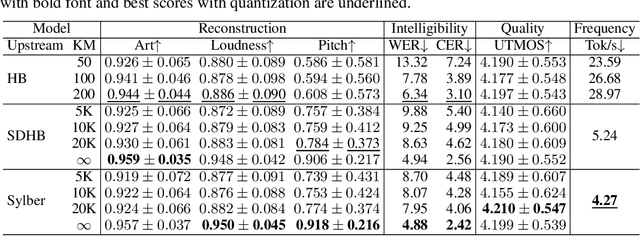
Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.