 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Custom Models Learn In-Context? An Exploration of Hybrid Architecture Performance on In-Context Learning Tasks
Nov 06, 2024
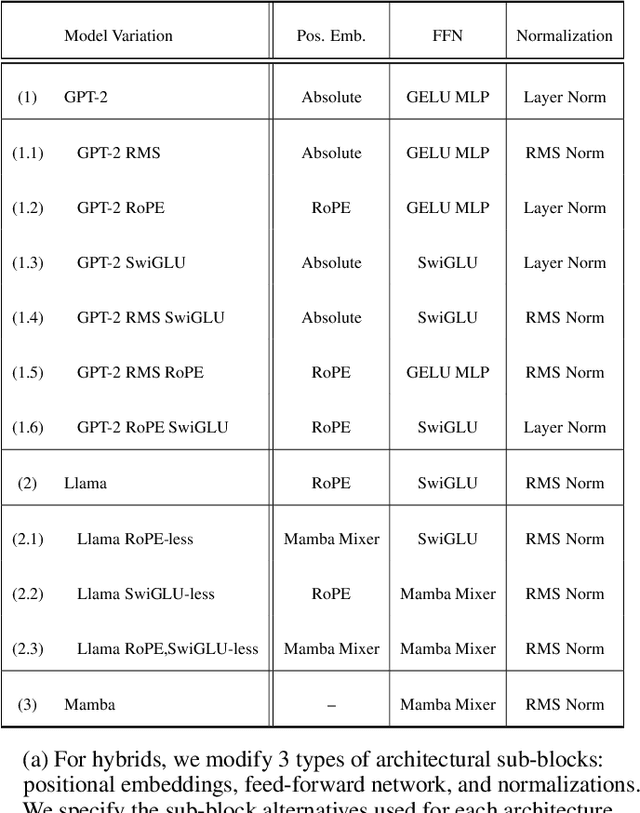

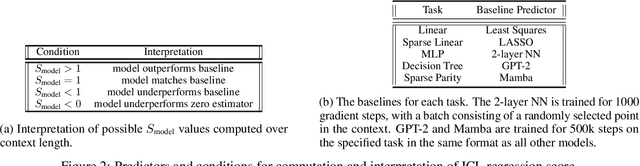
In-Context Learning (ICL) is a phenomenon where task learning occurs through a prompt sequence without the necessity of parameter updates. ICL in Multi-Headed Attention (MHA) with absolute positional embedding has been the focus of more study than other sequence model varieties. We examine implications of architectural differences between GPT-2 and LLaMa as well as LlaMa and Mamba. We extend work done by Garg et al. (2022) and Park et al. (2024) to GPT-2/LLaMa hybrid and LLaMa/Mamba hybrid models - examining the interplay between sequence transformation blocks and regressive performance in-context. We note that certain architectural changes cause degraded training efficiency/ICL accuracy by converging to suboptimal predictors or converging slower. We also find certain hybrids showing optimistic performance improvements, informing potential future ICL-focused architecture modifications. Additionally, we propose the "ICL regression score", a scalar metric describing a model's whole performance on a specific task. Compute limitations impose restrictions on our architecture-space, training duration, number of training runs, function class complexity, and benchmark complexity. To foster reproducible and extensible research, we provide a typed, modular, and extensible Python package on which we run all experiments.