 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Topic Confusion Task: A Novel Scenario for Authorship Attribution
Paper and Code

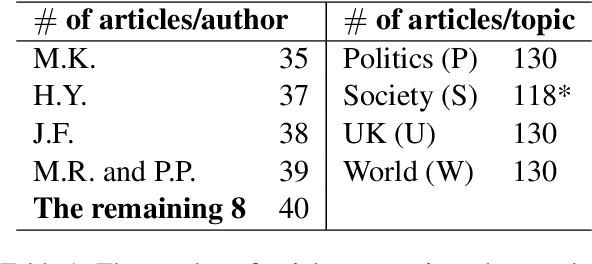
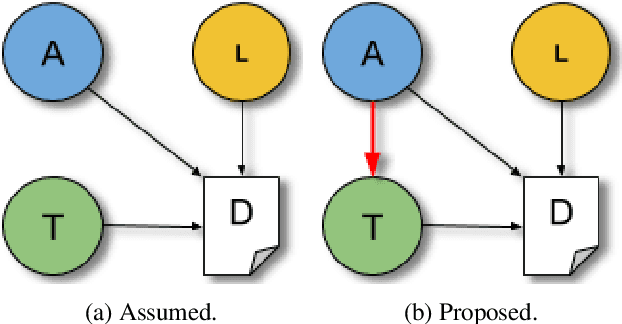
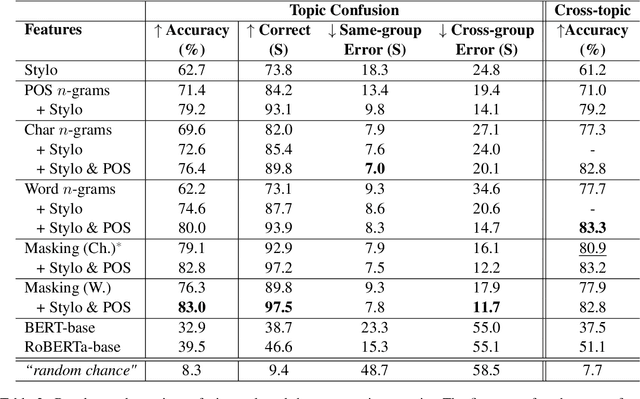
Authorship attribution is the problem of identifying the most plausible author of an anonymous text from a set of candidate authors. Researchers have investigated same-topic and cross-topic scenarios of authorship attribution, which differ according to whether unseen topics are used in the testing phase. However, neither scenario allows us to explain whether errors are caused by failure to capture authorship style, by the topic shift or by other factors. Motivated by this, we propose the \emph{topic confusion} task, where we switch the author-topic configuration between training and testing set. This setup allows us to probe errors in the attribution process. We investigate the accuracy and two error measures: one caused by the models' confusion by the switch because the features capture the topics, and one caused by the features' inability to capture the writing styles, leading to weaker models. By evaluating different features, we show that stylometric features with part-of-speech tags are less susceptible to topic variations and can increase the accuracy of the attribution process. We further show that combining them with word-level $n$-grams can outperform the state-of-the-art technique in the cross-topic scenario. Finally, we show that pretrained language models such as BERT and RoBERTa perform poorly on this task, and are outperformed by simple $n$-gram features.