 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of Pneuma-Seeker: Agentic System for Reifying and Fulfilling Information Needs on Tabular Data
Apr 15, 2026Data analysts working with relational data often start with vague or underspecified questions and refine them iteratively as they explore the data. To support this iterative process, we demonstrate Pneuma-Seeker, a system that reifies a user's information need as explicit, inspectable relational specifications, enabling iterative refinement of the information need, targeted data discovery, and provenance-aware execution. Through two real-world procurement use cases, we show how Pneuma-Seeker leverages LLMs as transparent, interactive analytical collaborators rather than opaque answer engines.
Pneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System
Apr 12, 2025Finding relevant tables among databases, lakes, and repositories is the first step in extracting value from data. Such a task remains difficult because assessing whether a table is relevant to a problem does not always depend only on its content but also on the context, which is usually tribal knowledge known to the individual or team. While tools like data catalogs and academic data discovery systems target this problem, they rely on keyword search or more complex interfaces, limiting non-technical users' ability to find relevant data. The advent of large language models (LLMs) offers a unique opportunity for users to ask questions directly in natural language, making dataset discovery more intuitive, accessible, and efficient. In this paper, we introduce Pneuma, a retrieval-augmented generation (RAG) system designed to efficiently and effectively discover tabular data. Pneuma leverages large language models (LLMs) for both table representation and table retrieval. For table representation, Pneuma preserves schema and row-level information to ensure comprehensive data understanding. For table retrieval, Pneuma augments LLMs with traditional information retrieval techniques, such as full-text and vector search, harnessing the strengths of both to improve retrieval performance. To evaluate Pneuma, we generate comprehensive benchmarks that simulate table discovery workload on six real-world datasets including enterprise data, scientific databases, warehousing data, and open data. Our results demonstrate that Pneuma outperforms widely used table search systems (such as full-text search and state-of-the-art RAG systems) in accuracy and resource efficiency.
A Survey on Data Markets
Nov 09, 2024



Data is the new oil of the 21st century. The growing trend of trading data for greater welfare has led to the emergence of data markets. A data market is any mechanism whereby the exchange of data products including datasets and data derivatives takes place as a result of data buyers and data sellers being in contact with one another, either directly or through mediating agents. It serves as a coordinating mechanism by which several functions, including the pricing and the distribution of data as the most important ones, interact to make the value of data fully exploited and enhanced. In this article, we present a comprehensive survey of this important and emerging direction from the aspects of data search, data productization, data transaction, data pricing, revenue allocation as well as privacy, security, and trust issues. We also investigate the government policies and industry status of data markets across different countries and different domains. Finally, we identify the unresolved challenges and discuss possible future directions for the development of data markets.
FabricQA-Extractor: A Question Answering System to Extract Information from Documents using Natural Language Questions
Aug 17, 2024Reading comprehension models answer questions posed in natural language when provided with a short passage of text. They present an opportunity to address a long-standing challenge in data management: the extraction of structured data from unstructured text. Consequently, several approaches are using these models to perform information extraction. However, these modern approaches leave an opportunity behind because they do not exploit the relational structure of the target extraction table. In this paper, we introduce a new model, Relation Coherence, that exploits knowledge of the relational structure to improve the extraction quality. We incorporate the Relation Coherence model as part of FabricQA-Extractor, an end-to-end system we built from scratch to conduct large scale extraction tasks over millions of documents. We demonstrate on two datasets with millions of passages that Relation Coherence boosts extraction performance and evaluate FabricQA-Extractor on large scale datasets.
A Data-Centric Online Market for Machine Learning: From Discovery to Pricing
Oct 27, 2023



Data fuels machine learning (ML) - rich and high-quality training data is essential to the success of ML. However, to transform ML from the race among a few large corporations to an accessible technology that serves numerous normal users' data analysis requests, there still exist important challenges. One gap we observed is that many ML users can benefit from new data that other data owners possess, whereas these data owners sit on piles of data without knowing who can benefit from it. This gap creates the opportunity for building an online market that can automatically connect supply with demand. While online matching markets are prevalent (e.g., ride-hailing systems), designing a data-centric market for ML exhibits many unprecedented challenges. This paper develops new techniques to tackle two core challenges in designing such a market: (a) to efficiently match demand with supply, we design an algorithm to automatically discover useful data for any ML task from a pool of thousands of datasets, achieving high-quality matching between ML models and data; (b) to encourage market participation of ML users without much ML expertise, we design a new pricing mechanism for selling data-augmented ML models. Furthermore, our market is designed to be API-compatible with existing online ML markets like Vertex AI and Sagemaker, making it easy to use while providing better results due to joint data and model search. We envision that the synergy of our data and model discovery algorithm and pricing mechanism will be an important step towards building a new data-centric online market that serves ML users effectively.
Addressing Budget Allocation and Revenue Allocation in Data Market Environments Using an Adaptive Sampling Algorithm
Jun 05, 2023



High-quality machine learning models are dependent on access to high-quality training data. When the data are not already available, it is tedious and costly to obtain them. Data markets help with identifying valuable training data: model consumers pay to train a model, the market uses that budget to identify data and train the model (the budget allocation problem), and finally the market compensates data providers according to their data contribution (revenue allocation problem). For example, a bank could pay the data market to access data from other financial institutions to train a fraud detection model. Compensating data contributors requires understanding data's contribution to the model; recent efforts to solve this revenue allocation problem based on the Shapley value are inefficient to lead to practical data markets. In this paper, we introduce a new algorithm to solve budget allocation and revenue allocation problems simultaneously in linear time. The new algorithm employs an adaptive sampling process that selects data from those providers who are contributing the most to the model. Better data means that the algorithm accesses those providers more often, and more frequent accesses corresponds to higher compensation. Furthermore, the algorithm can be deployed in both centralized and federated scenarios, boosting its applicability. We provide theoretical guarantees for the algorithm that show the budget is used efficiently and the properties of revenue allocation are similar to Shapley's. Finally, we conduct an empirical evaluation to show the performance of the algorithm in practical scenarios and when compared to other baselines. Overall, we believe that the new algorithm paves the way for the implementation of practical data markets.
METAM: Goal-Oriented Data Discovery
Apr 18, 2023Data is a central component of machine learning and causal inference tasks. The availability of large amounts of data from sources such as open data repositories, data lakes and data marketplaces creates an opportunity to augment data and boost those tasks' performance. However, augmentation techniques rely on a user manually discovering and shortlisting useful candidate augmentations. Existing solutions do not leverage the synergy between discovery and augmentation, thus under exploiting data. In this paper, we introduce METAM, a novel goal-oriented framework that queries the downstream task with a candidate dataset, forming a feedback loop that automatically steers the discovery and augmentation process. To select candidates efficiently, METAM leverages properties of the: i) data, ii) utility function, and iii) solution set size. We show METAM's theoretical guarantees and demonstrate those empirically on a broad set of tasks. All in all, we demonstrate the promise of goal-oriented data discovery to modern data science applications.
Data Discovery using Natural Language Questions via a Self-Supervised Approach
Jan 09, 2023Data discovery systems help users identify relevant data among large table collections. Users express their discovery needs with a program or a set of keywords. Users may express complex queries using programs but it requires expertise. Keyword search is accessible to a larger audience but limits the types of queries supported. An interesting approach is learned discovery systems which find tables given natural language questions. Unfortunately, these systems require a training dataset for each table collection. And because collecting training data is expensive, this limits their adoption. In this paper, we introduce a self-supervised approach to assemble training datasets and train learned discovery systems without human intervention. It requires addressing several challenges, including the design of self-supervised strategies for data discovery, table representation strategies to feed to the models, and relevance models that work well with the synthetically generated questions. We combine all the above contributions into a system, S2LD, that solves the problem end to end. The evaluation results demonstrate the new techniques outperform state-of-the-art approaches on wellknown benchmarks. All in all, the technique is a stepping stone towards building learned discovery systems. The code is open-sourced at https://github.com/TheDataStation/open_table_discovery.
ARDA: Automatic Relational Data Augmentation for Machine Learning
Mar 21, 2020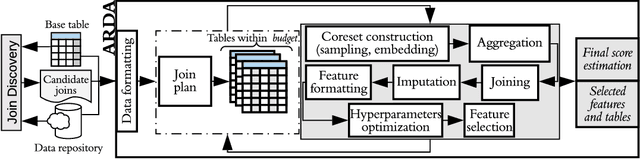
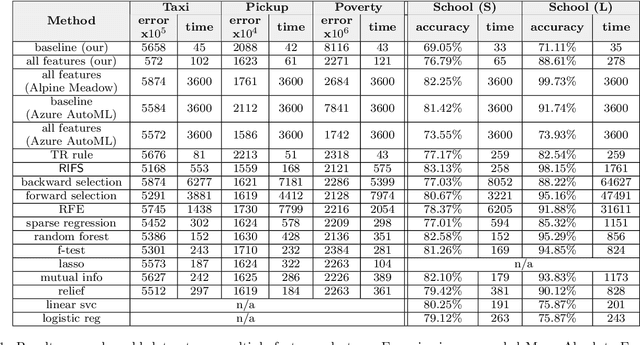
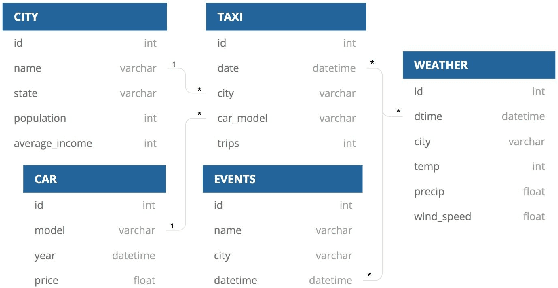
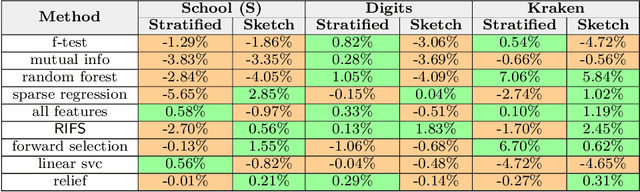
Automatic machine learning (\AML) is a family of techniques to automate the process of training predictive models, aiming to both improve performance and make machine learning more accessible. While many recent works have focused on aspects of the machine learning pipeline like model selection, hyperparameter tuning, and feature selection, relatively few works have focused on automatic data augmentation. Automatic data augmentation involves finding new features relevant to the user's predictive task with minimal ``human-in-the-loop'' involvement. We present \system, an end-to-end system that takes as input a dataset and a data repository, and outputs an augmented data set such that training a predictive model on this augmented dataset results in improved performance. Our system has two distinct components: (1) a framework to search and join data with the input data, based on various attributes of the input, and (2) an efficient feature selection algorithm that prunes out noisy or irrelevant features from the resulting join. We perform an extensive empirical evaluation of different system components and benchmark our feature selection algorithm on real-world datasets.
Smallify: Learning Network Size while Training
Jun 10, 2018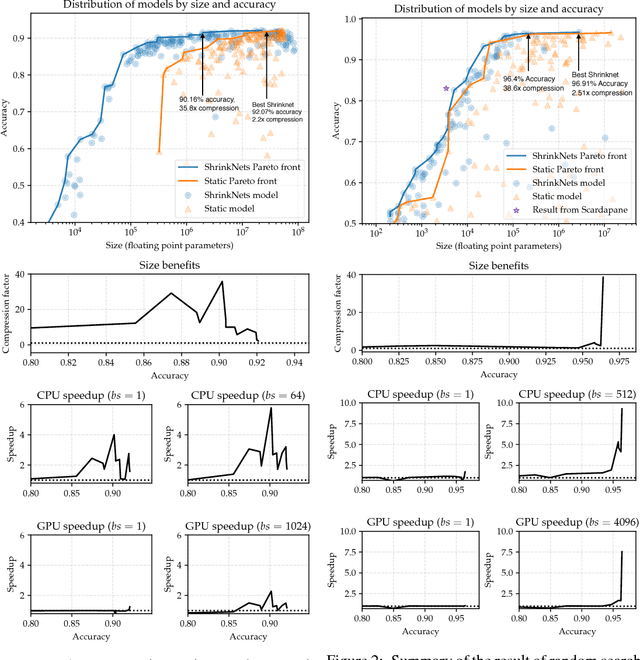
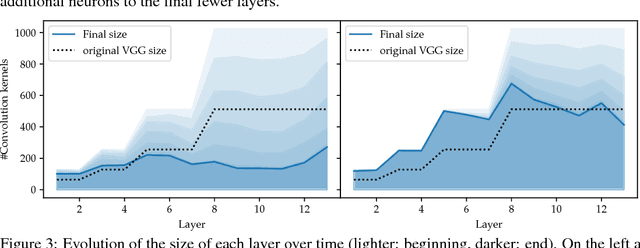
As neural networks become widely deployed in different applications and on different hardware, it has become increasingly important to optimize inference time and model size along with model accuracy. Most current techniques optimize model size, model accuracy and inference time in different stages, resulting in suboptimal results and computational inefficiency. In this work, we propose a new technique called Smallify that optimizes all three of these metrics at the same time. Specifically we present a new method to simultaneously optimize network size and model performance by neuron-level pruning during training. Neuron-level pruning not only produces much smaller networks but also produces dense weight matrices that are amenable to efficient inference. By applying our technique to convolutional as well as fully connected models, we show that Smallify can reduce network size by 35X with a 6X improvement in inference time with similar accuracy as models found by traditional training techniques.