 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System
Apr 12, 2025Finding relevant tables among databases, lakes, and repositories is the first step in extracting value from data. Such a task remains difficult because assessing whether a table is relevant to a problem does not always depend only on its content but also on the context, which is usually tribal knowledge known to the individual or team. While tools like data catalogs and academic data discovery systems target this problem, they rely on keyword search or more complex interfaces, limiting non-technical users' ability to find relevant data. The advent of large language models (LLMs) offers a unique opportunity for users to ask questions directly in natural language, making dataset discovery more intuitive, accessible, and efficient. In this paper, we introduce Pneuma, a retrieval-augmented generation (RAG) system designed to efficiently and effectively discover tabular data. Pneuma leverages large language models (LLMs) for both table representation and table retrieval. For table representation, Pneuma preserves schema and row-level information to ensure comprehensive data understanding. For table retrieval, Pneuma augments LLMs with traditional information retrieval techniques, such as full-text and vector search, harnessing the strengths of both to improve retrieval performance. To evaluate Pneuma, we generate comprehensive benchmarks that simulate table discovery workload on six real-world datasets including enterprise data, scientific databases, warehousing data, and open data. Our results demonstrate that Pneuma outperforms widely used table search systems (such as full-text search and state-of-the-art RAG systems) in accuracy and resource efficiency.
Bayesian Optimisation for Mixed-Variable Inputs using Value Proposals
Feb 17, 2022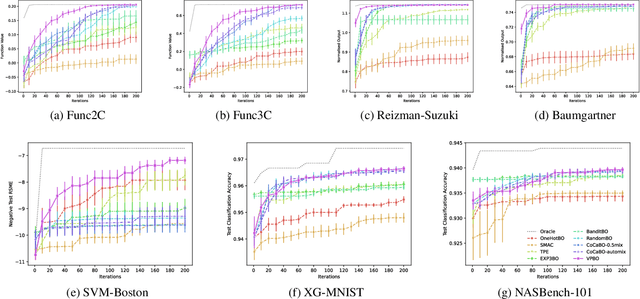
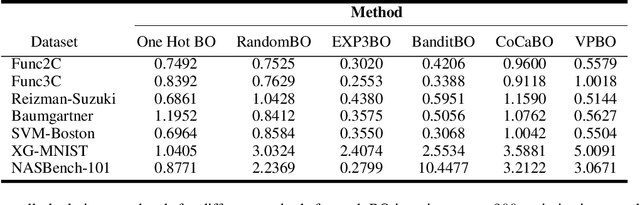
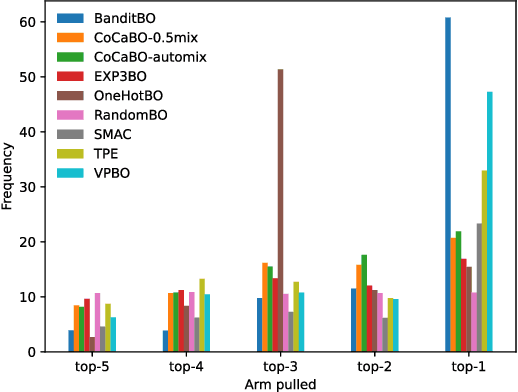
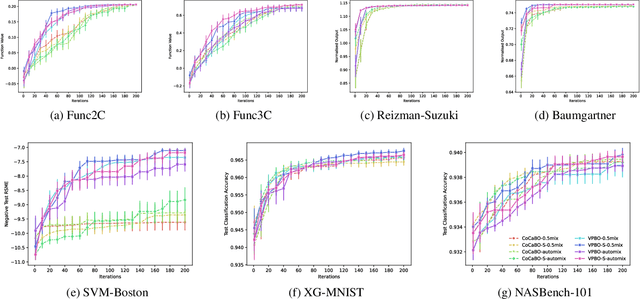
Many real-world optimisation problems are defined over both categorical and continuous variables, yet efficient optimisation methods such asBayesian Optimisation (BO) are not designed tohandle such mixed-variable search spaces. Recent approaches to this problem cast the selection of the categorical variables as a bandit problem, operating independently alongside a BO component which optimises the continuous variables. In this paper, we adopt a holistic view and aim to consolidate optimisation of the categorical and continuous sub-spaces under a single acquisition metric. We derive candidates from the ExpectedImprovement criterion, which we call value proposals, and use these proposals to make selections on both the categorical and continuous components of the input. We show that this unified approach significantly outperforms existing mixed-variable optimisation approaches across several mixed-variable black-box optimisation tasks.