 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy2Vec: Crosslingual Language Modeling Entropy as End-to-End Learnable Language Representations
Sep 05, 2025We introduce Entropy2Vec, a novel framework for deriving cross-lingual language representations by leveraging the entropy of monolingual language models. Unlike traditional typological inventories that suffer from feature sparsity and static snapshots, Entropy2Vec uses the inherent uncertainty in language models to capture typological relationships between languages. By training a language model on a single language, we hypothesize that the entropy of its predictions reflects its structural similarity to other languages: Low entropy indicates high similarity, while high entropy suggests greater divergence. This approach yields dense, non-sparse language embeddings that are adaptable to different timeframes and free from missing values. Empirical evaluations demonstrate that Entropy2Vec embeddings align with established typological categories and achieved competitive performance in downstream multilingual NLP tasks, such as those addressed by the LinguAlchemy framework.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024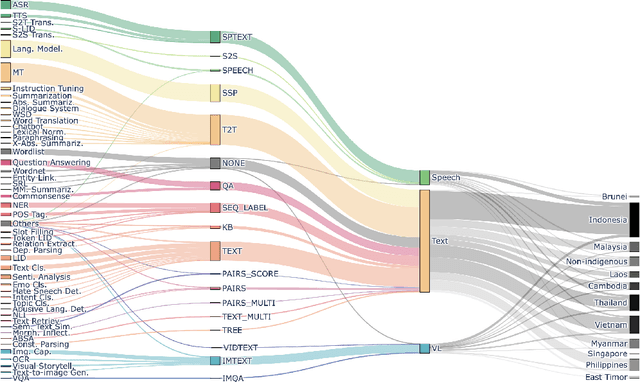
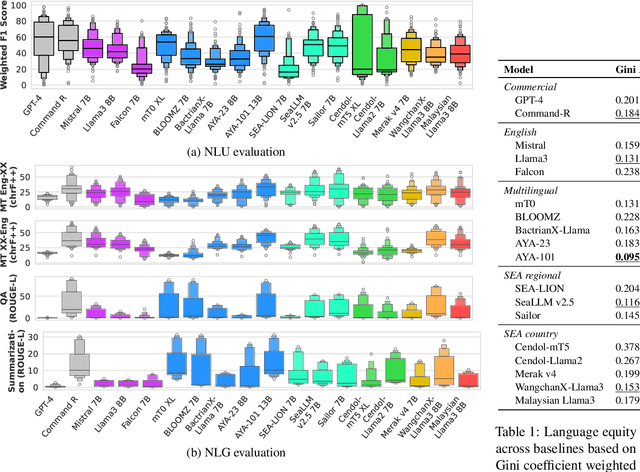
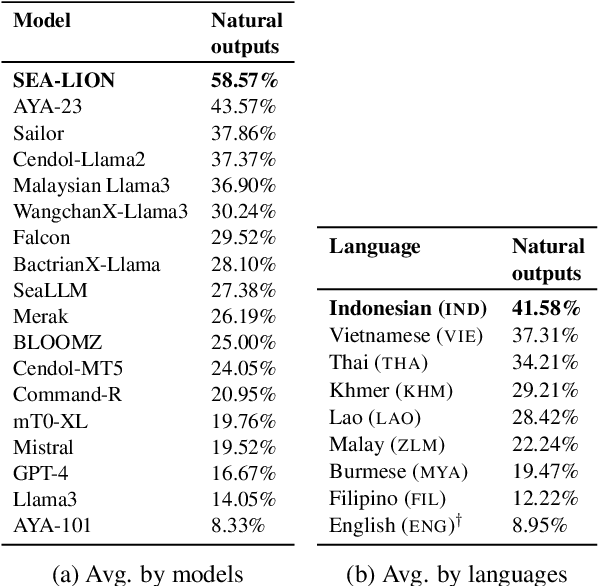
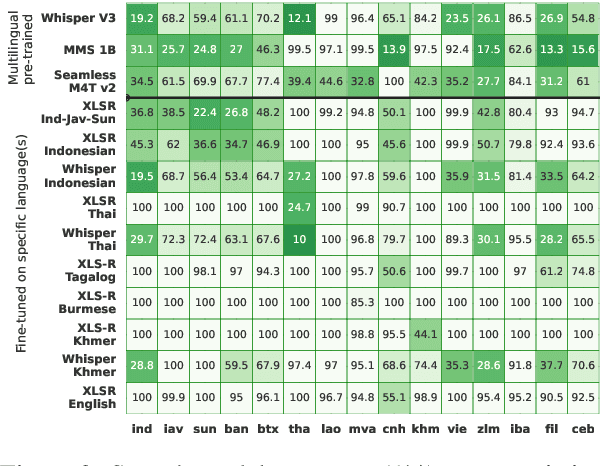
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
What Linguistic Features and Languages are Important in LLM Translation?
Feb 21, 2024Large Language Models (LLMs) demonstrate strong capability across multiple tasks, including machine translation. Our study focuses on evaluating Llama2's machine translation capabilities and exploring how translation depends on languages in its training data. Our experiments show that the 7B Llama2 model yields above 10 BLEU score for all languages it has seen, but not always for languages it has not seen. Most gains for those unseen languages are observed the most with the model scale compared to using chat versions or adding shot count. Furthermore, our linguistic distance analysis reveals that syntactic similarity is not always the primary linguistic factor in determining translation quality. Interestingly, we discovered that under specific circumstances, some languages, despite having significantly less training data than English, exhibit strong correlations comparable to English. Our discoveries here give new perspectives for the current landscape of LLMs, raising the possibility that LLMs centered around languages other than English may offer a more effective foundation for a multilingual model.
Replicable Benchmarking of Neural Machine Translation (NMT) on Low-Resource Local Languages in Indonesia
Nov 02, 2023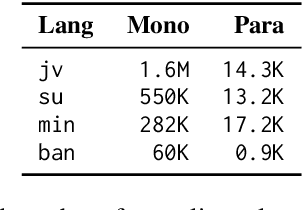
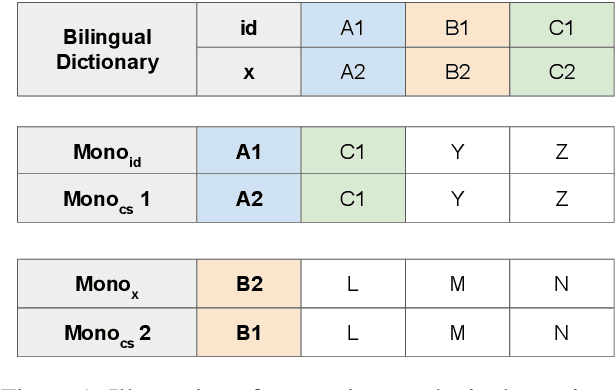
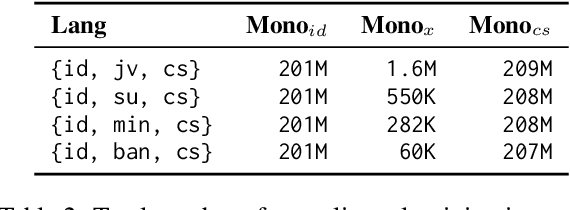
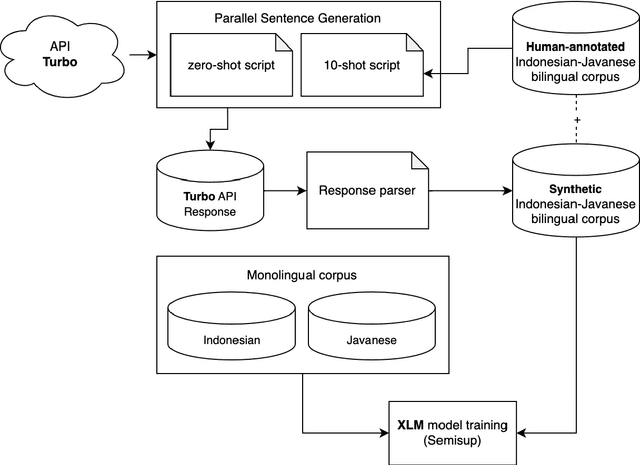
Neural machine translation (NMT) for low-resource local languages in Indonesia faces significant challenges, including the need for a representative benchmark and limited data availability. This work addresses these challenges by comprehensively analyzing training NMT systems for four low-resource local languages in Indonesia: Javanese, Sundanese, Minangkabau, and Balinese. Our study encompasses various training approaches, paradigms, data sizes, and a preliminary study into using large language models for synthetic low-resource languages parallel data generation. We reveal specific trends and insights into practical strategies for low-resource language translation. Our research demonstrates that despite limited computational resources and textual data, several of our NMT systems achieve competitive performances, rivaling the translation quality of zero-shot gpt-3.5-turbo. These findings significantly advance NMT for low-resource languages, offering valuable guidance for researchers in similar contexts.
NusaCrowd: Open Source Initiative for Indonesian NLP Resources
Dec 20, 2022We present NusaCrowd, a collaborative initiative to collect and unite existing resources for Indonesian languages, including opening access to previously non-public resources. Through this initiative, we have has brought together 137 datasets and 117 standardized data loaders. The quality of the datasets has been assessed manually and automatically, and their effectiveness has been demonstrated in multiple experiments. NusaCrowd's data collection enables the creation of the first zero-shot benchmarks for natural language understanding and generation in Indonesian and its local languages. Furthermore, NusaCrowd brings the creation of the first multilingual automatic speech recognition benchmark in Indonesian and its local languages. Our work is intended to help advance natural language processing research in under-represented languages.