 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectalArabicMMLU: Benchmarking Dialectal Capabilities in Arabic and Multilingual Language Models
Oct 31, 2025We present DialectalArabicMMLU, a new benchmark for evaluating the performance of large language models (LLMs) across Arabic dialects. While recently developed Arabic and multilingual benchmarks have advanced LLM evaluation for Modern Standard Arabic (MSA), dialectal varieties remain underrepresented despite their prevalence in everyday communication. DialectalArabicMMLU extends the MMLU-Redux framework through manual translation and adaptation of 3K multiple-choice question-answer pairs into five major dialects (Syrian, Egyptian, Emirati, Saudi, and Moroccan), yielding a total of 15K QA pairs across 32 academic and professional domains (22K QA pairs when also including English and MSA). The benchmark enables systematic assessment of LLM reasoning and comprehension beyond MSA, supporting both task-based and linguistic analysis. We evaluate 19 open-weight Arabic and multilingual LLMs (1B-13B parameters) and report substantial performance variation across dialects, revealing persistent gaps in dialectal generalization. DialectalArabicMMLU provides the first unified, human-curated resource for measuring dialectal understanding in Arabic, thus promoting more inclusive evaluation and future model development.
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024

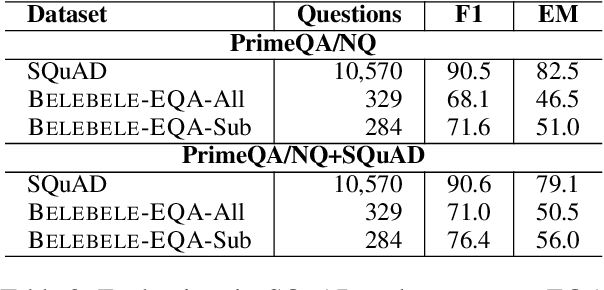
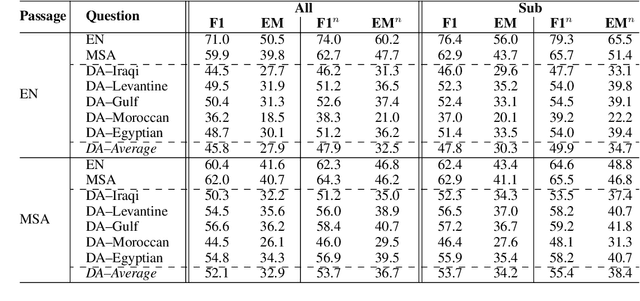
The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
The Topic Confusion Task: A Novel Scenario for Authorship Attribution
Apr 17, 2021
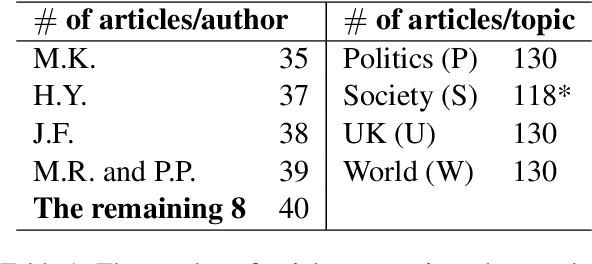
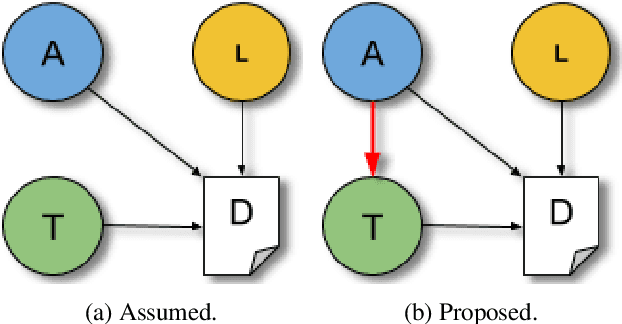
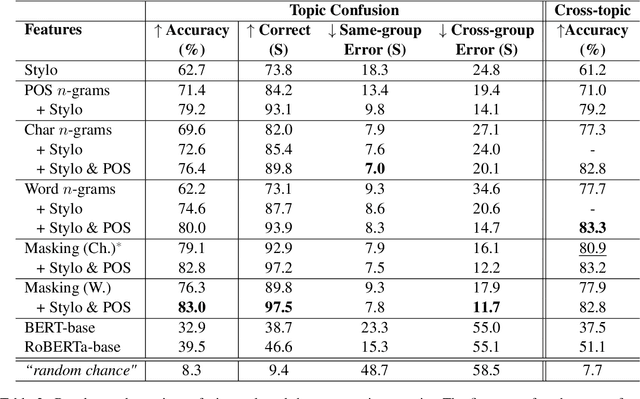
Authorship attribution is the problem of identifying the most plausible author of an anonymous text from a set of candidate authors. Researchers have investigated same-topic and cross-topic scenarios of authorship attribution, which differ according to whether unseen topics are used in the testing phase. However, neither scenario allows us to explain whether errors are caused by failure to capture authorship style, by the topic shift or by other factors. Motivated by this, we propose the \emph{topic confusion} task, where we switch the author-topic configuration between training and testing set. This setup allows us to probe errors in the attribution process. We investigate the accuracy and two error measures: one caused by the models' confusion by the switch because the features capture the topics, and one caused by the features' inability to capture the writing styles, leading to weaker models. By evaluating different features, we show that stylometric features with part-of-speech tags are less susceptible to topic variations and can increase the accuracy of the attribution process. We further show that combining them with word-level $n$-grams can outperform the state-of-the-art technique in the cross-topic scenario. Finally, we show that pretrained language models such as BERT and RoBERTa perform poorly on this task, and are outperformed by simple $n$-gram features.