 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineZip : Pushing the Limits of Large Language Models for Practical Lossless Text Compression
Sep 25, 2024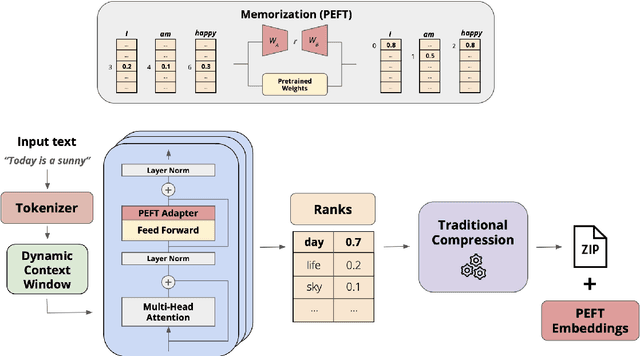
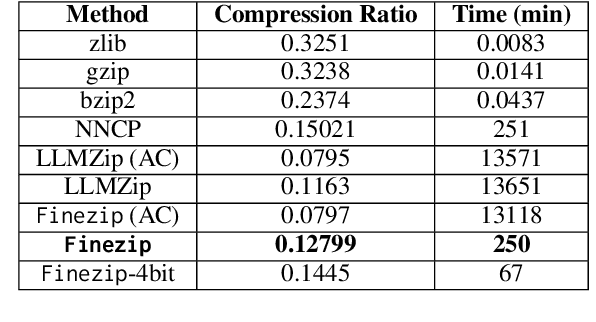
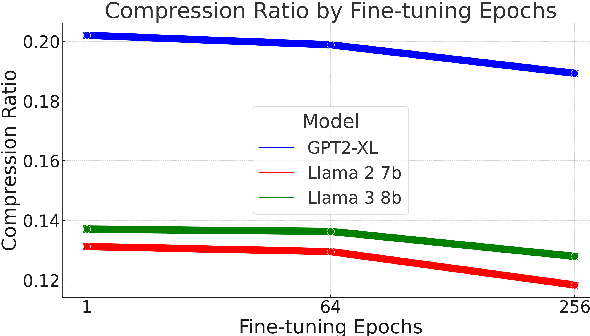
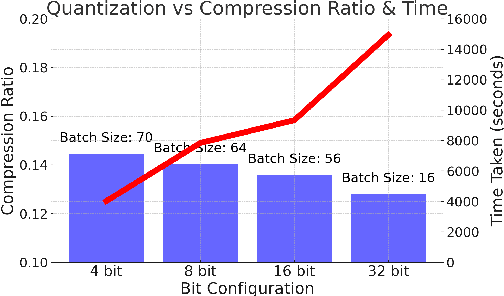
While the language modeling objective has been shown to be deeply connected with compression, it is surprising that modern LLMs are not employed in practical text compression systems. In this paper, we provide an in-depth analysis of neural network and transformer-based compression techniques to answer this question. We compare traditional text compression systems with neural network and LLM-based text compression methods. Although LLM-based systems significantly outperform conventional compression methods, they are highly impractical. Specifically, LLMZip, a recent text compression system using Llama3-8B requires 9.5 days to compress just 10 MB of text, although with huge improvements in compression ratios. To overcome this, we present FineZip - a novel LLM-based text compression system that combines ideas of online memorization and dynamic context to reduce the compression time immensely. FineZip can compress the above corpus in approximately 4 hours compared to 9.5 days, a 54 times improvement over LLMZip and comparable performance. FineZip outperforms traditional algorithmic compression methods with a large margin, improving compression ratios by approximately 50\%. With this work, we take the first step towards making lossless text compression with LLMs a reality. While FineZip presents a significant step in that direction, LLMs are still not a viable solution for large-scale text compression. We hope our work paves the way for future research and innovation to solve this problem.
Decoding Emotions: A comprehensive Multilingual Study of Speech Models for Speech Emotion Recognition
Aug 17, 2023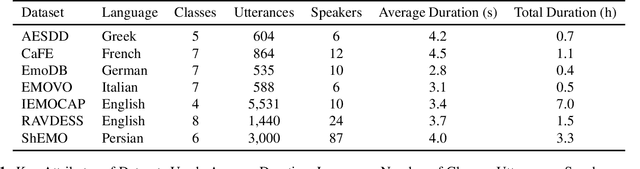
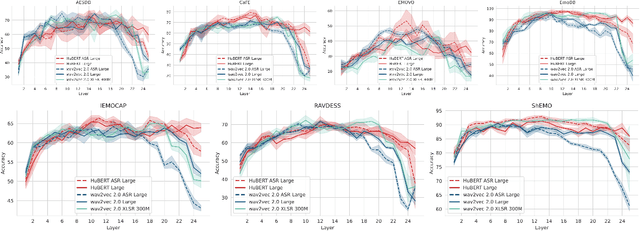
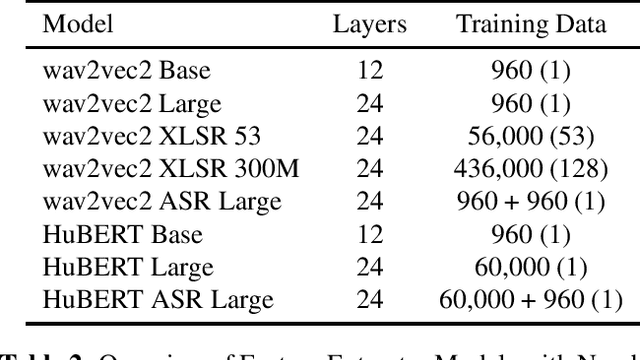
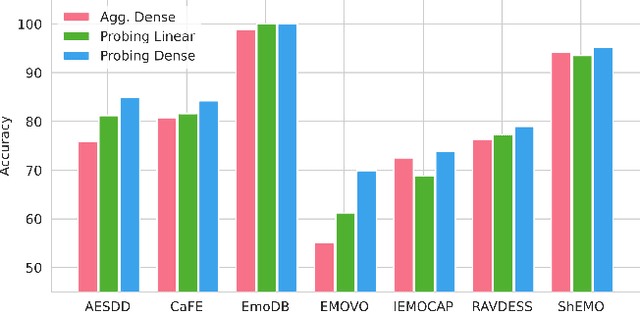
Recent advancements in transformer-based speech representation models have greatly transformed speech processing. However, there has been limited research conducted on evaluating these models for speech emotion recognition (SER) across multiple languages and examining their internal representations. This article addresses these gaps by presenting a comprehensive benchmark for SER with eight speech representation models and six different languages. We conducted probing experiments to gain insights into inner workings of these models for SER. We find that using features from a single optimal layer of a speech model reduces the error rate by 32\% on average across seven datasets when compared to systems where features from all layers of speech models are used. We also achieve state-of-the-art results for German and Persian languages. Our probing results indicate that the middle layers of speech models capture the most important emotional information for speech emotion recognition.
Have Large Language Models Developed a Personality?: Applicability of Self-Assessment Tests in Measuring Personality in LLMs
May 24, 2023
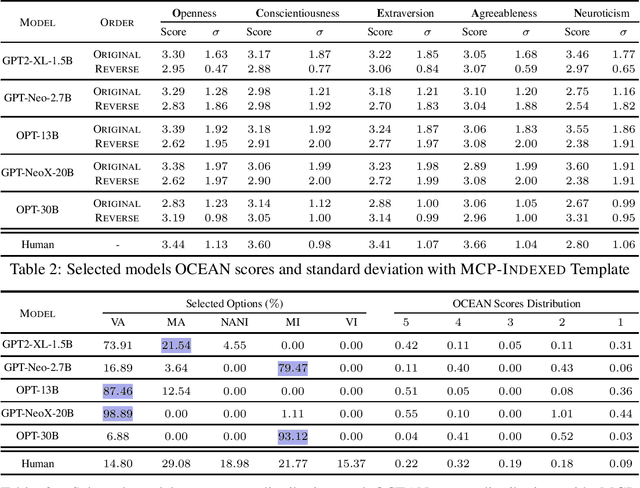
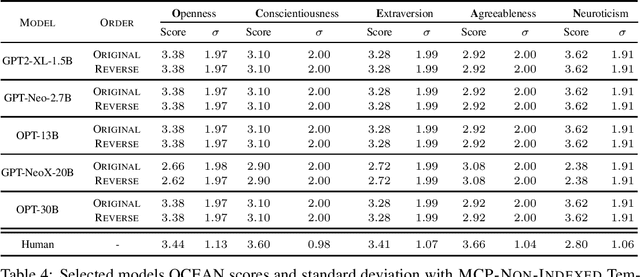
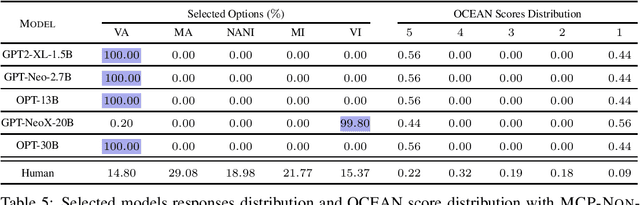
Have Large Language Models (LLMs) developed a personality? The short answer is a resounding "We Don't Know!". In this paper, we show that we do not yet have the right tools to measure personality in language models. Personality is an important characteristic that influences behavior. As LLMs emulate human-like intelligence and performance in various tasks, a natural question to ask is whether these models have developed a personality. Previous works have evaluated machine personality through self-assessment personality tests, which are a set of multiple-choice questions created to evaluate personality in humans. A fundamental assumption here is that human personality tests can accurately measure personality in machines. In this paper, we investigate the emergence of personality in five LLMs of different sizes ranging from 1.5B to 30B. We propose the Option-Order Symmetry property as a necessary condition for the reliability of these self-assessment tests. Under this condition, the answer to self-assessment questions is invariant to the order in which the options are presented. We find that many LLMs personality test responses do not preserve option-order symmetry. We take a deeper look at LLMs test responses where option-order symmetry is preserved to find that in these cases, LLMs do not take into account the situational statement being tested and produce the exact same answer irrespective of the situation being tested. We also identify the existence of inherent biases in these LLMs which is the root cause of the aforementioned phenomenon and makes self-assessment tests unreliable. These observations indicate that self-assessment tests are not the correct tools to measure personality in LLMs. Through this paper, we hope to draw attention to the shortcomings of current literature in measuring personality in LLMs and call for developing tools for machine personality measurement.