 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Out-of-Distribution Detection with Gaussian Processes
Dec 30, 2024Deep neural networks (DNNs) are often constructed under the closed-world assumption, which may fail to generalize to the out-of-distribution (OOD) data. This leads to DNNs producing overconfident wrong predictions and can result in disastrous consequences in safety-critical applications. Existing OOD detection methods mainly rely on curating a set of OOD data for model training or hyper-parameter tuning to distinguish OOD data from training data (also known as in-distribution data or InD data). However, OOD samples are not always available during the training phase in real-world applications, hindering the OOD detection accuracy. To overcome this limitation, we propose a Gaussian-process-based OOD detection method to establish a decision boundary based on InD data only. The basic idea is to perform uncertainty quantification of the unconstrained softmax scores of a DNN via a multi-class Gaussian process (GP), and then define a score function to separate InD and potential OOD data based on their fundamental differences in the posterior predictive distribution from the GP. Two case studies on conventional image classification datasets and real-world image datasets are conducted to demonstrate that the proposed method outperforms the state-of-the-art OOD detection methods when OOD samples are not observed in the training phase.
Identifying Multiple Personalities in Large Language Models with External Evaluation
Feb 22, 2024



As Large Language Models (LLMs) are integrated with human daily applications rapidly, many societal and ethical concerns are raised regarding the behavior of LLMs. One of the ways to comprehend LLMs' behavior is to analyze their personalities. Many recent studies quantify LLMs' personalities using self-assessment tests that are created for humans. Yet many critiques question the applicability and reliability of these self-assessment tests when applied to LLMs. In this paper, we investigate LLM personalities using an alternate personality measurement method, which we refer to as the external evaluation method, where instead of prompting LLMs with multiple-choice questions in the Likert scale, we evaluate LLMs' personalities by analyzing their responses toward open-ended situational questions using an external machine learning model. We first fine-tuned a Llama2-7B model as the MBTI personality predictor that outperforms the state-of-the-art models as the tool to analyze LLMs' responses. Then, we prompt the LLMs with situational questions and ask them to generate Twitter posts and comments, respectively, in order to assess their personalities when playing two different roles. Using the external personality evaluation method, we identify that the obtained personality types for LLMs are significantly different when generating posts versus comments, whereas humans show a consistent personality profile in these two different situations. This shows that LLMs can exhibit different personalities based on different scenarios, thus highlighting a fundamental difference between personality in LLMs and humans. With our work, we call for a re-evaluation of personality definition and measurement in LLMs.
SEE-OoD: Supervised Exploration For Enhanced Out-of-Distribution Detection
Oct 12, 2023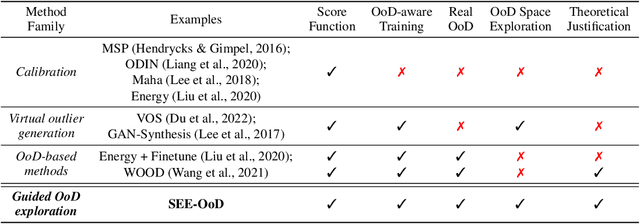
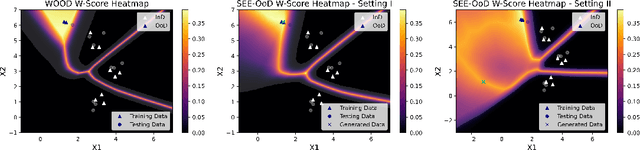
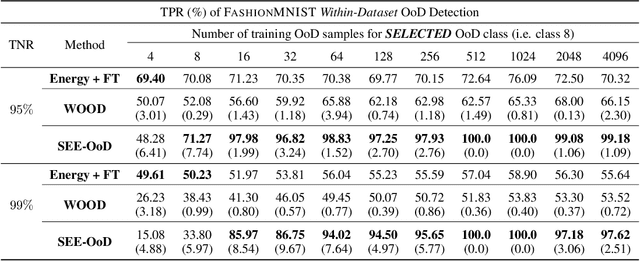
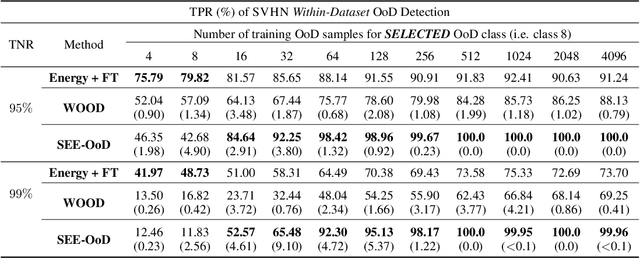
Current techniques for Out-of-Distribution (OoD) detection predominantly rely on quantifying predictive uncertainty and incorporating model regularization during the training phase, using either real or synthetic OoD samples. However, methods that utilize real OoD samples lack exploration and are prone to overfit the OoD samples at hand. Whereas synthetic samples are often generated based on features extracted from training data, rendering them less effective when the training and OoD data are highly overlapped in the feature space. In this work, we propose a Wasserstein-score-based generative adversarial training scheme to enhance OoD detection accuracy, which, for the first time, performs data augmentation and exploration simultaneously under the supervision of limited OoD samples. Specifically, the generator explores OoD spaces and generates synthetic OoD samples using feedback from the discriminator, while the discriminator exploits both the observed and synthesized samples for OoD detection using a predefined Wasserstein score. We provide theoretical guarantees that the optimal solutions of our generative scheme are statistically achievable through adversarial training in empirical settings. We then demonstrate that the proposed method outperforms state-of-the-art techniques on various computer vision datasets and exhibits superior generalizability to unseen OoD data.
Investigating the Applicability of Self-Assessment Tests for Personality Measurement of Large Language Models
Sep 15, 2023
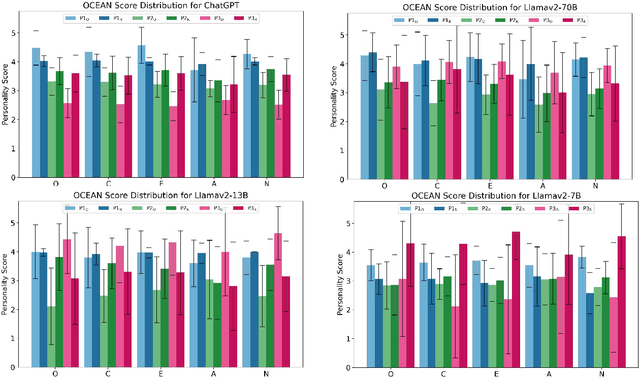
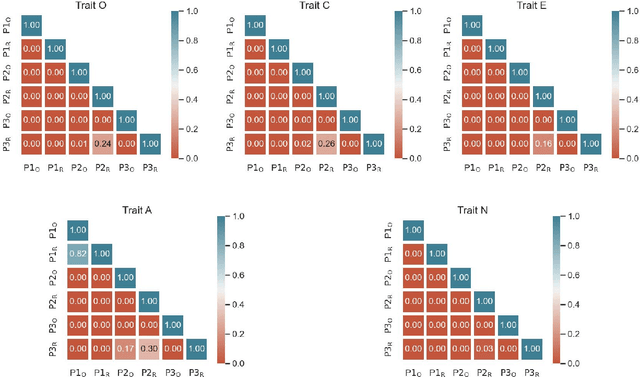

As large language models (LLM) evolve in their capabilities, various recent studies have tried to quantify their behavior using psychological tools created to study human behavior. One such example is the measurement of "personality" of LLMs using personality self-assessment tests. In this paper, we take three such studies on personality measurement of LLMs that use personality self-assessment tests created to study human behavior. We use the prompts used in these three different papers to measure the personality of the same LLM. We find that all three prompts lead very different personality scores. This simple test reveals that personality self-assessment scores in LLMs depend on the subjective choice of the prompter. Since we don't know the ground truth value of personality scores for LLMs as there is no correct answer to such questions, there's no way of claiming if one prompt is more or less correct than the other. We then introduce the property of option order symmetry for personality measurement of LLMs. Since most of the self-assessment tests exist in the form of multiple choice question (MCQ) questions, we argue that the scores should also be robust to not just the prompt template but also the order in which the options are presented. This test unsurprisingly reveals that the answers to the self-assessment tests are not robust to the order of the options. These simple tests, done on ChatGPT and Llama2 models show that self-assessment personality tests created for humans are not appropriate for measuring personality in LLMs.
Have Large Language Models Developed a Personality?: Applicability of Self-Assessment Tests in Measuring Personality in LLMs
May 24, 2023
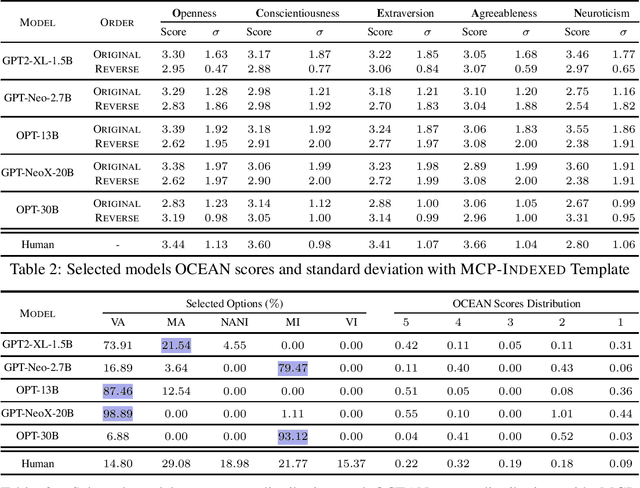
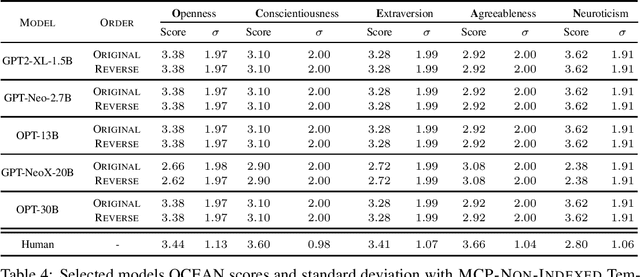
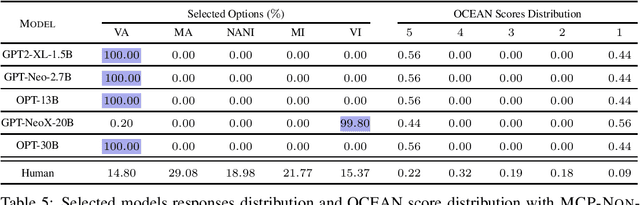
Have Large Language Models (LLMs) developed a personality? The short answer is a resounding "We Don't Know!". In this paper, we show that we do not yet have the right tools to measure personality in language models. Personality is an important characteristic that influences behavior. As LLMs emulate human-like intelligence and performance in various tasks, a natural question to ask is whether these models have developed a personality. Previous works have evaluated machine personality through self-assessment personality tests, which are a set of multiple-choice questions created to evaluate personality in humans. A fundamental assumption here is that human personality tests can accurately measure personality in machines. In this paper, we investigate the emergence of personality in five LLMs of different sizes ranging from 1.5B to 30B. We propose the Option-Order Symmetry property as a necessary condition for the reliability of these self-assessment tests. Under this condition, the answer to self-assessment questions is invariant to the order in which the options are presented. We find that many LLMs personality test responses do not preserve option-order symmetry. We take a deeper look at LLMs test responses where option-order symmetry is preserved to find that in these cases, LLMs do not take into account the situational statement being tested and produce the exact same answer irrespective of the situation being tested. We also identify the existence of inherent biases in these LLMs which is the root cause of the aforementioned phenomenon and makes self-assessment tests unreliable. These observations indicate that self-assessment tests are not the correct tools to measure personality in LLMs. Through this paper, we hope to draw attention to the shortcomings of current literature in measuring personality in LLMs and call for developing tools for machine personality measurement.