 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System
Apr 12, 2025Finding relevant tables among databases, lakes, and repositories is the first step in extracting value from data. Such a task remains difficult because assessing whether a table is relevant to a problem does not always depend only on its content but also on the context, which is usually tribal knowledge known to the individual or team. While tools like data catalogs and academic data discovery systems target this problem, they rely on keyword search or more complex interfaces, limiting non-technical users' ability to find relevant data. The advent of large language models (LLMs) offers a unique opportunity for users to ask questions directly in natural language, making dataset discovery more intuitive, accessible, and efficient. In this paper, we introduce Pneuma, a retrieval-augmented generation (RAG) system designed to efficiently and effectively discover tabular data. Pneuma leverages large language models (LLMs) for both table representation and table retrieval. For table representation, Pneuma preserves schema and row-level information to ensure comprehensive data understanding. For table retrieval, Pneuma augments LLMs with traditional information retrieval techniques, such as full-text and vector search, harnessing the strengths of both to improve retrieval performance. To evaluate Pneuma, we generate comprehensive benchmarks that simulate table discovery workload on six real-world datasets including enterprise data, scientific databases, warehousing data, and open data. Our results demonstrate that Pneuma outperforms widely used table search systems (such as full-text search and state-of-the-art RAG systems) in accuracy and resource efficiency.
Replicable Benchmarking of Neural Machine Translation (NMT) on Low-Resource Local Languages in Indonesia
Nov 02, 2023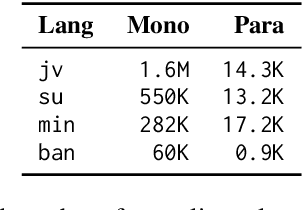
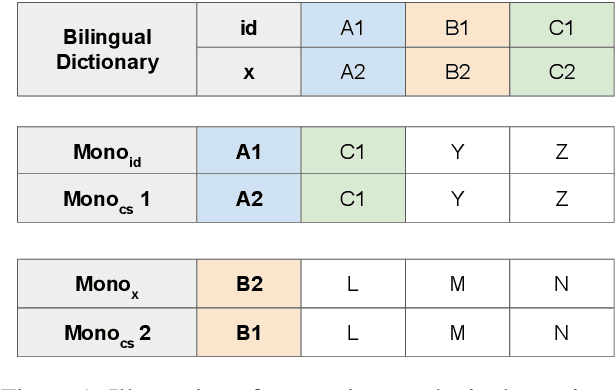
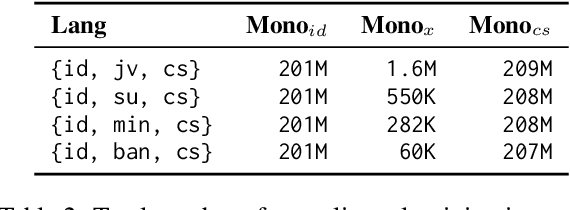
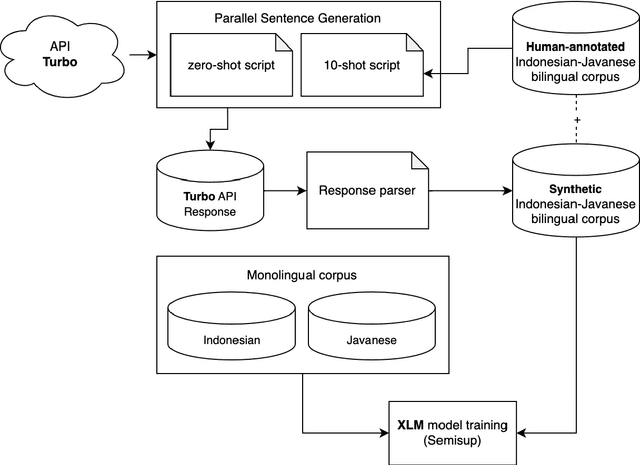
Neural machine translation (NMT) for low-resource local languages in Indonesia faces significant challenges, including the need for a representative benchmark and limited data availability. This work addresses these challenges by comprehensively analyzing training NMT systems for four low-resource local languages in Indonesia: Javanese, Sundanese, Minangkabau, and Balinese. Our study encompasses various training approaches, paradigms, data sizes, and a preliminary study into using large language models for synthetic low-resource languages parallel data generation. We reveal specific trends and insights into practical strategies for low-resource language translation. Our research demonstrates that despite limited computational resources and textual data, several of our NMT systems achieve competitive performances, rivaling the translation quality of zero-shot gpt-3.5-turbo. These findings significantly advance NMT for low-resource languages, offering valuable guidance for researchers in similar contexts.
Rule-based OWL Modeling with ROWLTab Protege Plugin
Aug 30, 2018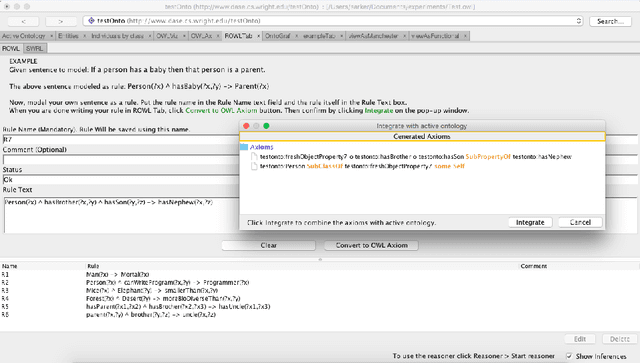

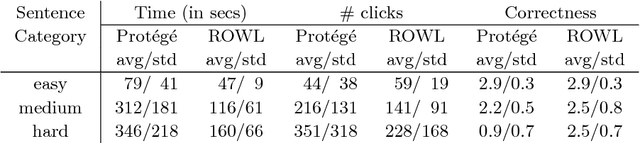
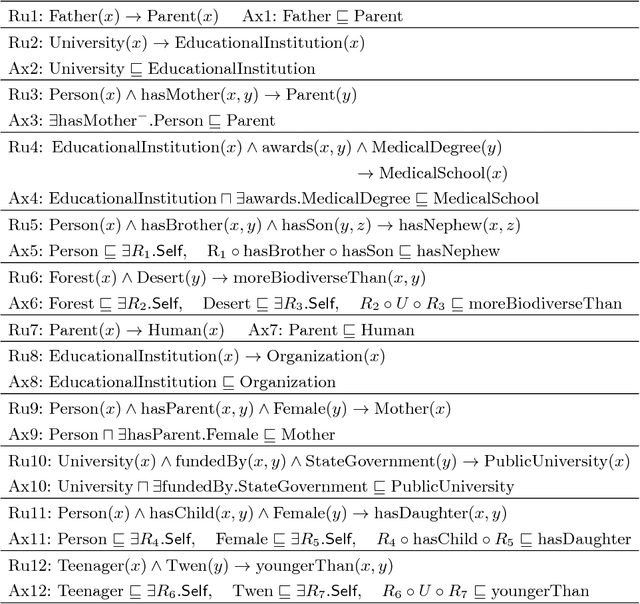
It has been argued that it is much easier to convey logical statements using rules rather than OWL (or description logic (DL)) axioms. Based on recent theoretical developments on transformations between rules and DLs, we have developed ROWLTab, a Protege plugin that allows users to enter OWL axioms by way of rules; the plugin then automatically converts these rules into OWL 2 DL axioms if possible, and prompts the user in case such a conversion is not possible without weakening the semantics of the rule. In this paper, we present ROWLTab, together with a user evaluation of its effectiveness compared to entering axioms using the standard Protege interface. Our evaluation shows that modeling with ROWLTab is much quicker than the standard interface, while at the same time, also less prone to errors for hard modeling tasks.
* Accepted at ESWC 2017
A Tutorial on Modular Ontology Modeling with Ontology Design Patterns: The Cooking Recipes Ontology
Aug 25, 2018

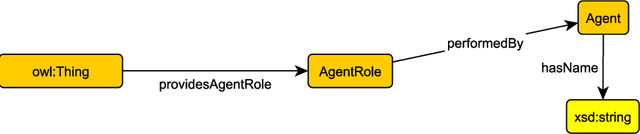

We provide a detailed example for modular ontology modeling based on ontology design patterns.