 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEE-OoD: Supervised Exploration For Enhanced Out-of-Distribution Detection
Oct 12, 2023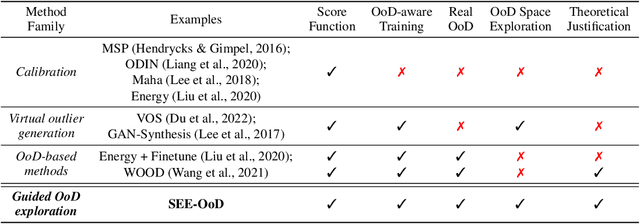
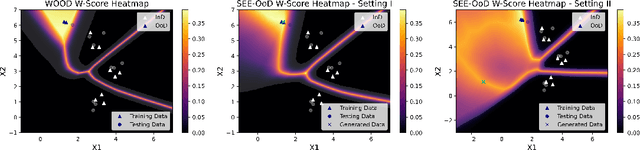
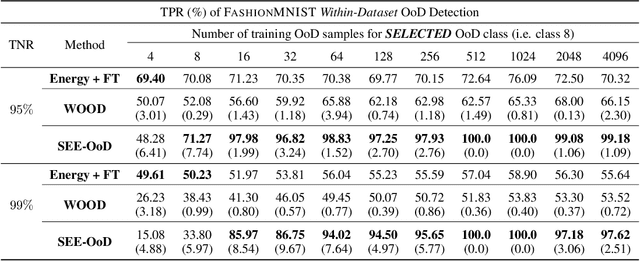
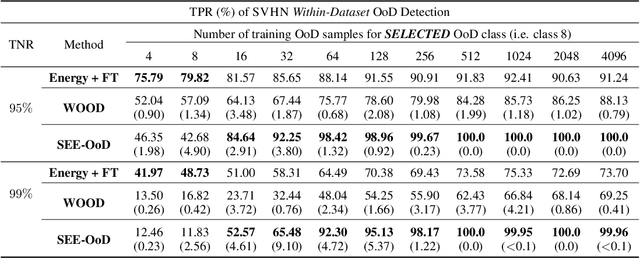
Current techniques for Out-of-Distribution (OoD) detection predominantly rely on quantifying predictive uncertainty and incorporating model regularization during the training phase, using either real or synthetic OoD samples. However, methods that utilize real OoD samples lack exploration and are prone to overfit the OoD samples at hand. Whereas synthetic samples are often generated based on features extracted from training data, rendering them less effective when the training and OoD data are highly overlapped in the feature space. In this work, we propose a Wasserstein-score-based generative adversarial training scheme to enhance OoD detection accuracy, which, for the first time, performs data augmentation and exploration simultaneously under the supervision of limited OoD samples. Specifically, the generator explores OoD spaces and generates synthetic OoD samples using feedback from the discriminator, while the discriminator exploits both the observed and synthesized samples for OoD detection using a predefined Wasserstein score. We provide theoretical guarantees that the optimal solutions of our generative scheme are statistically achievable through adversarial training in empirical settings. We then demonstrate that the proposed method outperforms state-of-the-art techniques on various computer vision datasets and exhibits superior generalizability to unseen OoD data.
Rethinking Cost-sensitive Classification in Deep Learning via Adversarial Data Augmentation
Aug 24, 2022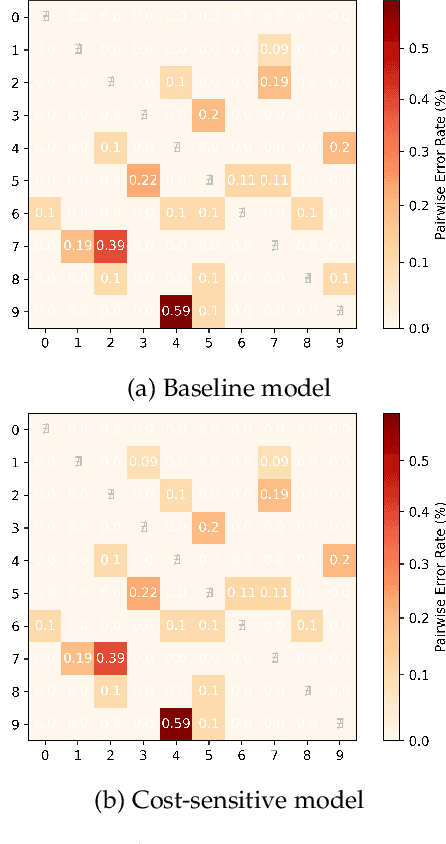

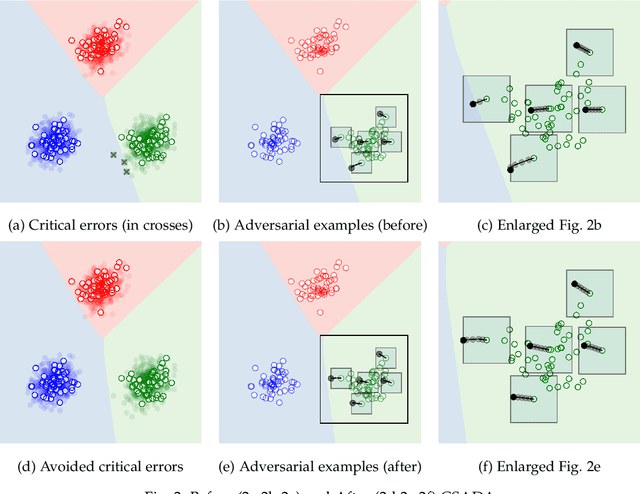
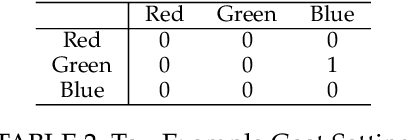
Cost-sensitive classification is critical in applications where misclassification errors widely vary in cost. However, over-parameterization poses fundamental challenges to the cost-sensitive modeling of deep neural networks (DNNs). The ability of a DNN to fully interpolate a training dataset can render a DNN, evaluated purely on the training set, ineffective in distinguishing a cost-sensitive solution from its overall accuracy maximization counterpart. This necessitates rethinking cost-sensitive classification in DNNs. To address this challenge, this paper proposes a cost-sensitive adversarial data augmentation (CSADA) framework to make over-parameterized models cost-sensitive. The overarching idea is to generate targeted adversarial examples that push the decision boundary in cost-aware directions. These targeted adversarial samples are generated by maximizing the probability of critical misclassifications and used to train a model with more conservative decisions on costly pairs. Experiments on well-known datasets and a pharmacy medication image (PMI) dataset made publicly available show that our method can effectively minimize the overall cost and reduce critical errors, while achieving comparable performance in terms of overall accuracy.
GIFAIR-FL: An Approach for Group and Individual Fairness in Federated Learning
Aug 05, 2021
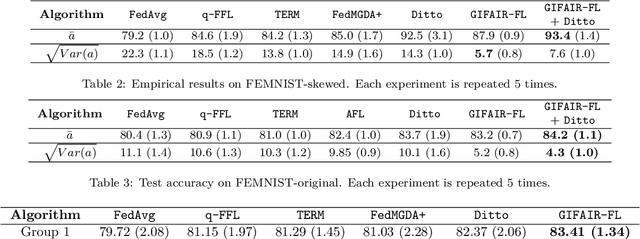
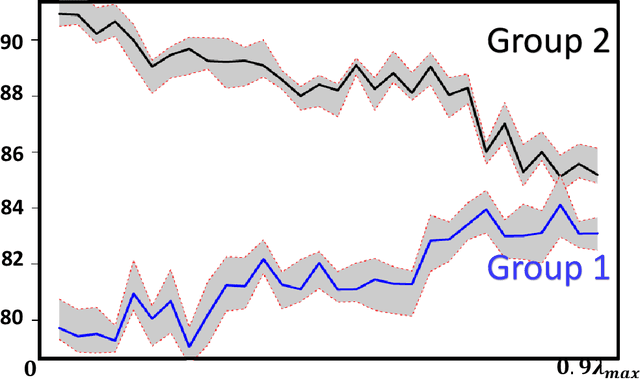
In this paper we propose \texttt{GIFAIR-FL}: an approach that imposes group and individual fairness to federated learning settings. By adding a regularization term, our algorithm penalizes the spread in the loss of client groups to drive the optimizer to fair solutions. Theoretically, we show convergence in non-convex and strongly convex settings. Our convergence guarantees hold for both $i.i.d.$ and non-$i.i.d.$ data. To demonstrate the empirical performance of our algorithm, we apply our method on image classification and text prediction tasks. Compared to existing algorithms, our method shows improved fairness results while retaining superior or similar prediction accuracy.
SALR: Sharpness-aware Learning Rates for Improved Generalization
Nov 10, 2020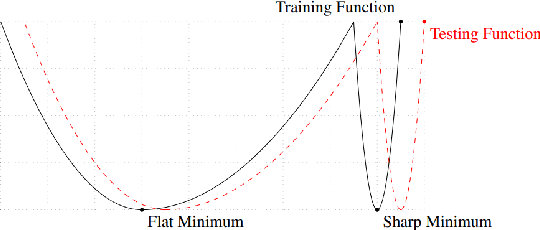
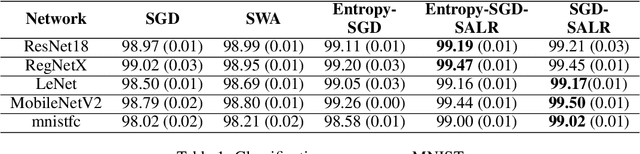
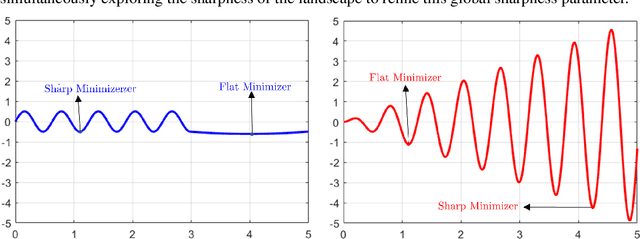
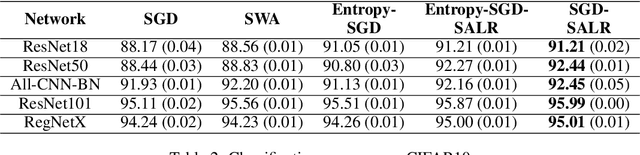
In an effort to improve generalization in deep learning, we propose SALR: a sharpness-aware learning rate update technique designed to recover flat minimizers. Our method dynamically updates the learning rate of gradient-based optimizers based on the local sharpness of the loss function. This allows optimizers to automatically increase learning rates at sharp valleys to increase the chance of escaping them. We demonstrate the effectiveness of SALR when adopted by various algorithms over a broad range of networks. Our experiments indicate that SALR improves generalization, converges faster, and drives solutions to significantly flatter regions.
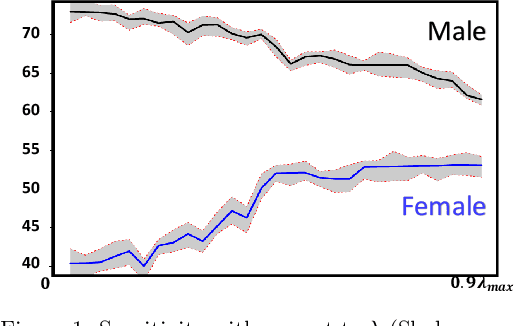
Rényi Fair Inference
Jun 28, 2019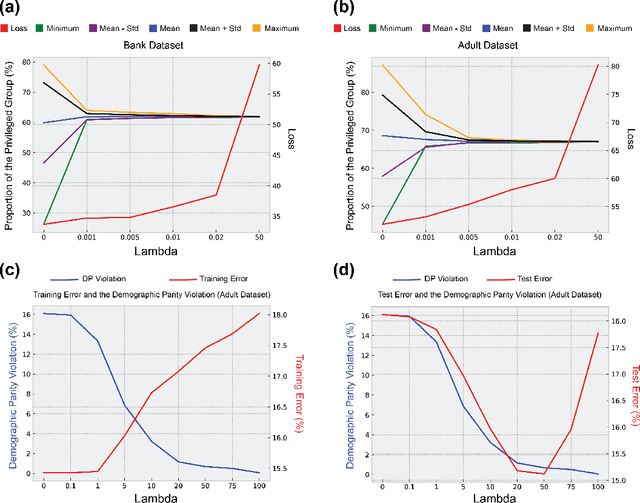
Machine learning algorithms have been increasingly deployed in critical automated decision-making systems that directly affect human lives. When these algorithms are only trained to minimize the training/test error, they could suffer from systematic discrimination against individuals based on their sensitive attributes such as gender or race. Recently, there has been a surge in machine learning society to develop algorithms for fair machine learning. In particular, many adversarial learning procedures have been proposed to impose fairness. Unfortunately, these algorithms either can only impose fairness up to first-order dependence between the variables, or they lack computational convergence guarantees. In this paper, we use R\'enyi correlation as a measure of fairness of machine learning models and develop a general training framework to impose fairness. In particular, we propose a min-max formulation which balances the accuracy and fairness when solved to optimality. For the case of discrete sensitive attributes, we suggest an iterative algorithm with theoretical convergence guarantee for solving the proposed min-max problem. Our algorithm and analysis are then specialized to fair classification and the fair clustering problem under disparate impact doctrine. Finally, the performance of the proposed R\'enyi fair inference framework is evaluated on Adult and Bank datasets.