 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Custom Models Learn In-Context? An Exploration of Hybrid Architecture Performance on In-Context Learning Tasks
Nov 06, 2024
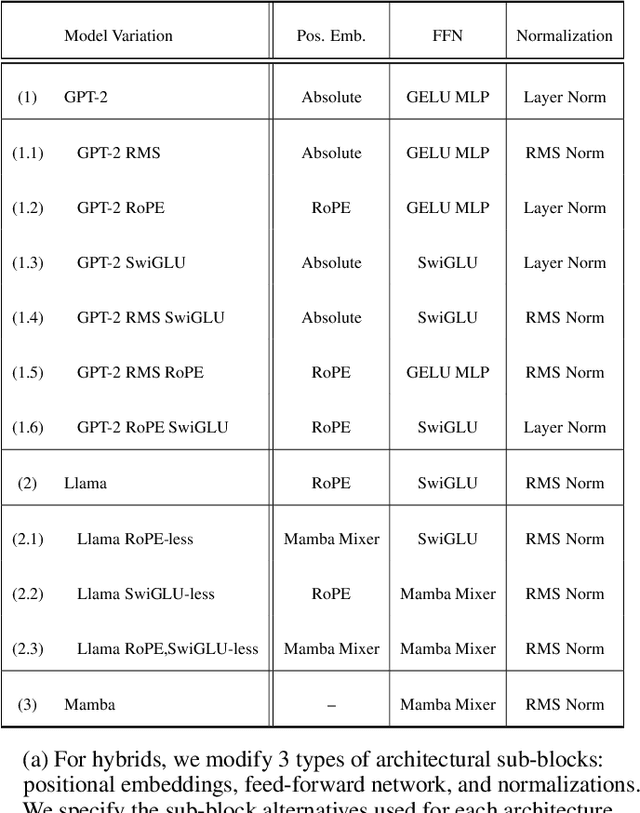

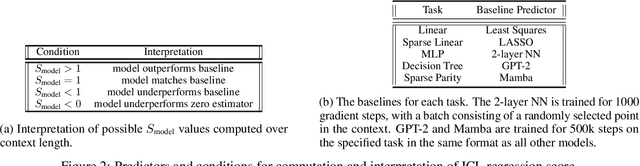
In-Context Learning (ICL) is a phenomenon where task learning occurs through a prompt sequence without the necessity of parameter updates. ICL in Multi-Headed Attention (MHA) with absolute positional embedding has been the focus of more study than other sequence model varieties. We examine implications of architectural differences between GPT-2 and LLaMa as well as LlaMa and Mamba. We extend work done by Garg et al. (2022) and Park et al. (2024) to GPT-2/LLaMa hybrid and LLaMa/Mamba hybrid models - examining the interplay between sequence transformation blocks and regressive performance in-context. We note that certain architectural changes cause degraded training efficiency/ICL accuracy by converging to suboptimal predictors or converging slower. We also find certain hybrids showing optimistic performance improvements, informing potential future ICL-focused architecture modifications. Additionally, we propose the "ICL regression score", a scalar metric describing a model's whole performance on a specific task. Compute limitations impose restrictions on our architecture-space, training duration, number of training runs, function class complexity, and benchmark complexity. To foster reproducible and extensible research, we provide a typed, modular, and extensible Python package on which we run all experiments.
Automatic Curriculum Learning with Gradient Reward Signals
Dec 21, 2023This paper investigates the impact of using gradient norm reward signals in the context of Automatic Curriculum Learning (ACL) for deep reinforcement learning (DRL). We introduce a framework where the teacher model, utilizing the gradient norm information of a student model, dynamically adapts the learning curriculum. This approach is based on the hypothesis that gradient norms can provide a nuanced and effective measure of learning progress. Our experimental setup involves several reinforcement learning environments (PointMaze, AntMaze, and AdroitHandRelocate), to assess the efficacy of our method. We analyze how gradient norm rewards influence the teacher's ability to craft challenging yet achievable learning sequences, ultimately enhancing the student's performance. Our results show that this approach not only accelerates the learning process but also leads to improved generalization and adaptability in complex tasks. The findings underscore the potential of gradient norm signals in creating more efficient and robust ACL systems, opening new avenues for research in curriculum learning and reinforcement learning.
Can Transformers Learn Sequential Function Classes In Context?
Dec 21, 2023In-context learning (ICL) has revolutionized the capabilities of transformer models in NLP. In our project, we extend the understanding of the mechanisms underpinning ICL by exploring whether transformers can learn from sequential, non-textual function class data distributions. We introduce a novel sliding window sequential function class and employ toy-sized transformers with a GPT-2 architecture to conduct our experiments. Our analysis indicates that these models can indeed leverage ICL when trained on non-textual sequential function classes. Additionally, our experiments with randomized y-label sequences highlights that transformers retain some ICL capabilities even when the label associations are obfuscated. We provide evidence that transformers can reason with and understand sequentiality encoded within function classes, as reflected by the effective learning of our proposed tasks. Our results also show that the performance deteriorated with increasing randomness in the labels, though not to the extent one might expect, implying a potential robustness of learned sequentiality against label noise. Future research may want to look into how previous explanations of transformers, such as induction heads and task vectors, relate to sequentiality in ICL in these toy examples. Our investigation lays the groundwork for further research into how transformers process and perceive sequential data.
Adversarial Boot Camp: label free certified robustness in one epoch
Oct 05, 2020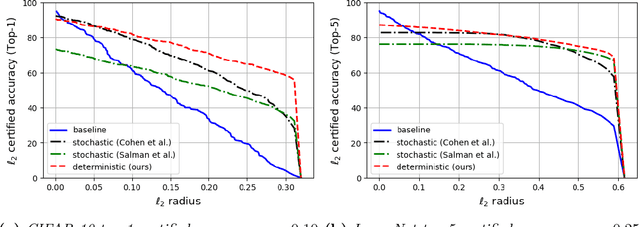

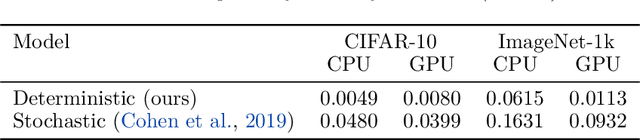
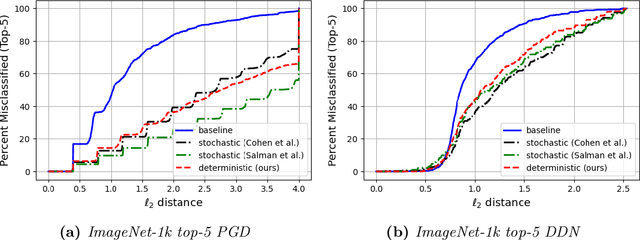
Machine learning models are vulnerable to adversarial attacks. One approach to addressing this vulnerability is certification, which focuses on models that are guaranteed to be robust for a given perturbation size. A drawback of recent certified models is that they are stochastic: they require multiple computationally expensive model evaluations with random noise added to a given input. In our work, we present a deterministic certification approach which results in a certifiably robust model. This approach is based on an equivalence between training with a particular regularized loss, and the expected values of Gaussian averages. We achieve certified models on ImageNet-1k by retraining a model with this loss for one epoch without the use of label information.
Deterministic Gaussian Averaged Neural Networks
Jun 10, 2020
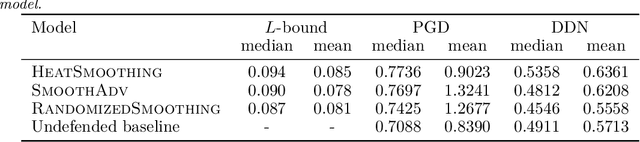
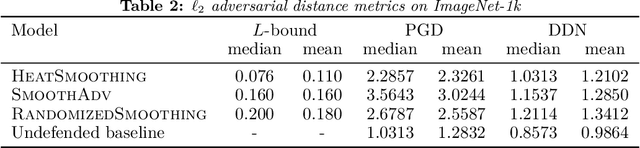
We present a deterministic method to compute the Gaussian average of neural networks used in regression and classification. Our method is based on an equivalence between training with a particular regularized loss, and the expected values of Gaussian averages. We use this equivalence to certify models which perform well on clean data but are not robust to adversarial perturbations. In terms of certified accuracy and adversarial robustness, our method is comparable to known stochastic methods such as randomized smoothing, but requires only a single model evaluation during inference.