 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Bigger Edit Batch Size Always Better? -- An Empirical Study on Model Editing with Llama-3
May 01, 2024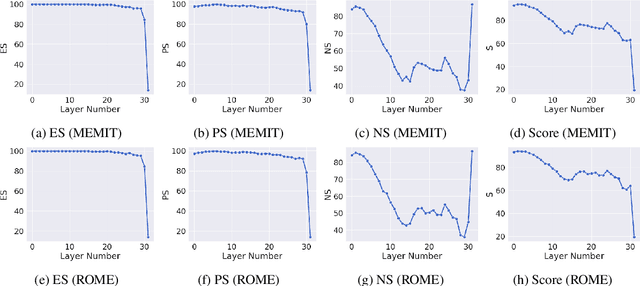
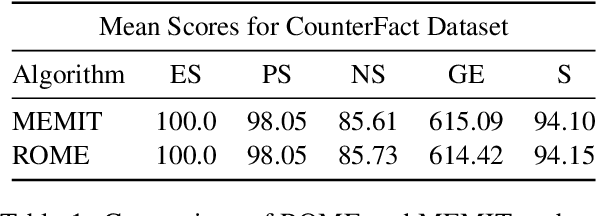
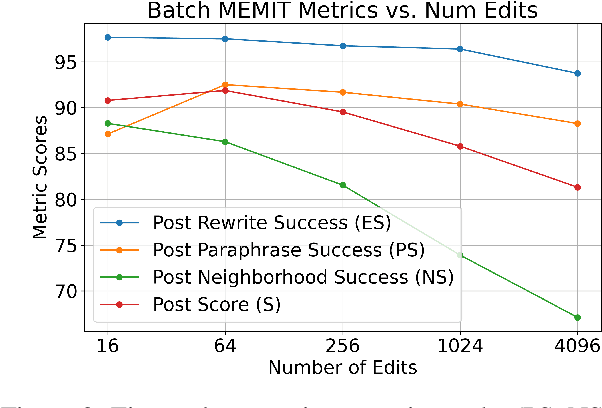
This study presents a targeted model editing analysis focused on the latest large language model, Llama-3. We explore the efficacy of popular model editing techniques - ROME, MEMIT, and EMMET, which are designed for precise layer interventions. We identify the most effective layers for targeted edits through an evaluation that encompasses up to 4096 edits across three distinct strategies: sequential editing, batch editing, and a hybrid approach we call as sequential-batch editing. Our findings indicate that increasing edit batch-sizes may degrade model performance more significantly than using smaller edit batches sequentially for equal number of edits. With this, we argue that sequential model editing is an important component for scaling model editing methods and future research should focus on methods that combine both batched and sequential editing. This observation suggests a potential limitation in current model editing methods which push towards bigger edit batch sizes, and we hope it paves way for future investigations into optimizing batch sizes and model editing performance.
Automatic Curriculum Learning with Gradient Reward Signals
Dec 21, 2023This paper investigates the impact of using gradient norm reward signals in the context of Automatic Curriculum Learning (ACL) for deep reinforcement learning (DRL). We introduce a framework where the teacher model, utilizing the gradient norm information of a student model, dynamically adapts the learning curriculum. This approach is based on the hypothesis that gradient norms can provide a nuanced and effective measure of learning progress. Our experimental setup involves several reinforcement learning environments (PointMaze, AntMaze, and AdroitHandRelocate), to assess the efficacy of our method. We analyze how gradient norm rewards influence the teacher's ability to craft challenging yet achievable learning sequences, ultimately enhancing the student's performance. Our results show that this approach not only accelerates the learning process but also leads to improved generalization and adaptability in complex tasks. The findings underscore the potential of gradient norm signals in creating more efficient and robust ACL systems, opening new avenues for research in curriculum learning and reinforcement learning.