 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified L2-Norm Robustness of 3D Point Cloud Recognition in the Frequency Domain
Nov 10, 2025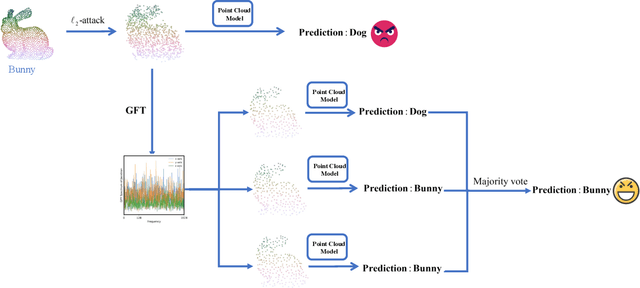
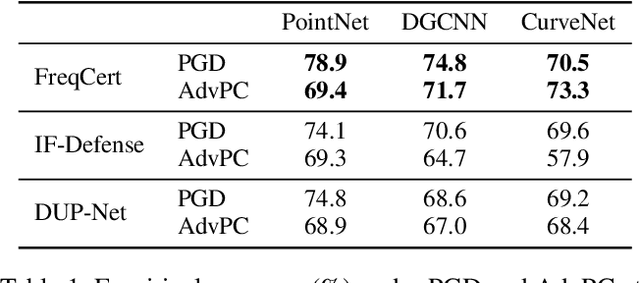

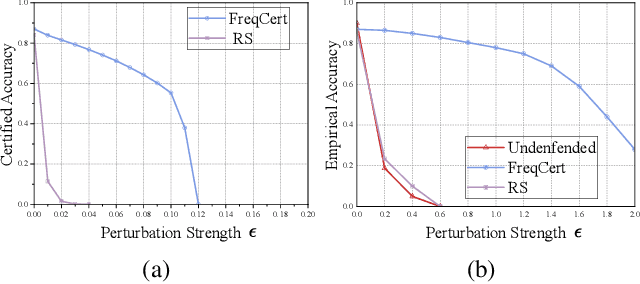
3D point cloud classification is a fundamental task in safety-critical applications such as autonomous driving, robotics, and augmented reality. However, recent studies reveal that point cloud classifiers are vulnerable to structured adversarial perturbations and geometric corruptions, posing risks to their deployment in safety-critical scenarios. Existing certified defenses limit point-wise perturbations but overlook subtle geometric distortions that preserve individual points yet alter the overall structure, potentially leading to misclassification. In this work, we propose FreqCert, a novel certification framework that departs from conventional spatial domain defenses by shifting robustness analysis to the frequency domain, enabling structured certification against global L2-bounded perturbations. FreqCert first transforms the input point cloud via the graph Fourier transform (GFT), then applies structured frequency-aware subsampling to generate multiple sub-point clouds. Each sub-cloud is independently classified by a standard model, and the final prediction is obtained through majority voting, where sub-clouds are constructed based on spectral similarity rather than spatial proximity, making the partitioning more stable under L2 perturbations and better aligned with the object's intrinsic structure. We derive a closed-form lower bound on the certified L2 robustness radius and prove its tightness under minimal and interpretable assumptions, establishing a theoretical foundation for frequency domain certification. Extensive experiments on the ModelNet40 and ScanObjectNN datasets demonstrate that FreqCert consistently achieves higher certified accuracy and empirical accuracy under strong perturbations. Our results suggest that spectral representations provide an effective pathway toward certifiable robustness in 3D point cloud recognition.
Pneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System
Apr 12, 2025Finding relevant tables among databases, lakes, and repositories is the first step in extracting value from data. Such a task remains difficult because assessing whether a table is relevant to a problem does not always depend only on its content but also on the context, which is usually tribal knowledge known to the individual or team. While tools like data catalogs and academic data discovery systems target this problem, they rely on keyword search or more complex interfaces, limiting non-technical users' ability to find relevant data. The advent of large language models (LLMs) offers a unique opportunity for users to ask questions directly in natural language, making dataset discovery more intuitive, accessible, and efficient. In this paper, we introduce Pneuma, a retrieval-augmented generation (RAG) system designed to efficiently and effectively discover tabular data. Pneuma leverages large language models (LLMs) for both table representation and table retrieval. For table representation, Pneuma preserves schema and row-level information to ensure comprehensive data understanding. For table retrieval, Pneuma augments LLMs with traditional information retrieval techniques, such as full-text and vector search, harnessing the strengths of both to improve retrieval performance. To evaluate Pneuma, we generate comprehensive benchmarks that simulate table discovery workload on six real-world datasets including enterprise data, scientific databases, warehousing data, and open data. Our results demonstrate that Pneuma outperforms widely used table search systems (such as full-text search and state-of-the-art RAG systems) in accuracy and resource efficiency.
DART: Dual-level Autonomous Robotic Topology for Efficient Exploration in Unknown Environments
Mar 17, 2025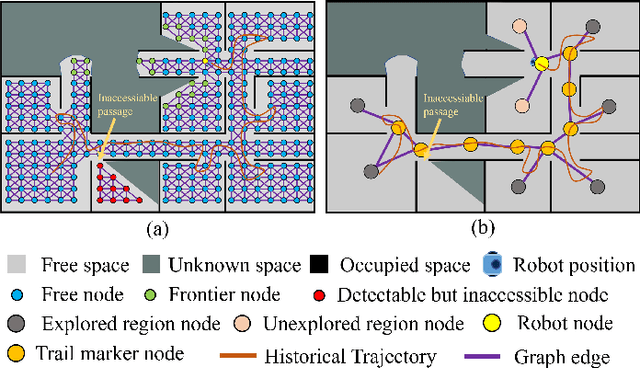
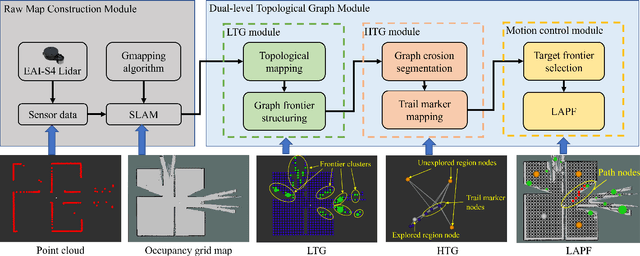

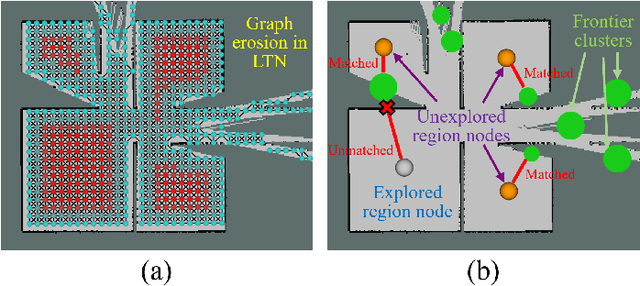
Conventional algorithms in autonomous exploration face challenges due to their inability to accurately and efficiently identify the spatial distribution of convex regions in the real-time map. These methods often prioritize navigation toward the nearest or information-rich frontiers -- the boundaries between known and unknown areas -- resulting in incomplete convex region exploration and requiring excessive backtracking to revisit these missed areas. To address these limitations, this paper introduces an innovative dual-level topological analysis approach. First, we introduce a Low-level Topological Graph (LTG), generated through uniform sampling of the original map data, which captures essential geometric and connectivity details. Next, the LTG is transformed into a High-level Topological Graph (HTG), representing the spatial layout and exploration completeness of convex regions, prioritizing the exploration of convex regions that are not fully explored and minimizing unnecessary backtracking. Finally, an novel Local Artificial Potential Field (LAPF) method is employed for motion control, replacing conventional path planning and boosting overall efficiency. Experimental results highlight the effectiveness of our approach. Simulation tests reveal that our framework significantly reduces exploration time and travel distance, outperforming existing methods in both speed and efficiency. Ablation studies confirm the critical role of each framework component. Real-world tests demonstrate the robustness of our method in environments with poor mapping quality, surpassing other approaches in adaptability to mapping inaccuracies and inaccessible areas.
FabricQA-Extractor: A Question Answering System to Extract Information from Documents using Natural Language Questions
Aug 17, 2024Reading comprehension models answer questions posed in natural language when provided with a short passage of text. They present an opportunity to address a long-standing challenge in data management: the extraction of structured data from unstructured text. Consequently, several approaches are using these models to perform information extraction. However, these modern approaches leave an opportunity behind because they do not exploit the relational structure of the target extraction table. In this paper, we introduce a new model, Relation Coherence, that exploits knowledge of the relational structure to improve the extraction quality. We incorporate the Relation Coherence model as part of FabricQA-Extractor, an end-to-end system we built from scratch to conduct large scale extraction tasks over millions of documents. We demonstrate on two datasets with millions of passages that Relation Coherence boosts extraction performance and evaluate FabricQA-Extractor on large scale datasets.
Middle Fusion and Multi-Stage, Multi-Form Prompts for Robust RGB-T Tracking
Mar 27, 2024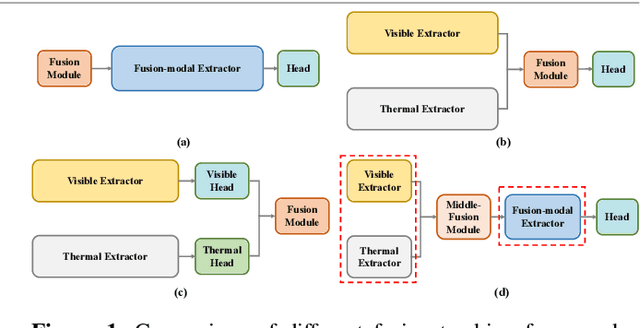
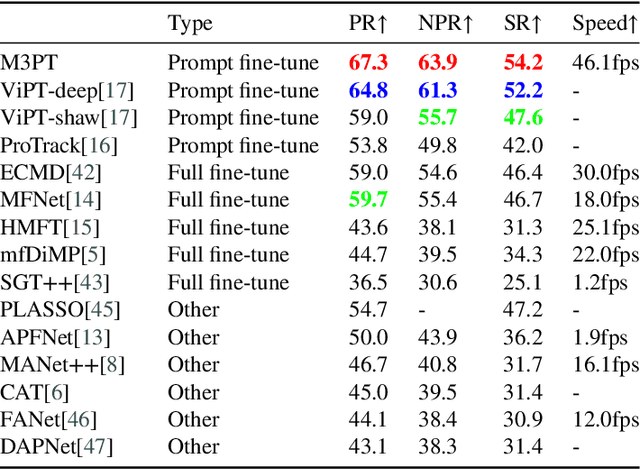
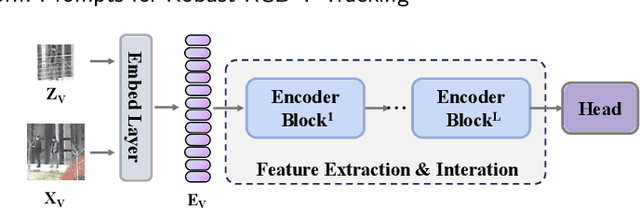
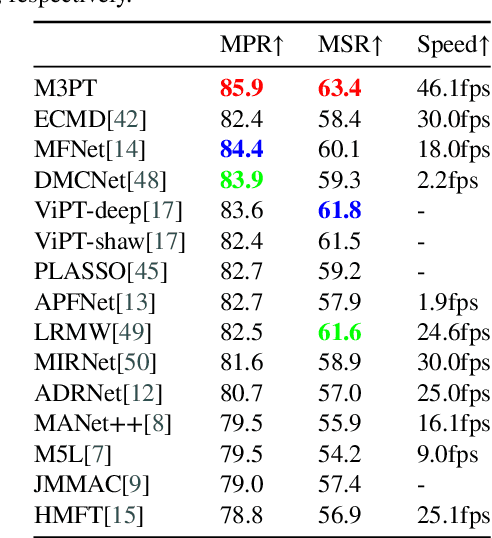
RGB-T tracking, a vital downstream task of object tracking, has made remarkable progress in recent years. Yet, it remains hindered by two major challenges: 1) the trade-off between performance and efficiency; 2) the scarcity of training data. To address the latter challenge, some recent methods employ prompts to fine-tune pre-trained RGB tracking models and leverage upstream knowledge in a parameter-efficient manner. However, these methods inadequately explore modality-independent patterns and disregard the dynamic reliability of different modalities in open scenarios. We propose M3PT, a novel RGB-T prompt tracking method that leverages middle fusion and multi-modal and multi-stage visual prompts to overcome these challenges. We pioneer the use of the middle fusion framework for RGB-T tracking, which achieves a balance between performance and efficiency. Furthermore, we incorporate the pre-trained RGB tracking model into the framework and utilize multiple flexible prompt strategies to adapt the pre-trained model to the comprehensive exploration of uni-modal patterns and the improved modeling of fusion-modal features, harnessing the potential of prompt learning in RGB-T tracking. Our method outperforms the state-of-the-art methods on four challenging benchmarks, while attaining 46.1 fps inference speed.
Localization of Dummy Data Injection Attacks in Power Systems Considering Incomplete Topological Information: A Spatio-Temporal Graph Wavelet Convolutional Neural Network Approach
Jan 27, 2024The emergence of novel the dummy data injection attack (DDIA) poses a severe threat to the secure and stable operation of power systems. These attacks are particularly perilous due to the minimal Euclidean spatial separation between the injected malicious data and legitimate data, rendering their precise detection challenging using conventional distance-based methods. Furthermore, existing research predominantly focuses on various machine learning techniques, often analyzing the temporal data sequences post-attack or relying solely on Euclidean spatial characteristics. Unfortunately, this approach tends to overlook the inherent topological correlations within the non-Euclidean spatial attributes of power grid data, consequently leading to diminished accuracy in attack localization. To address this issue, this study takes a comprehensive approach. Initially, it examines the underlying principles of these new DDIAs on power systems. Here, an intricate mathematical model of the DDIA is designed, accounting for incomplete topological knowledge and alternating current (AC) state estimation from an attacker's perspective. Subsequently, by integrating a priori knowledge of grid topology and considering the temporal correlations within measurement data and the topology-dependent attributes of the power grid, this study introduces temporal and spatial attention matrices. These matrices adaptively capture the spatio-temporal correlations within the attacks. Leveraging gated stacked causal convolution and graph wavelet sparse convolution, the study jointly extracts spatio-temporal DDIA features. Finally, the research proposes a DDIA localization method based on spatio-temporal graph neural networks. The accuracy and effectiveness of the DDIA model are rigorously demonstrated through comprehensive analytical cases.
Data Discovery using Natural Language Questions via a Self-Supervised Approach
Jan 09, 2023Data discovery systems help users identify relevant data among large table collections. Users express their discovery needs with a program or a set of keywords. Users may express complex queries using programs but it requires expertise. Keyword search is accessible to a larger audience but limits the types of queries supported. An interesting approach is learned discovery systems which find tables given natural language questions. Unfortunately, these systems require a training dataset for each table collection. And because collecting training data is expensive, this limits their adoption. In this paper, we introduce a self-supervised approach to assemble training datasets and train learned discovery systems without human intervention. It requires addressing several challenges, including the design of self-supervised strategies for data discovery, table representation strategies to feed to the models, and relevance models that work well with the synthetically generated questions. We combine all the above contributions into a system, S2LD, that solves the problem end to end. The evaluation results demonstrate the new techniques outperform state-of-the-art approaches on wellknown benchmarks. All in all, the technique is a stepping stone towards building learned discovery systems. The code is open-sourced at https://github.com/TheDataStation/open_table_discovery.