 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrellis: Learning to Compress Key-Value Memory in Attention Models
Dec 29, 2025Transformers, while powerful, suffer from quadratic computational complexity and the ever-growing Key-Value (KV) cache of the attention mechanism. This paper introduces Trellis, a novel Transformer architecture with bounded memory that learns how to compress its key-value memory dynamically at test time. Trellis replaces the standard KV cache with a fixed-size memory and train a two-pass recurrent compression mechanism to store new keys and values into memory. To achieve this, it leverages an online gradient descent procedure with a forget gate, enabling the compressed memory to be updated recursively while learning to retain important contextual information from incoming tokens at test time. Extensive experiments on language modeling, common-sense reasoning, recall-intensive tasks, and time series show that the proposed architecture outperforms strong baselines. Notably, its performance gains increase as the sequence length grows, highlighting its potential for long-context applications.
TNT: Improving Chunkwise Training for Test-Time Memorization
Nov 10, 2025Recurrent neural networks (RNNs) with deep test-time memorization modules, such as Titans and TTT, represent a promising, linearly-scaling paradigm distinct from Transformers. While these expressive models do not yet match the peak performance of state-of-the-art Transformers, their potential has been largely untapped due to prohibitively slow training and low hardware utilization. Existing parallelization methods force a fundamental conflict governed by the chunksize hyperparameter: large chunks boost speed but degrade performance, necessitating a fixed, suboptimal compromise. To solve this challenge, we introduce TNT, a novel training paradigm that decouples training efficiency from inference performance through a two-stage process. Stage one is an efficiency-focused pre-training phase utilizing a hierarchical memory. A global module processes large, hardware-friendly chunks for long-range context, while multiple parallel local modules handle fine-grained details. Crucially, by periodically resetting local memory states, we break sequential dependencies to enable massive context parallelization. Stage two is a brief fine-tuning phase where only the local memory modules are adapted to a smaller, high-resolution chunksize, maximizing accuracy with minimal overhead. Evaluated on Titans and TTT models, TNT achieves a substantial acceleration in training speed-up to 17 times faster than the most accurate baseline configuration - while simultaneously improving model accuracy. This improvement removes a critical scalability barrier, establishing a practical foundation for developing expressive RNNs and facilitating future work to close the performance gap with Transformers.
ATLAS: Learning to Optimally Memorize the Context at Test Time
May 29, 2025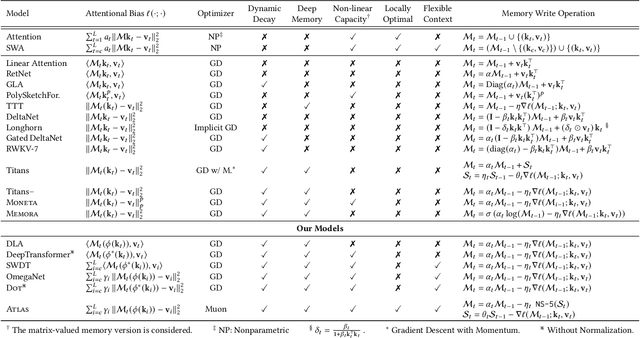
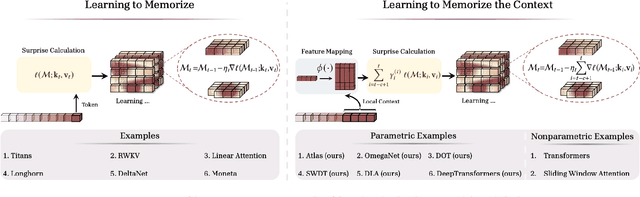
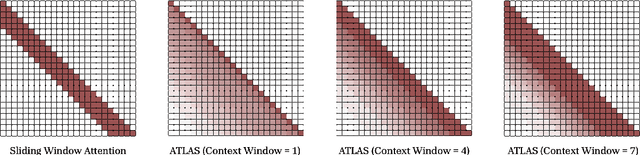
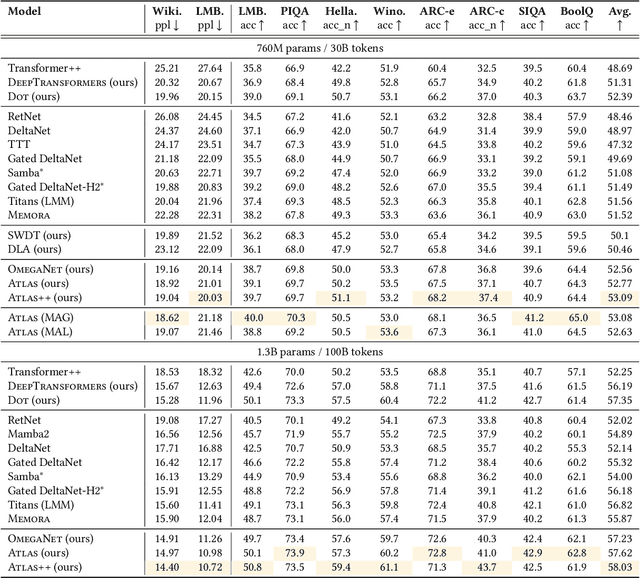
Transformers have been established as the most popular backbones in sequence modeling, mainly due to their effectiveness in in-context retrieval tasks and the ability to learn at scale. Their quadratic memory and time complexity, however, bound their applicability in longer sequences and so has motivated researchers to explore effective alternative architectures such as modern recurrent neural networks (a.k.a long-term recurrent memory module). Despite their recent success in diverse downstream tasks, they struggle in tasks that requires long context understanding and extrapolation to longer sequences. We observe that these shortcomings come from three disjoint aspects in their design: (1) limited memory capacity that is bounded by the architecture of memory and feature mapping of the input; (2) online nature of update, i.e., optimizing the memory only with respect to the last input; and (3) less expressive management of their fixed-size memory. To enhance all these three aspects, we present ATLAS, a long-term memory module with high capacity that learns to memorize the context by optimizing the memory based on the current and past tokens, overcoming the online nature of long-term memory models. Building on this insight, we present a new family of Transformer-like architectures, called DeepTransformers, that are strict generalizations of the original Transformer architecture. Our experimental results on language modeling, common-sense reasoning, recall-intensive, and long-context understanding tasks show that ATLAS surpasses the performance of Transformers and recent linear recurrent models. ATLAS further improves the long context performance of Titans, achieving +80\% accuracy in 10M context length of BABILong benchmark.
PolarQuant: Quantizing KV Caches with Polar Transformation
Feb 04, 2025Large language models (LLMs) require significant memory to store Key-Value (KV) embeddings in their KV cache, especially when handling long-range contexts. Quantization of these KV embeddings is a common technique to reduce memory consumption. This work introduces PolarQuant, a novel quantization method employing random preconditioning and polar transformation. Our method transforms the KV embeddings into polar coordinates using an efficient recursive algorithm and then quantizes resulting angles. Our key insight is that, after random preconditioning, the angles in the polar representation exhibit a tightly bounded and highly concentrated distribution with an analytically computable form. This nice distribution eliminates the need for explicit normalization, a step required by traditional quantization methods which introduces significant memory overhead because quantization parameters (e.g., zero point and scale) must be stored in full precision per each data block. PolarQuant bypasses this normalization step, enabling substantial memory savings. The long-context evaluation demonstrates that PolarQuant compresses the KV cache by over x4.2 while achieving the best quality scores compared to the state-of-the-art methods.
LevAttention: Time, Space, and Streaming Efficient Algorithm for Heavy Attentions
Oct 07, 2024A central problem related to transformers can be stated as follows: given two $n \times d$ matrices $Q$ and $K$, and a non-negative function $f$, define the matrix $A$ as follows: (1) apply the function $f$ to each entry of the $n \times n$ matrix $Q K^T$, and then (2) normalize each of the row sums of $A$ to be equal to $1$. The matrix $A$ can be computed in $O(n^2 d)$ time assuming $f$ can be applied to a number in constant time, but the quadratic dependence on $n$ is prohibitive in applications where it corresponds to long context lengths. For a large class of functions $f$, we show how to find all the ``large attention scores", i.e., entries of $A$ which are at least a positive value $\varepsilon$, in time with linear dependence on $n$ (i.e., $n \cdot \textrm{poly}(d/\varepsilon)$) for a positive parameter $\varepsilon > 0$. Our class of functions include all functions $f$ of the form $f(x) = |x|^p$, as explored recently in transformer models. Using recently developed tools from randomized numerical linear algebra, we prove that for any $K$, there is a ``universal set" $U \subset [n]$ of size independent of $n$, such that for any $Q$ and any row $i$, the large attention scores $A_{i,j}$ in row $i$ of $A$ all have $j \in U$. We also find $U$ in $n \cdot \textrm{poly}(d/\varepsilon)$ time. Notably, we (1) make no assumptions on the data, (2) our workspace does not grow with $n$, and (3) our algorithms can be computed in streaming and parallel settings. We call the attention mechanism that uses only the subset of keys in the universal set as LevAttention since our algorithm to identify the universal set $U$ is based on leverage scores. We empirically show the benefits of our scheme for vision transformers, showing how to train new models that use our universal set while training as well, showing that our model is able to consistently select ``important keys'' during training.
PolySketchFormer: Fast Transformers via Sketches for Polynomial Kernels
Oct 02, 2023



The quadratic complexity of attention in transformer architectures remains a big bottleneck in scaling up large foundation models for long context. In fact, recent theoretical results show the hardness of approximating the output of softmax attention mechanism in sub-quadratic time assuming Strong Exponential Time Hypothesis. In this paper, we show how to break this theoretical barrier by replacing softmax with a polynomial function and polynomial sketching. In particular we show that sketches for Polynomial Kernel from the randomized numerical linear algebra literature can be used to approximate the polynomial attention which leads to a significantly faster attention mechanism without assuming any sparse structure for the attention matrix that has been done in many previous works. In addition, we propose an efficient block-based algorithm that lets us apply the causal mask to the attention matrix without explicitly realizing the $n \times n$ attention matrix and compute the output of the polynomial attention mechanism in time linear in the context length. The block-based algorithm gives significant speedups over the \emph{cumulative sum} algorithm used by Performer to apply the causal mask to the attention matrix. These observations help us design \emph{PolySketchFormer}, a practical linear-time transformer architecture for language modeling with provable guarantees. We validate our design empirically by training language models with long context lengths. We first show that the eval perplexities of our models are comparable to that of models trained with softmax attention. We then show that for large context lengths our training times are significantly faster than FlashAttention.
Sub-quadratic Algorithms for Kernel Matrices via Kernel Density Estimation
Dec 01, 2022



Kernel matrices, as well as weighted graphs represented by them, are ubiquitous objects in machine learning, statistics and other related fields. The main drawback of using kernel methods (learning and inference using kernel matrices) is efficiency -- given $n$ input points, most kernel-based algorithms need to materialize the full $n \times n$ kernel matrix before performing any subsequent computation, thus incurring $\Omega(n^2)$ runtime. Breaking this quadratic barrier for various problems has therefore, been a subject of extensive research efforts. We break the quadratic barrier and obtain $\textit{subquadratic}$ time algorithms for several fundamental linear-algebraic and graph processing primitives, including approximating the top eigenvalue and eigenvector, spectral sparsification, solving linear systems, local clustering, low-rank approximation, arboricity estimation and counting weighted triangles. We build on the recent Kernel Density Estimation framework, which (after preprocessing in time subquadratic in $n$) can return estimates of row/column sums of the kernel matrix. In particular, we develop efficient reductions from $\textit{weighted vertex}$ and $\textit{weighted edge sampling}$ on kernel graphs, $\textit{simulating random walks}$ on kernel graphs, and $\textit{importance sampling}$ on matrices to Kernel Density Estimation and show that we can generate samples from these distributions in $\textit{sublinear}$ (in the support of the distribution) time. Our reductions are the central ingredient in each of our applications and we believe they may be of independent interest. We empirically demonstrate the efficacy of our algorithms on low-rank approximation (LRA) and spectral sparsification, where we observe a $\textbf{9x}$ decrease in the number of kernel evaluations over baselines for LRA and a $\textbf{41x}$ reduction in the graph size for spectral sparsification.
Sketching Algorithms and Lower Bounds for Ridge Regression
Apr 13, 2022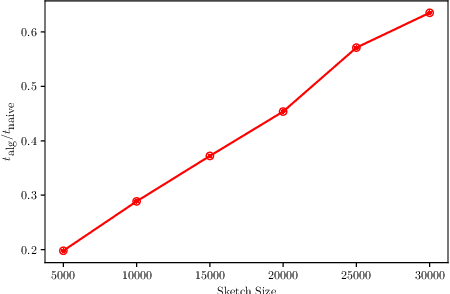
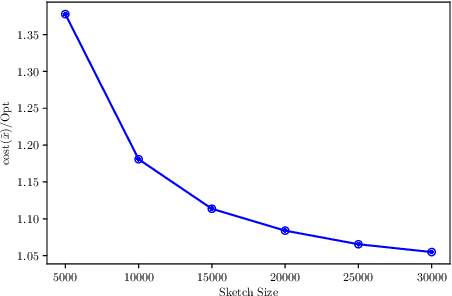
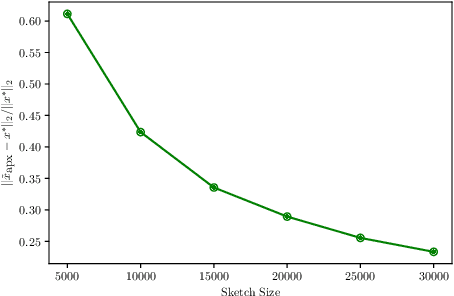
We give a sketching-based iterative algorithm that computes $1+\varepsilon$ approximate solutions for the ridge regression problem $\min_x \|{Ax-b}\|_2^2 +\lambda\|{x}\|_2^2$ where $A \in \mathbb{R}^{n \times d}$ with $d \ge n$. Our algorithm, for a constant number of iterations (requiring a constant number of passes over the input), improves upon earlier work of Chowdhury et al., by requiring that the sketching matrix only has a weaker Approximate Matrix Multiplication (AMM) guarantee that depends on $\epsilon$, along with a constant subspace embedding guarantee. The earlier work instead requires that the sketching matrix have a subspace embedding guarantee that depends on $\epsilon$. For example, to produce a $1+\varepsilon$ approximate solution in $1$ iteration, which requires $2$ passes over the input, our algorithm requires the OSNAP embedding to have $m= O(n\sigma^2/\lambda\varepsilon)$ rows with a sparsity parameter $s = O(\log(n))$, whereas the earlier algorithm of Chowdhury et al., with the same number of rows of OSNAP requires a sparsity $s = O(\sqrt{\sigma^2/\lambda\varepsilon} \cdot \log(n))$, where $\sigma = \|{A}\|_2$ is the spectral norm of the matrix $A$. We also show that this algorithm can be used to give faster algorithms for kernel ridge regression. Finally, we show that the sketch size required for our algorithm is essentially optimal for a natural framework of algorithms for ridge regression by proving lower bounds on oblivious sketching matrices for AMM. The sketch size lower bounds for AMM may be of independent interest.
Near-Optimal Algorithms for Linear Algebra in the Current Matrix Multiplication Time
Jul 16, 2021Currently, in the numerical linear algebra community, it is thought that to obtain nearly-optimal bounds for various problems such as rank computation, finding a maximal linearly independent subset of columns, regression, low rank approximation, maximum matching on general graphs and linear matroid union, one would need to resolve the main open question of Nelson and Nguyen (FOCS, 2013) regarding the logarithmic factors in the sketching dimension for existing constant factor approximation oblivious subspace embeddings. We show how to bypass this question using a refined sketching technique, and obtain optimal or nearly optimal bounds for these problems. A key technique we use is an explicit mapping of Indyk based on uncertainty principles and extractors, which after first applying known oblivious subspace embeddings, allows us to quickly spread out the mass of the vector so that sampling is now effective, and we avoid a logarithmic factor that is standard in the sketching dimension resulting from matrix Chernoff bounds. For the fundamental problems of rank computation and finding a linearly independent subset of columns, our algorithms improve Cheung, Kwok, and Lau (JACM, 2013) and are optimal to within a constant factor and a $\log\log(n)$-factor, respectively. Further, for constant factor regression and low rank approximation we give the first optimal algorithms, for the current matrix multiplication exponent.