 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Semantic Segmentation for Low-Resource Spoken Dialects
May 07, 2026Semantic segmentation is a core component of discourse analysis, yet existing models are primarily developed and evaluated on high-resource written text, limiting their effectiveness on low-resource spoken varieties. In particular, dialectal Arabic exhibits informal syntax, code-switching, and weakly marked discourse structure that challenge standard segmentation approaches. In this paper, we introduce a new multi-genre benchmark (more than 1000 samples) for semantic segmentation in conversational Arabic, focusing on dialectal discourse. The benchmark covers transcribed casual telephone conversations, code-switched podcasts, broadcast news, and expressive dialogue from novels, and was annotated and validated by native Arabic annotators. Using this benchmark, we show that segmentation models performing well on MSA news genres degrade on dialectal transcribed speech. We further propose a segmentation model that targets local semantic coherence and robustness to discourse discontinuities, consistently outperforming strong baselines on dialectal non-news genres. The benchmark and approach generalize to other low-resource spoken languages.
SemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
CulturALL: Benchmarking Multilingual and Multicultural Competence of LLMs on Grounded Tasks
Apr 21, 2026Large language models (LLMs) are now deployed worldwide, inspiring a surge of benchmarks that measure their multilingual and multicultural abilities. However, these benchmarks prioritize generic language understanding or superficial cultural trivia, leaving the evaluation of grounded tasks -- where models must reason within real-world, context-rich scenarios -- largely unaddressed. To fill this gap, we present CulturALL, a comprehensive and challenging benchmark to assess LLMs' multilingual and multicultural competence on grounded tasks. CulturALL is built via a human--AI collaborative framework: expert annotators ensure appropriate difficulty and factual accuracy, while LLMs lighten the manual workload. By incorporating diverse sources, CulturALL ensures comprehensive scenario coverage. Each item is carefully designed to present a high level of difficulty, making CulturALL challenging. CulturALL contains 2,610 samples in 14 languages from 51 regions, distributed across 16 topics to capture the full breadth of grounded tasks. Experiments show that the best LLM achieves 44.48% accuracy on CulturALL, underscoring substantial room for improvement.
DialectalArabicMMLU: Benchmarking Dialectal Capabilities in Arabic and Multilingual Language Models
Oct 31, 2025We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development.
Large Language Models as Code Executors: An Exploratory Study
Oct 10, 2024



The capabilities of Large Language Models (LLMs) have significantly evolved, extending from natural language processing to complex tasks like code understanding and generation. We expand the scope of LLMs' capabilities to a broader context, using LLMs to execute code snippets to obtain the output. This paper pioneers the exploration of LLMs as code executors, where code snippets are directly fed to the models for execution, and outputs are returned. We are the first to comprehensively examine this feasibility across various LLMs, including OpenAI's o1, GPT-4o, GPT-3.5, DeepSeek, and Qwen-Coder. Notably, the o1 model achieved over 90% accuracy in code execution, while others demonstrated lower accuracy levels. Furthermore, we introduce an Iterative Instruction Prompting (IIP) technique that processes code snippets line by line, enhancing the accuracy of weaker models by an average of 7.22% (with the highest improvement of 18.96%) and an absolute average improvement of 3.86% against CoT prompting (with the highest improvement of 19.46%). Our study not only highlights the transformative potential of LLMs in coding but also lays the groundwork for future advancements in automated programming and the completion of complex tasks.
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024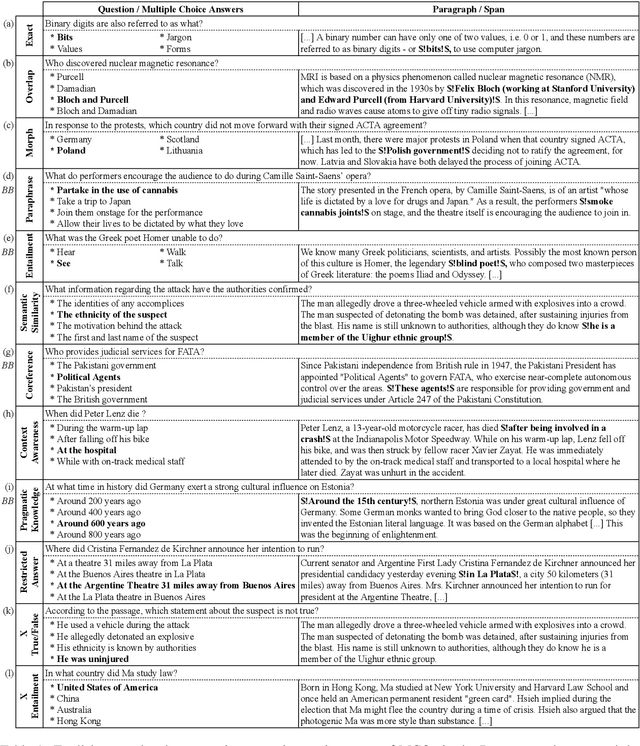

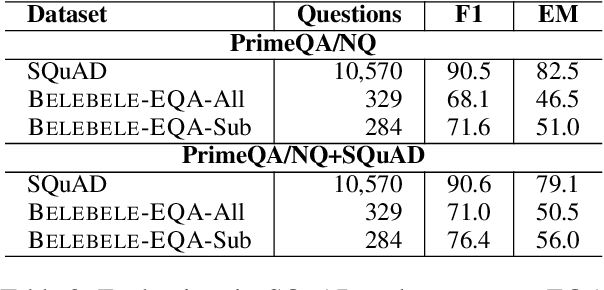
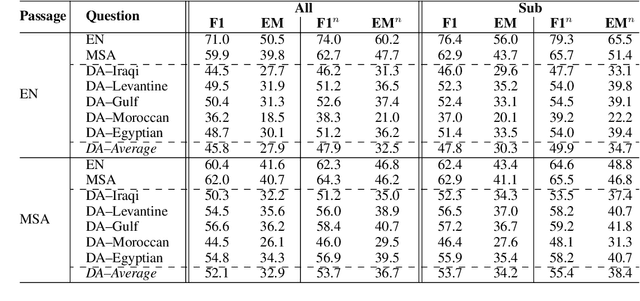
The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
Multilingual Nonce Dependency Treebanks: Understanding how LLMs represent and process syntactic structure
Nov 13, 2023
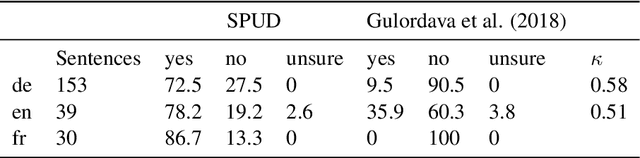


We introduce SPUD (Semantically Perturbed Universal Dependencies), a framework for creating nonce treebanks for the multilingual Universal Dependencies (UD) corpora. SPUD data satisfies syntactic argument structure, provides syntactic annotations, and ensures grammaticality via language-specific rules. We create nonce data in Arabic, English, French, German, and Russian, and demonstrate two use cases of SPUD treebanks. First, we investigate the effect of nonce data on word co-occurrence statistics, as measured by perplexity scores of autoregressive (ALM) and masked language models (MLM). We find that ALM scores are significantly more affected by nonce data than MLM scores. Second, we show how nonce data affects the performance of syntactic dependency probes. We replicate the findings of M\"uller-Eberstein et al. (2022) on nonce test data and show that the performance declines on both MLMs and ALMs wrt. original test data. However, a majority of the performance is kept, suggesting that the probe indeed learns syntax independently from semantics.
Probing for Constituency Structure in Neural Language Models
Apr 13, 2022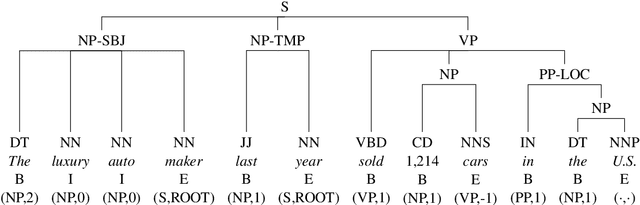

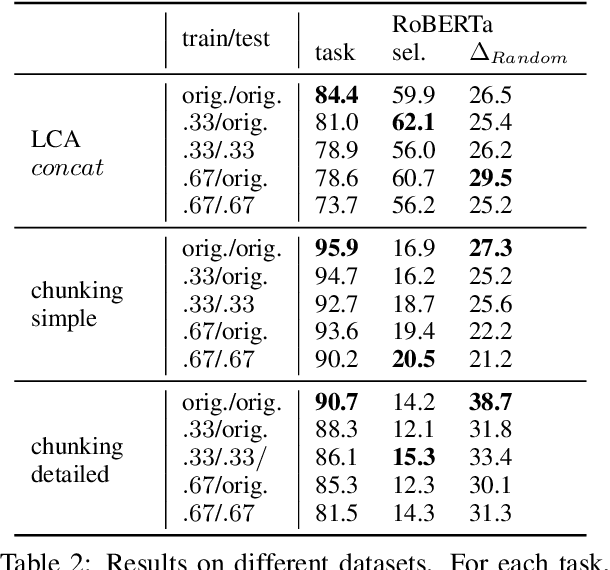
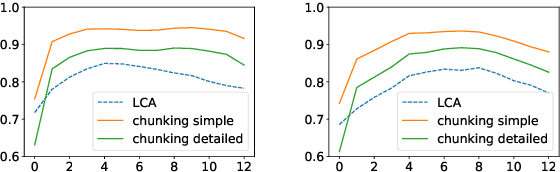
In this paper, we investigate to which extent contextual neural language models (LMs) implicitly learn syntactic structure. More concretely, we focus on constituent structure as represented in the Penn Treebank (PTB). Using standard probing techniques based on diagnostic classifiers, we assess the accuracy of representing constituents of different categories within the neuron activations of a LM such as RoBERTa. In order to make sure that our probe focuses on syntactic knowledge and not on implicit semantic generalizations, we also experiment on a PTB version that is obtained by randomly replacing constituents with each other while keeping syntactic structure, i.e., a semantically ill-formed but syntactically well-formed version of the PTB. We find that 4 pretrained transfomer LMs obtain high performance on our probing tasks even on manipulated data, suggesting that semantic and syntactic knowledge in their representations can be separated and that constituency information is in fact learned by the LM. Moreover, we show that a complete constituency tree can be linearly separated from LM representations.
Automatic Expansion and Retargeting of Arabic Offensive Language Training
Nov 18, 2021
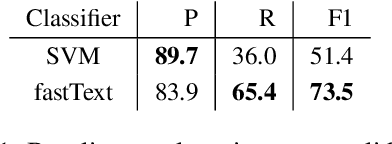
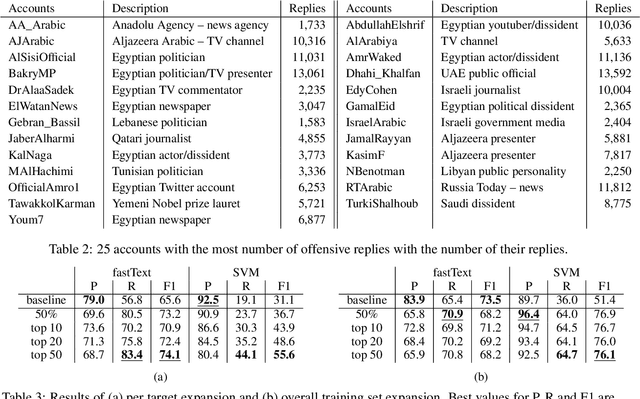
Rampant use of offensive language on social media led to recent efforts on automatic identification of such language. Though offensive language has general characteristics, attacks on specific entities may exhibit distinct phenomena such as malicious alterations in the spelling of names. In this paper, we present a method for identifying entity specific offensive language. We employ two key insights, namely that replies on Twitter often imply opposition and some accounts are persistent in their offensiveness towards specific targets. Using our methodology, we are able to collect thousands of targeted offensive tweets. We show the efficacy of the approach on Arabic tweets with 13% and 79% relative F1-measure improvement in entity specific offensive language detection when using deep-learning based and support vector machine based classifiers respectively. Further, expanding the training set with automatically identified offensive tweets directed at multiple entities can improve F1-measure by 48%.
Pre-Training BERT on Arabic Tweets: Practical Considerations
Feb 21, 2021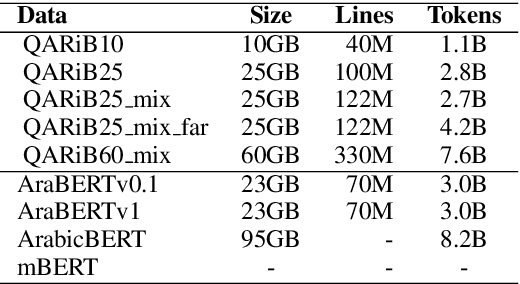
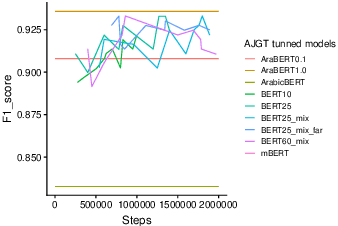
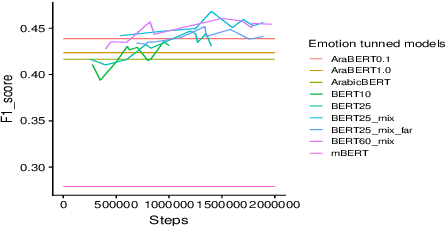
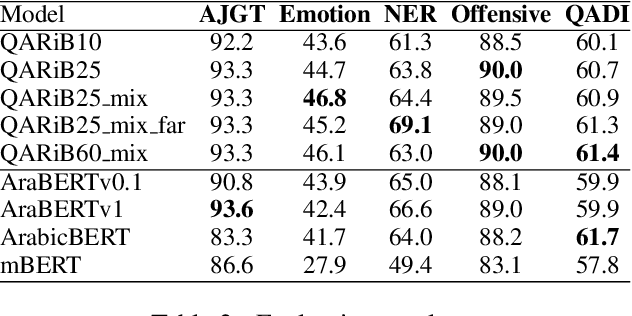
Pretraining Bidirectional Encoder Representations from Transformers (BERT) for downstream NLP tasks is a non-trival task. We pretrained 5 BERT models that differ in the size of their training sets, mixture of formal and informal Arabic, and linguistic preprocessing. All are intended to support Arabic dialects and social media. The experiments highlight the centrality of data diversity and the efficacy of linguistically aware segmentation. They also highlight that more data or more training step do not necessitate better models. Our new models achieve new state-of-the-art results on several downstream tasks. The resulting models are released to the community under the name QARiB.