 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Program Representations for Food Images and Cooking Recipes
Mar 30, 2022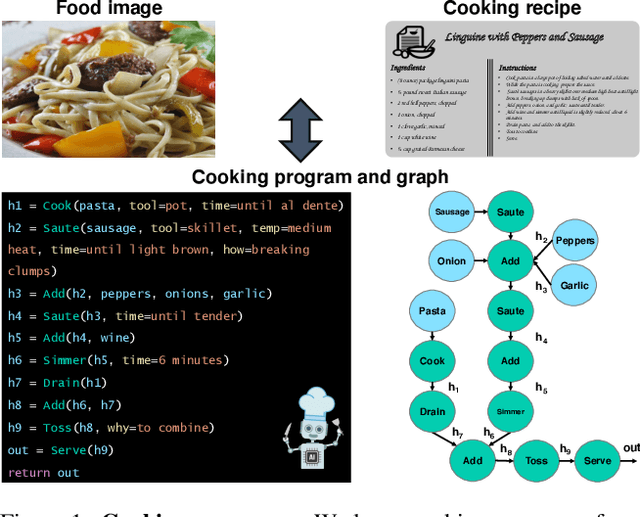
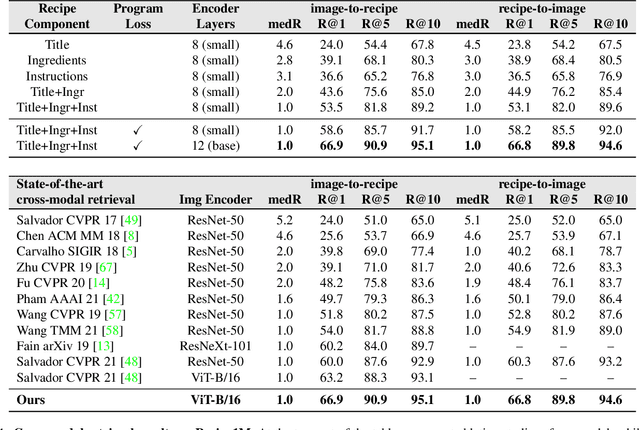
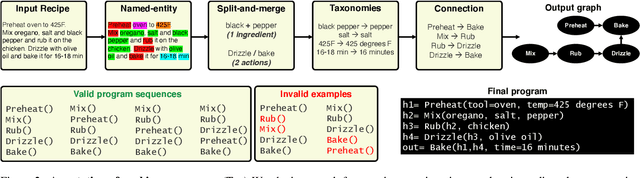
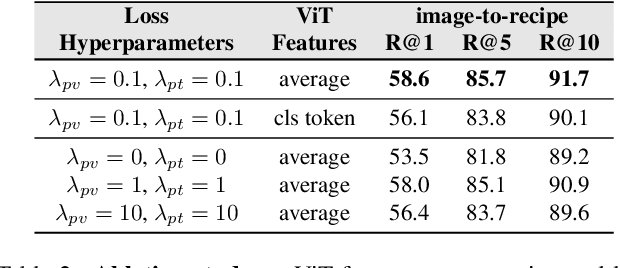
In this paper, we are interested in modeling a how-to instructional procedure, such as a cooking recipe, with a meaningful and rich high-level representation. Specifically, we propose to represent cooking recipes and food images as cooking programs. Programs provide a structured representation of the task, capturing cooking semantics and sequential relationships of actions in the form of a graph. This allows them to be easily manipulated by users and executed by agents. To this end, we build a model that is trained to learn a joint embedding between recipes and food images via self-supervision and jointly generate a program from this embedding as a sequence. To validate our idea, we crowdsource programs for cooking recipes and show that: (a) projecting the image-recipe embeddings into programs leads to better cross-modal retrieval results; (b) generating programs from images leads to better recognition results compared to predicting raw cooking instructions; and (c) we can generate food images by manipulating programs via optimizing the latent code of a GAN. Code, data, and models are available online.
Near-Optimal Algorithms for Linear Algebra in the Current Matrix Multiplication Time
Jul 16, 2021Currently, in the numerical linear algebra community, it is thought that to obtain nearly-optimal bounds for various problems such as rank computation, finding a maximal linearly independent subset of columns, regression, low rank approximation, maximum matching on general graphs and linear matroid union, one would need to resolve the main open question of Nelson and Nguyen (FOCS, 2013) regarding the logarithmic factors in the sketching dimension for existing constant factor approximation oblivious subspace embeddings. We show how to bypass this question using a refined sketching technique, and obtain optimal or nearly optimal bounds for these problems. A key technique we use is an explicit mapping of Indyk based on uncertainty principles and extractors, which after first applying known oblivious subspace embeddings, allows us to quickly spread out the mass of the vector so that sampling is now effective, and we avoid a logarithmic factor that is standard in the sketching dimension resulting from matrix Chernoff bounds. For the fundamental problems of rank computation and finding a linearly independent subset of columns, our algorithms improve Cheung, Kwok, and Lau (JACM, 2013) and are optimal to within a constant factor and a $\log\log(n)$-factor, respectively. Further, for constant factor regression and low rank approximation we give the first optimal algorithms, for the current matrix multiplication exponent.
Quantum-Inspired Algorithms from Randomized Numerical Linear Algebra
Nov 12, 2020
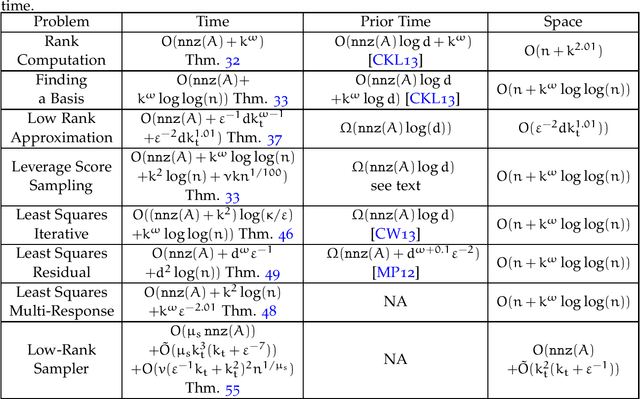
We create classical (non-quantum) dynamic data structures supporting queries for recommender systems and least-squares regression that are comparable to their quantum analogues. De-quantizing such algorithms has received a flurry of attention in recent years; we obtain sharper bounds for these problems. More significantly, we achieve these improvements by arguing that the previous quantum-inspired algorithms for these problems are doing leverage or ridge-leverage score sampling in disguise. With this recognition, we are able to employ the large body of work in numerical linear algebra to obtain algorithms for these problems that are simpler and faster than existing approaches. We also consider static data structures for the above problems, and obtain close-to-optimal bounds for them. To do this, we introduce a new randomized transform, the Gaussian Randomized Hadamard Transform (GRHT). It was thought in the numerical linear algebra community that to obtain nearly-optimal bounds for various problems such as rank computation, finding a maximal linearly independent subset of columns, regression, low rank approximation, maximum matching on general graphs and linear matroid union, that one would need to resolve the main open question of Nelson and Nguyen (FOCS, 2013) regarding the logarithmic factors in existing oblivious subspace embeddings. We bypass this question, using GRHT, and obtain optimal or nearly-optimal bounds for these problems. For the fundamental problems of rank computation and finding a linearly independent subset of columns, our algorithms improve Cheung, Kwok, and Lau (JACM, 2013) and are optimal to within a constant factor and a $\log\log(n)$-factor, respectively. Further, for constant factor regression and low rank approximation we give the first optimal algorithms, for the current matrix multiplication exponent.
ARDA: Automatic Relational Data Augmentation for Machine Learning
Mar 21, 2020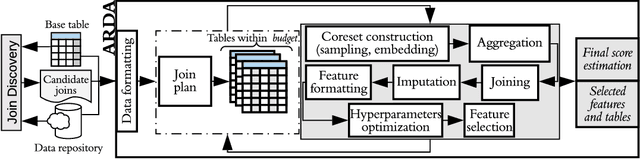
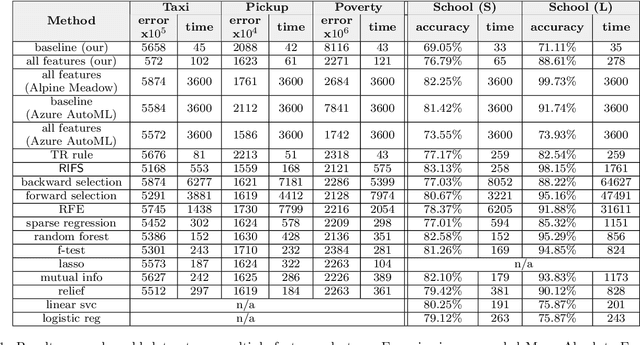
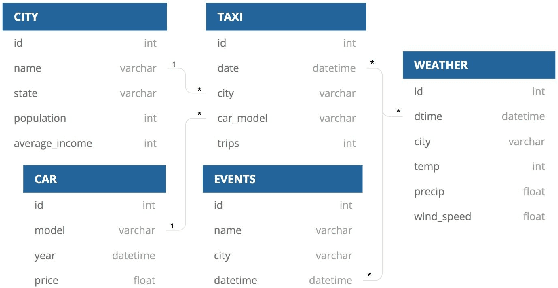
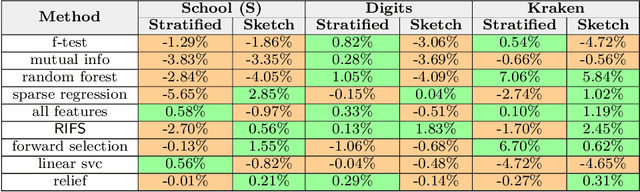
Automatic machine learning (\AML) is a family of techniques to automate the process of training predictive models, aiming to both improve performance and make machine learning more accessible. While many recent works have focused on aspects of the machine learning pipeline like model selection, hyperparameter tuning, and feature selection, relatively few works have focused on automatic data augmentation. Automatic data augmentation involves finding new features relevant to the user's predictive task with minimal ``human-in-the-loop'' involvement. We present \system, an end-to-end system that takes as input a dataset and a data repository, and outputs an augmented data set such that training a predictive model on this augmented dataset results in improved performance. Our system has two distinct components: (1) a framework to search and join data with the input data, based on various attributes of the input, and (2) an efficient feature selection algorithm that prunes out noisy or irrelevant features from the resulting join. We perform an extensive empirical evaluation of different system components and benchmark our feature selection algorithm on real-world datasets.
Robust and Sample Optimal Algorithms for PSD Low-Rank Approximation
Jan 02, 2020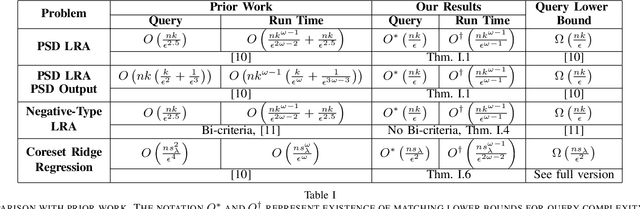
Recently, Musco and Woodruff (FOCS, 2017) showed that given an $n \times n$ positive semidefinite (PSD) matrix $A$, it is possible to compute a relative-error $(1+\epsilon)$-approximate low-rank approximation to $A$ by querying $\widetilde{O}(nk/\epsilon^{2.5})$ entries of $A$ in time $\widetilde{O}(nk/\epsilon^{2.5} +n k^{\omega-1}/\epsilon^{2(\omega-1)})$. They also showed that any relative-error low-rank approximation algorithm must query $\widetilde{\Omega}(nk/\epsilon)$ entries of $A$, and closing this gap is an important open question. Our main result is to resolve this question by showing an algorithm that queries an optimal $\widetilde{O}(nk/\epsilon)$ entries of $A$ and outputs a relative-error low-rank approximation in $\widetilde{O}(n\cdot(k/\epsilon)^{\omega-1})$ time. Note, our running time improves that of Musco and Woodruff, and matches the information-theoretic lower bound if the matrix-multiplication exponent $\omega$ is $2$. Next, we introduce a new robust low-rank approximation model which captures PSD matrices that have been corrupted with noise. We assume that the Frobenius norm of the corruption is bounded. Here, we relax the notion of approximation to additive-error, since it is information-theoretically impossible to obtain a relative-error approximation in this setting. While a sample complexity lower bound precludes sublinear algorithms for arbitrary PSD matrices, we provide the first sublinear time and query algorithms when the corruption on the diagonal entries is bounded. As a special case, we show sample-optimal sublinear time algorithms for low-rank approximation of correlation matrices corrupted by noise.