 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient DP-SGD for LLMs with Randomized Clipping
May 24, 2026Large language models (LLMs) are trained on vast datasets that may contain sensitive information. Differential privacy (DP), the de facto standard for formal privacy guarantees, provides a principled framework for training LLMs with provable privacy protection. However, state-of-the-art DP training implementations rely on fast gradient clipping techniques with memory overhead $O(B \min\{T^2, d^2\})$, where $B$ is the batch size, $T$ is the sequence length, and $d$ is the model width. This becomes prohibitive as both model size and context length grow. We propose DP-SGD-RC, a novel variant of DP-SGD with randomized clipping that reduces memory and compute complexity. DP-SGD-RC leverages stochastic trace estimation methods, specifically Hutchinson's estimator[Hutchinson, 1989] and its improved variant, Hutch++[Meyer et al., 2021], to reduce the memory footprint of per-sample gradient norm estimation. We provide a tight privacy analysis showing that DP-SGD-RC achieves noise multipliers competitive with deterministic clipping. Experiments fine-tuning Llama~3.2-1B on long-context benchmarks spanning classification, question answering, and summarization tasks demonstrate that DP-SGD-RC matches baseline utility while significantly reducing memory and compute requirements.
Early Stopping for Large Reasoning Models via Confidence Dynamics
Apr 06, 2026Large reasoning models rely on long chain-of-thought generation to solve complex problems, but extended reasoning often incurs substantial computational cost and can even degrade performance due to overthinking. A key challenge is determining when the model should stop reasoning and produce the final answer. In this work, we study the confidence of intermediate answers during reasoning and observe two characteristic behaviors: correct reasoning trajectories often reach high-confidence answers early, while incorrect rollouts tend to produce long, unproductive reasoning traces and exhibit less reliable confidence dynamics. Motivated by these observations, we propose CoDE-Stop (Confidence Dynamics Early Stop), an early stopping method that leverages the dynamics of intermediate answer confidence to decide when to terminate reasoning, requiring no additional training and easily integrating into existing models. We evaluate CoDE-Stop on diverse reasoning and science benchmarks across multiple models. Compared to prior early stopping methods, it achieves a more favorable accuracy-compute tradeoff and reduces total token usage by 25-50% compared to standard full-length reasoning. In addition, we provide analyses of confidence dynamics during reasoning, offering insights into how confidence changes in both correct and incorrect trajectories.
Memory Caching: RNNs with Growing Memory
Feb 27, 2026Transformers have been established as the de-facto backbones for most recent advances in sequence modeling, mainly due to their growing memory capacity that scales with the context length. While plausible for retrieval tasks, it causes quadratic complexity and so has motivated recent studies to explore viable subquadratic recurrent alternatives. Despite showing promising preliminary results in diverse domains, such recurrent architectures underperform Transformers in recall-intensive tasks, often attributed to their fixed-size memory. In this paper, we introduce Memory Caching (MC), a simple yet effective technique that enhances recurrent models by caching checkpoints of their memory states (a.k.a. hidden states). Memory Caching allows the effective memory capacity of RNNs to grow with sequence length, offering a flexible trade-off that interpolates between the fixed memory (i.e., $O(L)$ complexity) of RNNs and the growing memory (i.e., $O(L^2)$ complexity) of Transformers. We propose four variants of MC, including gated aggregation and sparse selective mechanisms, and discuss their implications on both linear and deep memory modules. Our experimental results on language modeling, and long-context understanding tasks show that MC enhances the performance of recurrent models, supporting its effectiveness. The results of in-context recall tasks indicate that while Transformers achieve the best accuracy, our MC variants show competitive performance, close the gap with Transformers, and performs better than state-of-the-art recurrent models.
Less is More: Convergence Benefits of Fewer Data Weight Updates over Longer Horizon
Feb 23, 2026Data mixing--the strategic reweighting of training domains--is a critical component in training robust machine learning models. This problem is naturally formulated as a bilevel optimization task, where the outer loop optimizes domain weights to minimize validation loss, and the inner loop optimizes model parameters to minimize the weighted training loss. Classical bilevel optimization relies on hypergradients, which theoretically require the inner optimization to reach convergence. However, due to computational constraints, state-of-the-art methods use a finite, often small, number of inner update steps before updating the weights. The theoretical implications of this approximation are not well understood. In this work, we rigorously analyze the convergence behavior of data mixing with a finite number of inner steps $T$. We prove that the "greedy" practical approach of using $T=1$ can fail even in a simple quadratic example. Under a fixed parameter update budget $N$ and assuming the per-domain losses are strongly convex, we show that the optimal $T$ scales as $Θ(\log N)$ (resp., $Θ({(N \log N)}^{1/2})$) for the data mixing problem with access to full (resp., stochastic) gradients. We complement our theoretical results with proof-of-concept experiments.
Nested Learning: The Illusion of Deep Learning Architectures
Dec 31, 2025Despite the recent progresses, particularly in developing Language Models, there are fundamental challenges and unanswered questions about how such models can continually learn/memorize, self-improve, and find effective solutions. In this paper, we present a new learning paradigm, called Nested Learning (NL), that coherently represents a machine learning model with a set of nested, multi-level, and/or parallel optimization problems, each of which with its own context flow. Through the lenses of NL, existing deep learning methods learns from data through compressing their own context flow, and in-context learning naturally emerges in large models. NL suggests a philosophy to design more expressive learning algorithms with more levels, resulting in higher-order in-context learning and potentially unlocking effective continual learning capabilities. We advocate for NL by presenting three core contributions: (1) Expressive Optimizers: We show that known gradient-based optimizers, such as Adam, SGD with Momentum, etc., are in fact associative memory modules that aim to compress the gradients' information (by gradient descent). Building on this insight, we present other more expressive optimizers with deep memory and/or more powerful learning rules; (2) Self-Modifying Learning Module: Taking advantage of NL's insights on learning algorithms, we present a sequence model that learns how to modify itself by learning its own update algorithm; and (3) Continuum Memory System: We present a new formulation for memory system that generalizes the traditional viewpoint of long/short-term memory. Combining our self-modifying sequence model with the continuum memory system, we present a continual learning module, called Hope, showing promising results in language modeling, knowledge incorporation, and few-shot generalization tasks, continual learning, and long-context reasoning tasks.
Sampling and Loss Weights in Multi-Domain Training
Nov 10, 2025In the training of large deep neural networks, there is a need for vast amounts of training data. To meet this need, data is collected from multiple domains, such as Wikipedia and GitHub. These domains are heterogeneous in both data quality and the diversity of information they provide. This raises the question of how much we should rely on each domain. Several methods have attempted to address this issue by assigning sampling weights to each data domain using heuristics or approximations. As a first step toward a deeper understanding of the role of data mixing, this work revisits the problem by studying two kinds of weights: sampling weights, which control how much each domain contributes in a batch, and loss weights, which scale the loss from each domain during training. Through a rigorous study of linear regression, we show that these two weights play complementary roles. First, they can reduce the variance of gradient estimates in iterative methods such as stochastic gradient descent (SGD). Second, they can improve generalization performance by reducing the generalization gap. We provide both theoretical and empirical support for these claims. We further study the joint dynamics of sampling weights and loss weights, examining how they can be combined to capture both contributions.
TNT: Improving Chunkwise Training for Test-Time Memorization
Nov 10, 2025Recurrent neural networks (RNNs) with deep test-time memorization modules, such as Titans and TTT, represent a promising, linearly-scaling paradigm distinct from Transformers. While these expressive models do not yet match the peak performance of state-of-the-art Transformers, their potential has been largely untapped due to prohibitively slow training and low hardware utilization. Existing parallelization methods force a fundamental conflict governed by the chunksize hyperparameter: large chunks boost speed but degrade performance, necessitating a fixed, suboptimal compromise. To solve this challenge, we introduce TNT, a novel training paradigm that decouples training efficiency from inference performance through a two-stage process. Stage one is an efficiency-focused pre-training phase utilizing a hierarchical memory. A global module processes large, hardware-friendly chunks for long-range context, while multiple parallel local modules handle fine-grained details. Crucially, by periodically resetting local memory states, we break sequential dependencies to enable massive context parallelization. Stage two is a brief fine-tuning phase where only the local memory modules are adapted to a smaller, high-resolution chunksize, maximizing accuracy with minimal overhead. Evaluated on Titans and TTT models, TNT achieves a substantial acceleration in training speed-up to 17 times faster than the most accurate baseline configuration - while simultaneously improving model accuracy. This improvement removes a critical scalability barrier, establishing a practical foundation for developing expressive RNNs and facilitating future work to close the performance gap with Transformers.
Memory-Efficient Differentially Private Training with Gradient Random Projection
Jun 18, 2025Differential privacy (DP) protects sensitive data during neural network training, but standard methods like DP-Adam suffer from high memory overhead due to per-sample gradient clipping, limiting scalability. We introduce DP-GRAPE (Gradient RAndom ProjEction), a DP training method that significantly reduces memory usage while maintaining utility on par with first-order DP approaches. Rather than directly applying DP to GaLore, DP-GRAPE introduces three key modifications: (1) gradients are privatized after projection, (2) random Gaussian matrices replace SVD-based subspaces, and (3) projection is applied during backpropagation. These contributions eliminate the need for costly SVD computations, enable substantial memory savings, and lead to improved utility. Despite operating in lower-dimensional subspaces, our theoretical analysis shows that DP-GRAPE achieves a privacy-utility trade-off comparable to DP-SGD. Our extensive empirical experiments show that DP-GRAPE can reduce the memory footprint of DP training without sacrificing accuracy or training time. In particular, DP-GRAPE reduces memory usage by over 63% when pre-training Vision Transformers and over 70% when fine-tuning RoBERTa-Large as compared to DP-Adam, while achieving similar performance. We further demonstrate that DP-GRAPE scales to fine-tuning large models such as OPT with up to 6.7 billion parameters.
ATLAS: Learning to Optimally Memorize the Context at Test Time
May 29, 2025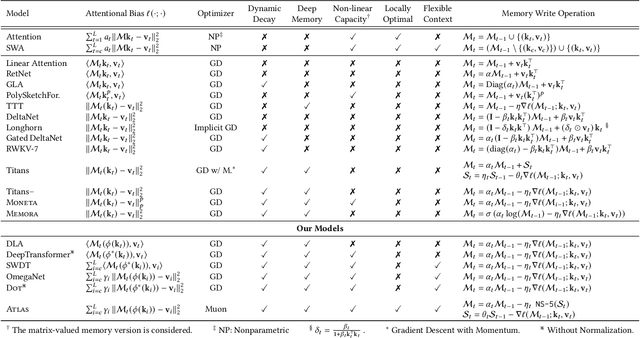
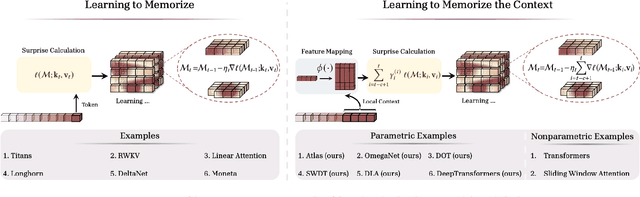
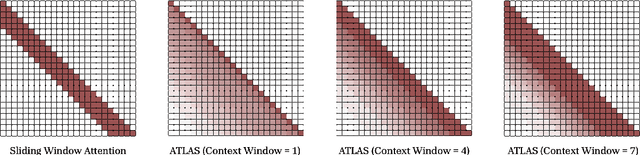
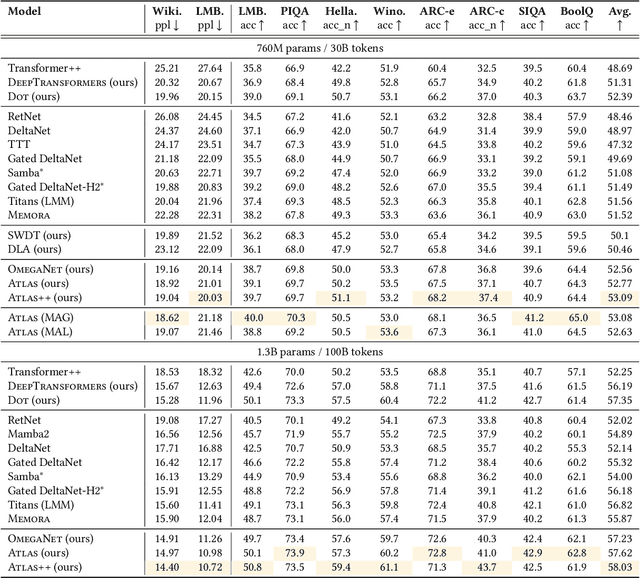
Transformers have been established as the most popular backbones in sequence modeling, mainly due to their effectiveness in in-context retrieval tasks and the ability to learn at scale. Their quadratic memory and time complexity, however, bound their applicability in longer sequences and so has motivated researchers to explore effective alternative architectures such as modern recurrent neural networks (a.k.a long-term recurrent memory module). Despite their recent success in diverse downstream tasks, they struggle in tasks that requires long context understanding and extrapolation to longer sequences. We observe that these shortcomings come from three disjoint aspects in their design: (1) limited memory capacity that is bounded by the architecture of memory and feature mapping of the input; (2) online nature of update, i.e., optimizing the memory only with respect to the last input; and (3) less expressive management of their fixed-size memory. To enhance all these three aspects, we present ATLAS, a long-term memory module with high capacity that learns to memorize the context by optimizing the memory based on the current and past tokens, overcoming the online nature of long-term memory models. Building on this insight, we present a new family of Transformer-like architectures, called DeepTransformers, that are strict generalizations of the original Transformer architecture. Our experimental results on language modeling, common-sense reasoning, recall-intensive, and long-context understanding tasks show that ATLAS surpasses the performance of Transformers and recent linear recurrent models. ATLAS further improves the long context performance of Titans, achieving +80\% accuracy in 10M context length of BABILong benchmark.
It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization
Apr 17, 2025


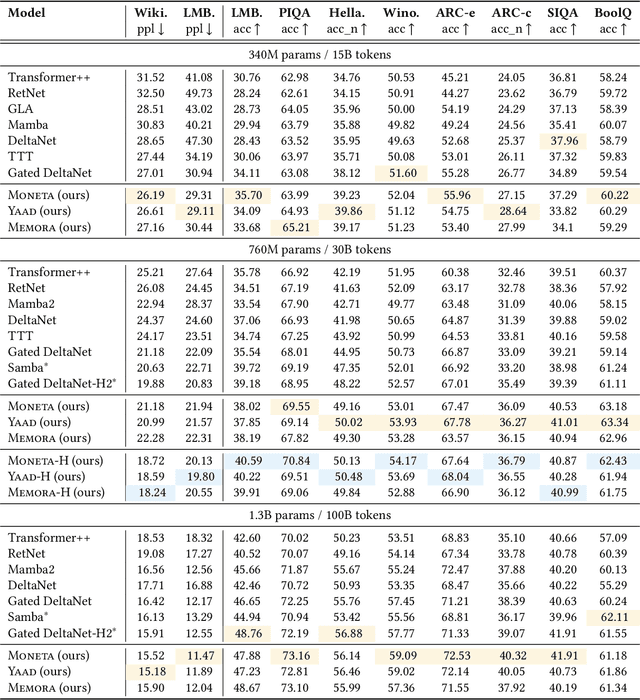
Designing efficient and effective architectural backbones has been in the core of research efforts to enhance the capability of foundation models. Inspired by the human cognitive phenomenon of attentional bias-the natural tendency to prioritize certain events or stimuli-we reconceptualize neural architectures, including Transformers, Titans, and modern linear recurrent neural networks as associative memory modules that learn a mapping of keys and values using an internal objective, referred to as attentional bias. Surprisingly, we observed that most existing sequence models leverage either (1) dot-product similarity, or (2) L2 regression objectives as their attentional bias. Going beyond these objectives, we present a set of alternative attentional bias configurations along with their effective approximations to stabilize their training procedure. We then reinterpret forgetting mechanisms in modern deep learning architectures as a form of retention regularization, providing a novel set of forget gates for sequence models. Building upon these insights, we present Miras, a general framework to design deep learning architectures based on four choices of: (i) associative memory architecture, (ii) attentional bias objective, (iii) retention gate, and (iv) memory learning algorithm. We present three novel sequence models-Moneta, Yaad, and Memora-that go beyond the power of existing linear RNNs while maintaining a fast parallelizable training process. Our experiments show different design choices in Miras yield models with varying strengths. For example, certain instances of Miras achieve exceptional performance in special tasks such as language modeling, commonsense reasoning, and recall intensive tasks, even outperforming Transformers and other modern linear recurrent models.