 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectalArabicMMLU: Benchmarking Dialectal Capabilities in Arabic and Multilingual Language Models
Oct 31, 2025We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024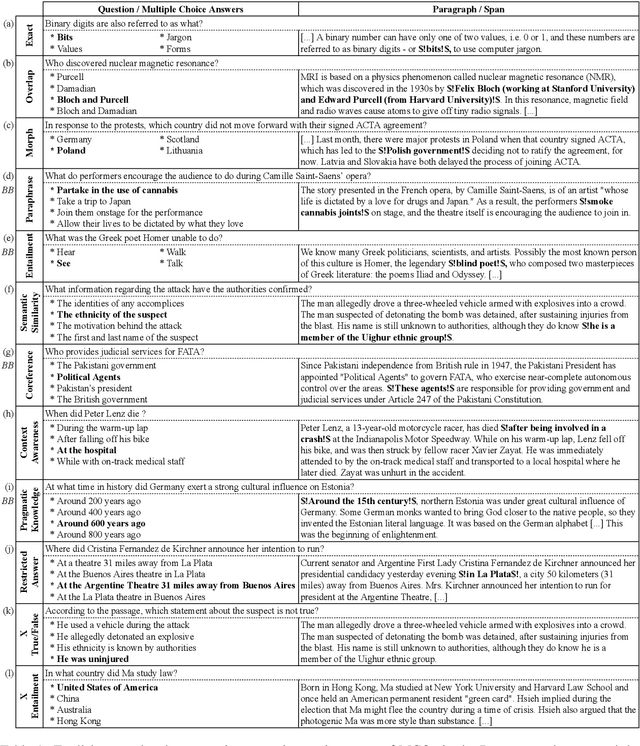

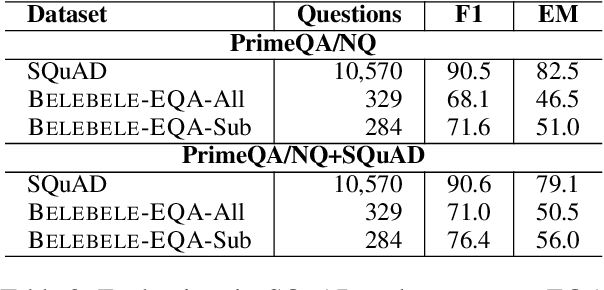
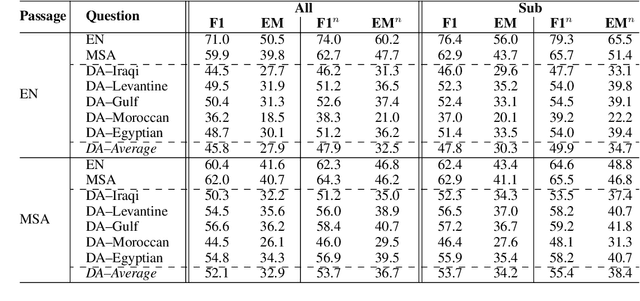
The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
gaBERT -- an Irish Language Model
Jul 28, 2021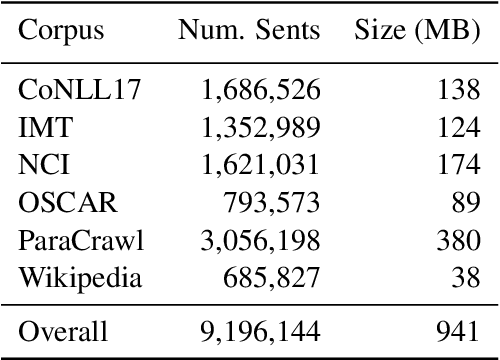
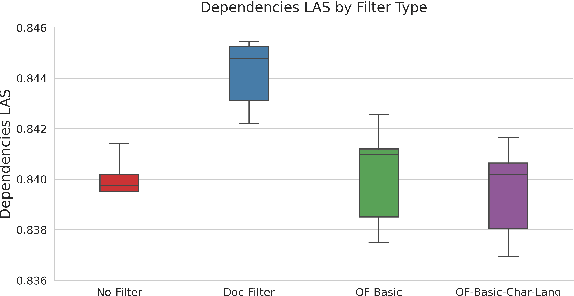
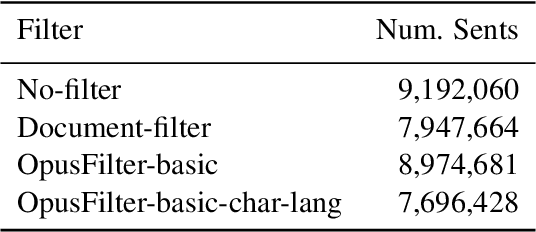
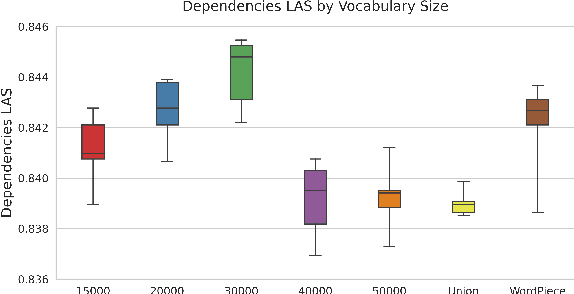
The BERT family of neural language models have become highly popular due to their ability to provide sequences of text with rich context-sensitive token encodings which are able to generalise well to many Natural Language Processing tasks. Over 120 monolingual BERT models covering over 50 languages have been released, as well as a multilingual model trained on 104 languages. We introduce, gaBERT, a monolingual BERT model for the Irish language. We compare our gaBERT model to multilingual BERT and show that gaBERT provides better representations for a downstream parsing task. We also show how different filtering criteria, vocabulary size and the choice of subword tokenisation model affect downstream performance. We release gaBERT and related code to the community.
Towards transparency in NLP shared tasks
May 11, 2021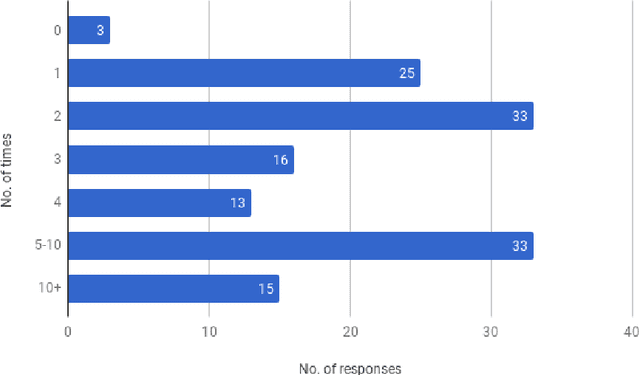
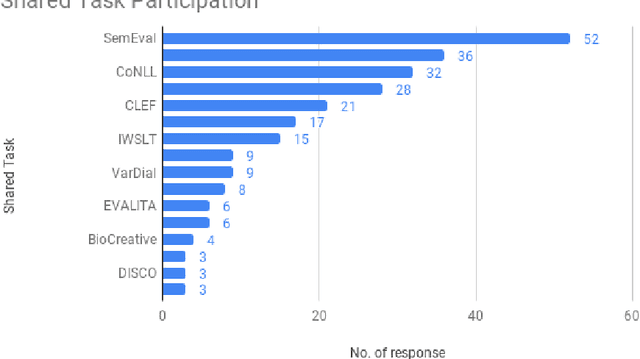

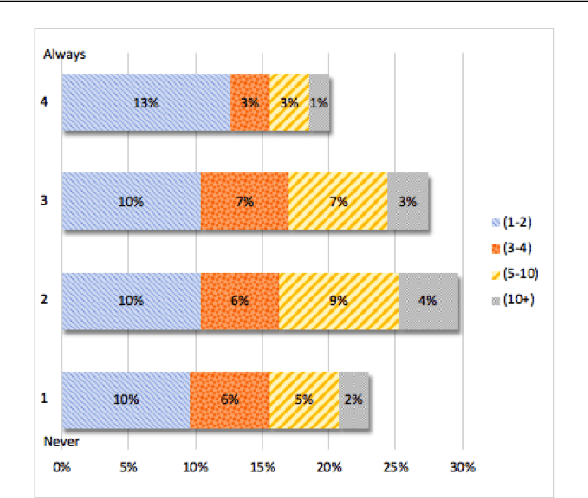
This article reports on a survey carried out across the Natural Language Processing (NLP) community. The survey aimed to capture the opinions of the research community on issues surrounding shared tasks, with respect to both participation and organisation. Amongst the 175 responses received, both positive and negative observations were made. We carried out and report on an extensive analysis of these responses, which leads us to propose a Shared Task Organisation Checklist that could support future participants and organisers. The proposed Checklist is flexible enough to accommodate the wide diversity of shared tasks in our field and its goal is not to be prescriptive, but rather to serve as a tool that encourages shared task organisers to foreground ethical behaviour, beginning with the common issues that the 175 respondents deemed important. Its usage would not only serve as an instrument to reflect on important aspects of shared tasks, but would also promote increased transparency around them.
Treebanking User-Generated Content: a UD Based Overview of Guidelines, Corpora and Unified Recommendations
Nov 03, 2020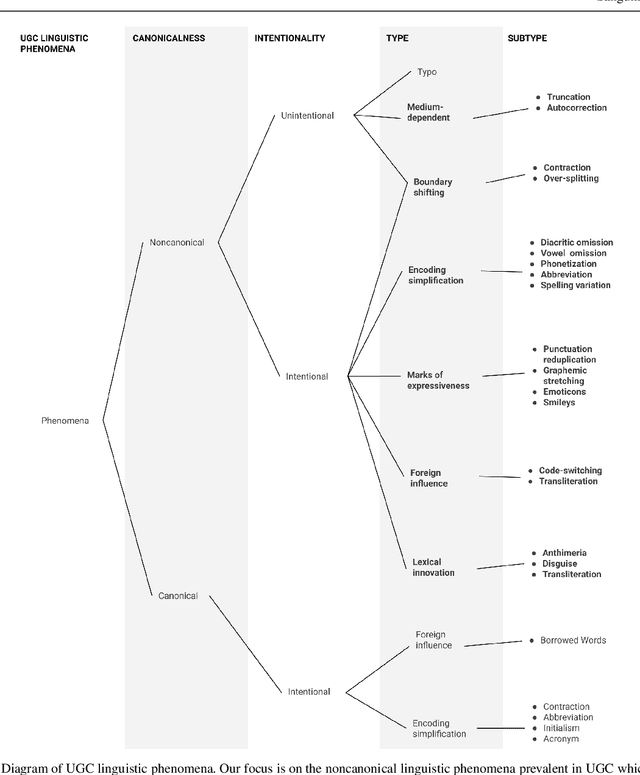
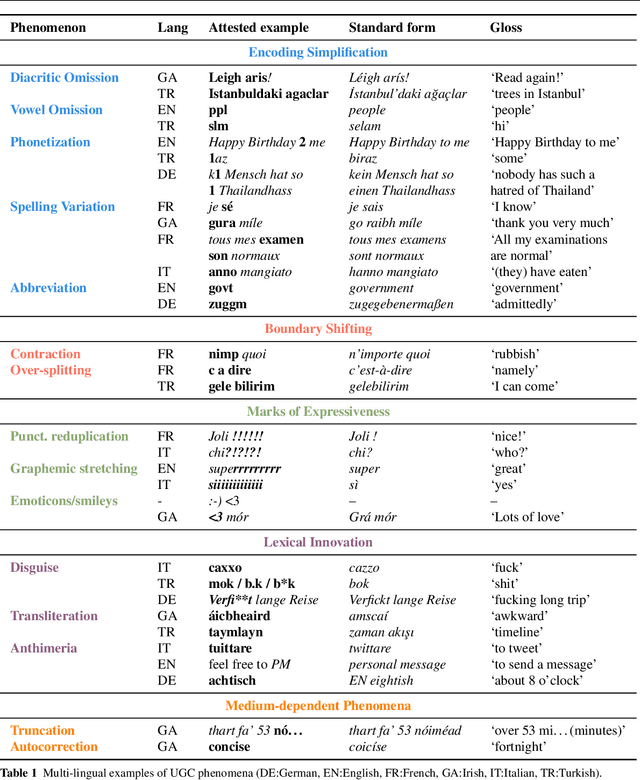
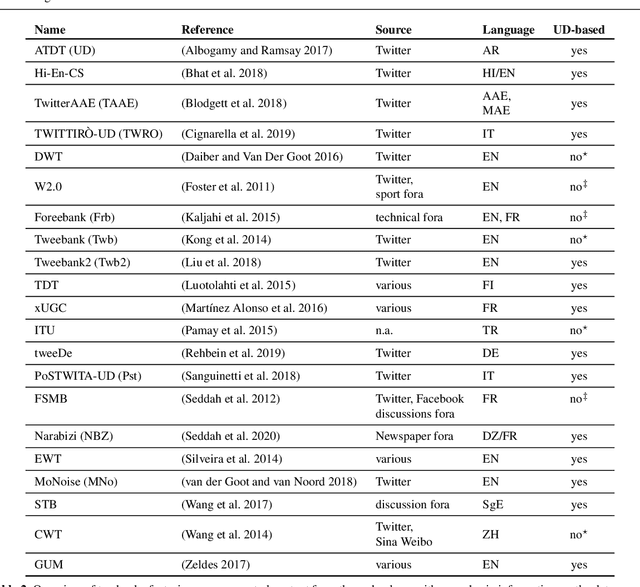
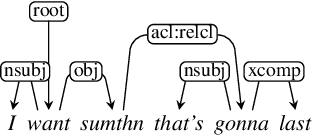
This article presents a discussion on the main linguistic phenomena which cause difficulties in the analysis of user-generated texts found on the web and in social media, and proposes a set of annotation guidelines for their treatment within the Universal Dependencies (UD) framework of syntactic analysis. Given on the one hand the increasing number of treebanks featuring user-generated content, and its somewhat inconsistent treatment in these resources on the other, the aim of this article is twofold: (1) to provide a condensed, though comprehensive, overview of such treebanks -- based on available literature -- along with their main features and a comparative analysis of their annotation criteria, and (2) to propose a set of tentative UD-based annotation guidelines, to promote consistent treatment of the particular phenomena found in these types of texts. The overarching goal of this article is to provide a common framework for researchers interested in developing similar resources in UD, thus promoting cross-linguistic consistency, which is a principle that has always been central to the spirit of UD.