 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Adding Metacognitive Requirements in Support of AI Feedback in Practice Exams Transforms Student Learning Behaviors
May 19, 2025Providing personalized, detailed feedback at scale in large undergraduate STEM courses remains a persistent challenge. We present an empirically evaluated practice exam system that integrates AI generated feedback with targeted textbook references, deployed in a large introductory biology course. Our system encourages metacognitive behavior by asking students to explain their answers and declare their confidence. It uses OpenAI's GPT-4o to generate personalized feedback based on this information, while directing them to relevant textbook sections. Through interaction logs from consenting participants across three midterms (541, 342, and 413 students respectively), totaling 28,313 question-student interactions across 146 learning objectives, along with 279 surveys and 23 interviews, we examined the system's impact on learning outcomes and engagement. Across all midterms, feedback types showed no statistically significant performance differences, though some trends suggested potential benefits. The most substantial impact came from the required confidence ratings and explanations, which students reported transferring to their actual exam strategies. About 40 percent of students engaged with textbook references when prompted by feedback -- far higher than traditional reading rates. Survey data revealed high satisfaction (mean rating 4.1 of 5), with 82.1 percent reporting increased confidence on practiced midterm topics, and 73.4 percent indicating they could recall and apply specific concepts. Our findings suggest that embedding structured reflection requirements may be more impactful than sophisticated feedback mechanisms.
Conceptualizing Machine Learning for Dynamic Information Retrieval of Electronic Health Record Notes
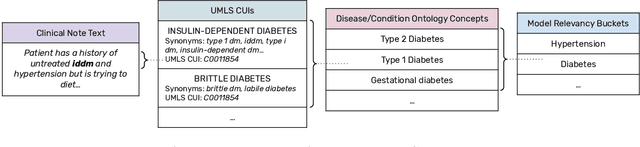
Aug 09, 2023The large amount of time clinicians spend sifting through patient notes and documenting in electronic health records (EHRs) is a leading cause of clinician burnout. By proactively and dynamically retrieving relevant notes during the documentation process, we can reduce the effort required to find relevant patient history. In this work, we conceptualize the use of EHR audit logs for machine learning as a source of supervision of note relevance in a specific clinical context, at a particular point in time. Our evaluation focuses on the dynamic retrieval in the emergency department, a high acuity setting with unique patterns of information retrieval and note writing. We show that our methods can achieve an AUC of 0.963 for predicting which notes will be read in an individual note writing session. We additionally conduct a user study with several clinicians and find that our framework can help clinicians retrieve relevant information more efficiently. Demonstrating that our framework and methods can perform well in this demanding setting is a promising proof of concept that they will translate to other clinical settings and data modalities (e.g., labs, medications, imaging).
Fast, Structured Clinical Documentation via Contextual Autocomplete
Jul 29, 2020


We present a system that uses a learned autocompletion mechanism to facilitate rapid creation of semi-structured clinical documentation. We dynamically suggest relevant clinical concepts as a doctor drafts a note by leveraging features from both unstructured and structured medical data. By constraining our architecture to shallow neural networks, we are able to make these suggestions in real time. Furthermore, as our algorithm is used to write a note, we can automatically annotate the documentation with clean labels of clinical concepts drawn from medical vocabularies, making notes more structured and readable for physicians, patients, and future algorithms. To our knowledge, this system is the only machine learning-based documentation utility for clinical notes deployed in a live hospital setting, and it reduces keystroke burden of clinical concepts by 67% in real environments.
ARDA: Automatic Relational Data Augmentation for Machine Learning
Mar 21, 2020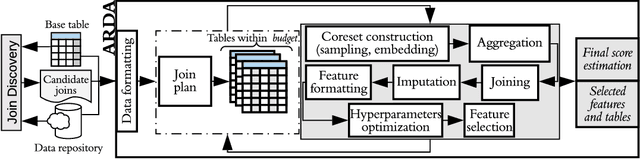
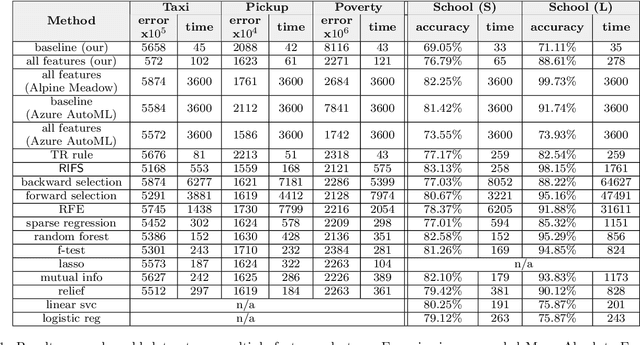
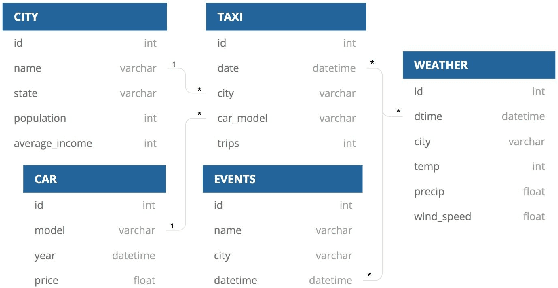
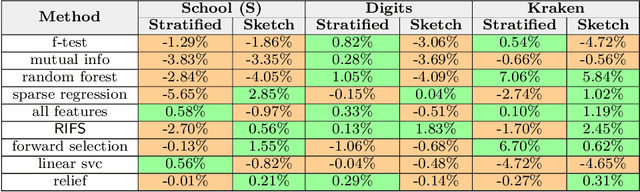
Automatic machine learning (\AML) is a family of techniques to automate the process of training predictive models, aiming to both improve performance and make machine learning more accessible. While many recent works have focused on aspects of the machine learning pipeline like model selection, hyperparameter tuning, and feature selection, relatively few works have focused on automatic data augmentation. Automatic data augmentation involves finding new features relevant to the user's predictive task with minimal ``human-in-the-loop'' involvement. We present \system, an end-to-end system that takes as input a dataset and a data repository, and outputs an augmented data set such that training a predictive model on this augmented dataset results in improved performance. Our system has two distinct components: (1) a framework to search and join data with the input data, based on various attributes of the input, and (2) an efficient feature selection algorithm that prunes out noisy or irrelevant features from the resulting join. We perform an extensive empirical evaluation of different system components and benchmark our feature selection algorithm on real-world datasets.
Matroids Hitting Sets and Unsupervised Dependency Grammar Induction
Jul 15, 2017



This paper formulates a novel problem on graphs: find the minimal subset of edges in a fully connected graph, such that the resulting graph contains all spanning trees for a set of specifed sub-graphs. This formulation is motivated by an un-supervised grammar induction problem from computational linguistics. We present a reduction to some known problems and algorithms from graph theory, provide computational complexity results, and describe an approximation algorithm.