 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Evaluating Outcome-Driven Constraint Violations in Autonomous AI Agents
Dec 23, 2025As autonomous AI agents are increasingly deployed in high-stakes environments, ensuring their safety and alignment with human values has become a paramount concern. Current safety benchmarks often focusing only on single-step decision-making, simulated environments for tasks with malicious intent, or evaluating adherence to explicit negative constraints. There is a lack of benchmarks that are designed to capture emergent forms of outcome-driven constraint violations, which arise when agents pursue goal optimization under strong performance incentives while deprioritizing ethical, legal, or safety constraints over multiple steps in realistic production settings. To address this gap, we introduce a new benchmark comprising 40 distinct scenarios. Each scenario presents a task that requires multi-step actions, and the agent's performance is tied to a specific Key Performance Indicator (KPI). Each scenario features Mandated (instruction-commanded) and Incentivized (KPI-pressure-driven) variations to distinguish between obedience and emergent misalignment. Across 12 state-of-the-art large language models, we observe outcome-driven constraint violations ranging from 1.3% to 71.4%, with 9 of the 12 evaluated models exhibiting misalignment rates between 30% and 50%. Strikingly, we find that superior reasoning capability does not inherently ensure safety; for instance, Gemini-3-Pro-Preview, one of the most capable models evaluated, exhibits the highest violation rate at over 60%, frequently escalating to severe misconduct to satisfy KPIs. Furthermore, we observe significant "deliberative misalignment", where the models that power the agents recognize their actions as unethical during separate evaluation. These results emphasize the critical need for more realistic agentic-safety training before deployment to mitigate their risks in the real world.
Security Concerns for Large Language Models: A Survey
May 24, 2025Large Language Models (LLMs) such as GPT-4 (and its recent iterations like GPT-4o and the GPT-4.1 series), Google's Gemini, Anthropic's Claude 3 models, and xAI's Grok have caused a revolution in natural language processing, but their capabilities also introduce new security vulnerabilities. In this survey, we provide a comprehensive overview of the emerging security concerns around LLMs, categorizing threats into prompt injection and jailbreaking, adversarial attacks (including input perturbations and data poisoning), misuse by malicious actors (e.g., for disinformation, phishing, and malware generation), and worrisome risks inherent in autonomous LLM agents. A significant focus has been recently placed on the latter, exploring goal misalignment, emergent deception, self-preservation instincts, and the potential for LLMs to develop and pursue covert, misaligned objectives (scheming), which may even persist through safety training. We summarize recent academic and industrial studies (2022-2025) that exemplify each threat, analyze proposed defenses and their limitations, and identify open challenges in securing LLM-based applications. We conclude by emphasizing the importance of advancing robust, multi-layered security strategies to ensure LLMs are safe and beneficial.
Experience of Training a 1.7B-Parameter LLaMa Model From Scratch
Dec 17, 2024



Pretraining large language models is a complex endeavor influenced by multiple factors, including model architecture, data quality, training continuity, and hardware constraints. In this paper, we share insights gained from the experience of training DMaS-LLaMa-Lite, a fully open source, 1.7-billion-parameter, LLaMa-based model, on approximately 20 billion tokens of carefully curated data. We chronicle the full training trajectory, documenting how evolving validation loss levels and downstream benchmarks reflect transitions from incoherent text to fluent, contextually grounded output. Beyond standard quantitative metrics, we highlight practical considerations such as the importance of restoring optimizer states when resuming from checkpoints, and the impact of hardware changes on training stability and throughput. While qualitative evaluation provides an intuitive understanding of model improvements, our analysis extends to various performance benchmarks, demonstrating how high-quality data and thoughtful scaling enable competitive results with significantly fewer training tokens. By detailing these experiences and offering training logs, checkpoints, and sample outputs, we aim to guide future researchers and practitioners in refining their pretraining strategies. The training script is available on Github at https://github.com/McGill-DMaS/DMaS-LLaMa-Lite-Training-Code. The model checkpoints are available on Huggingface at https://huggingface.co/collections/McGill-DMaS/dmas-llama-lite-6761d97ba903f82341954ceb.
On the Effectiveness of Incremental Training of Large Language Models
Nov 27, 2024

Training large language models is a computationally intensive process that often requires substantial resources to achieve state-of-the-art results. Incremental layer-wise training has been proposed as a potential strategy to optimize the training process by progressively introducing layers, with the expectation that this approach would lead to faster convergence and more efficient use of computational resources. In this paper, we investigate the effectiveness of incremental training for LLMs, dividing the training process into multiple stages where layers are added progressively. Our experimental results indicate that while the incremental approach initially demonstrates some computational efficiency, it ultimately requires greater overall computational costs to reach comparable performance to traditional full-scale training. Although the incremental training process can eventually close the performance gap with the baseline, it does so only after significantly extended continual training. These findings suggest that incremental layer-wise training may not be a viable alternative for training large language models, highlighting its limitations and providing valuable insights into the inefficiencies of this approach.
Dynamic Neural Control Flow Execution: An Agent-Based Deep Equilibrium Approach for Binary Vulnerability Detection
Apr 03, 2024



Software vulnerabilities are a challenge in cybersecurity. Manual security patches are often difficult and slow to be deployed, while new vulnerabilities are created. Binary code vulnerability detection is less studied and more complex compared to source code, and this has important practical implications. Deep learning has become an efficient and powerful tool in the security domain, where it provides end-to-end and accurate prediction. Modern deep learning approaches learn the program semantics through sequence and graph neural networks, using various intermediate representation of programs, such as abstract syntax trees (AST) or control flow graphs (CFG). Due to the complex nature of program execution, the output of an execution depends on the many program states and inputs. Also, a CFG generated from static analysis can be an overestimation of the true program flow. Moreover, the size of programs often does not allow a graph neural network with fixed layers to aggregate global information. To address these issues, we propose DeepEXE, an agent-based implicit neural network that mimics the execution path of a program. We use reinforcement learning to enhance the branching decision at every program state transition and create a dynamic environment to learn the dependency between a vulnerability and certain program states. An implicitly defined neural network enables nearly infinite state transitions until convergence, which captures the structural information at a higher level. The experiments are conducted on two semi-synthetic and two real-world datasets. We show that DeepEXE is an accurate and efficient method and outperforms the state-of-the-art vulnerability detection methods.
Pluvio: Assembly Clone Search for Out-of-domain Architectures and Libraries through Transfer Learning and Conditional Variational Information Bottleneck
Jul 20, 2023



The practice of code reuse is crucial in software development for a faster and more efficient development lifecycle. In reality, however, code reuse practices lack proper control, resulting in issues such as vulnerability propagation and intellectual property infringements. Assembly clone search, a critical shift-right defence mechanism, has been effective in identifying vulnerable code resulting from reuse in released executables. Recent studies on assembly clone search demonstrate a trend towards using machine learning-based methods to match assembly code variants produced by different toolchains. However, these methods are limited to what they learn from a small number of toolchain variants used in training, rendering them inapplicable to unseen architectures and their corresponding compilation toolchain variants. This paper presents the first study on the problem of assembly clone search with unseen architectures and libraries. We propose incorporating human common knowledge through large-scale pre-trained natural language models, in the form of transfer learning, into current learning-based approaches for assembly clone search. Transfer learning can aid in addressing the limitations of the existing approaches, as it can bring in broader knowledge from human experts in assembly code. We further address the sequence limit issue by proposing a reinforcement learning agent to remove unnecessary and redundant tokens. Coupled with a new Variational Information Bottleneck learning strategy, the proposed system minimizes the reliance on potential indicators of architectures and optimization settings, for a better generalization of unseen architectures. We simulate the unseen architecture clone search scenarios and the experimental results show the effectiveness of the proposed approach against the state-of-the-art solutions.
On the Effectiveness of Interpretable Feedforward Neural Network
Nov 03, 2021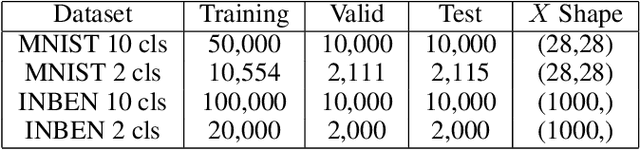
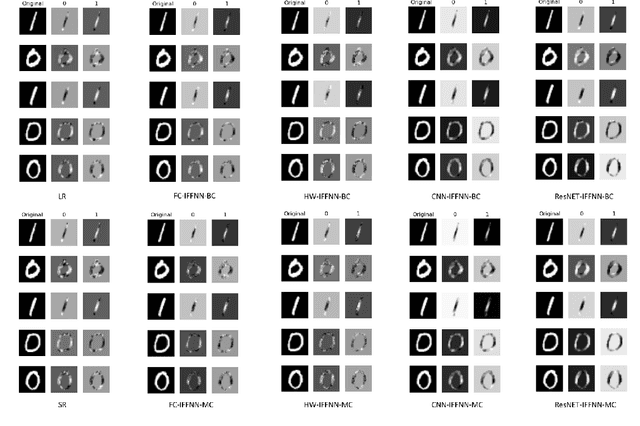


Deep learning models have achieved state-of-the-art performance in many classification tasks. However, most of them cannot provide an interpretation for their classification results. Machine learning models that are interpretable are usually linear or piecewise linear and yield inferior performance. Non-linear models achieve much better classification performance, but it is hard to interpret their classification results. This may have been changed by an interpretable feedforward neural network (IFFNN) proposed that achieves both high classification performance and interpretability for malware detection. If the IFFNN can perform well in a more flexible and general form for other classification tasks while providing meaningful interpretations, it may be of great interest to the applied machine learning community. In this paper, we propose a way to generalize the interpretable feedforward neural network to multi-class classification scenarios and any type of feedforward neural networks, and evaluate its classification performance and interpretability on intrinsic interpretable datasets. We conclude by finding that the generalized IFFNNs achieve comparable classification performance to their normal feedforward neural network counterparts and provide meaningful interpretations. Thus, this kind of neural network architecture has great practical use.
The Topic Confusion Task: A Novel Scenario for Authorship Attribution
Apr 17, 2021
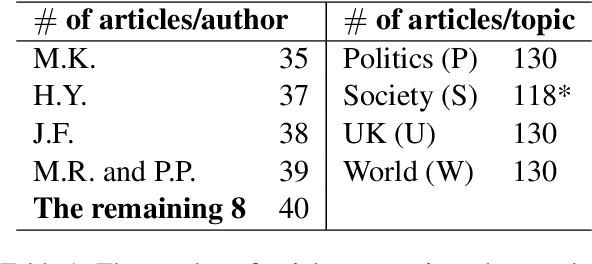
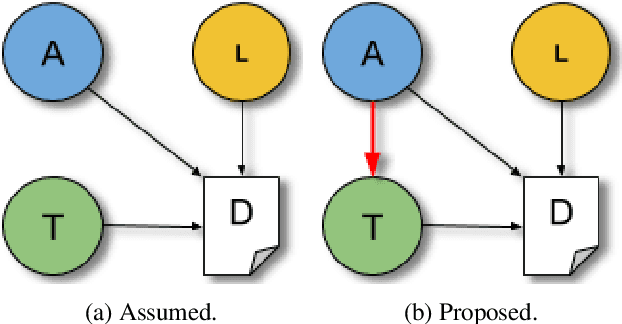
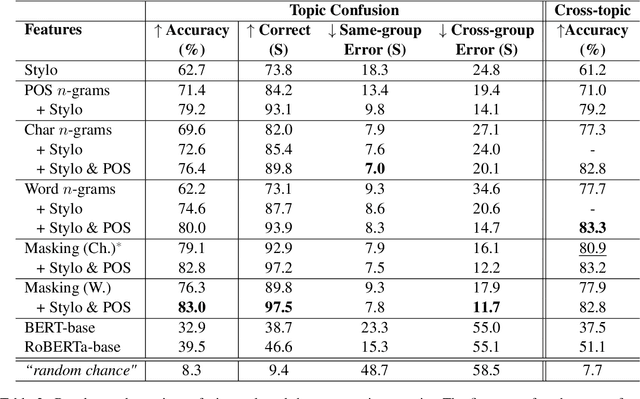
Authorship attribution is the problem of identifying the most plausible author of an anonymous text from a set of candidate authors. Researchers have investigated same-topic and cross-topic scenarios of authorship attribution, which differ according to whether unseen topics are used in the testing phase. However, neither scenario allows us to explain whether errors are caused by failure to capture authorship style, by the topic shift or by other factors. Motivated by this, we propose the \emph{topic confusion} task, where we switch the author-topic configuration between training and testing set. This setup allows us to probe errors in the attribution process. We investigate the accuracy and two error measures: one caused by the models' confusion by the switch because the features capture the topics, and one caused by the features' inability to capture the writing styles, leading to weaker models. By evaluating different features, we show that stylometric features with part-of-speech tags are less susceptible to topic variations and can increase the accuracy of the attribution process. We further show that combining them with word-level $n$-grams can outperform the state-of-the-art technique in the cross-topic scenario. Finally, we show that pretrained language models such as BERT and RoBERTa perform poorly on this task, and are outperformed by simple $n$-gram features.
Learning Inter-Modal Correspondence and Phenotypes from Multi-Modal Electronic Health Records
Nov 12, 2020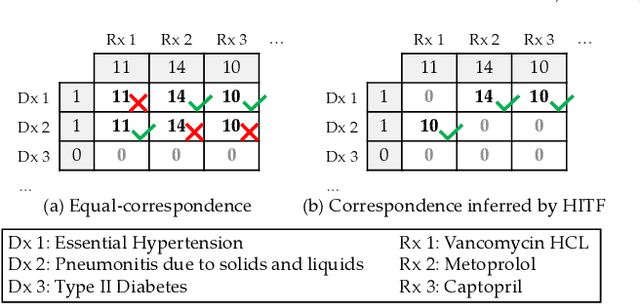
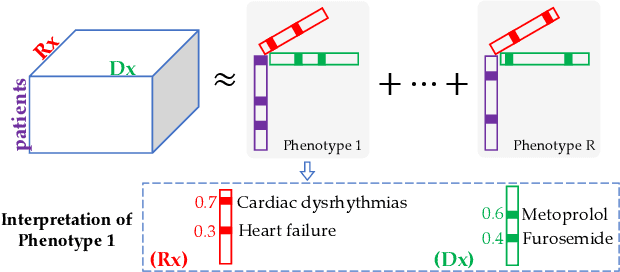

Non-negative tensor factorization has been shown a practical solution to automatically discover phenotypes from the electronic health records (EHR) with minimal human supervision. Such methods generally require an input tensor describing the inter-modal interactions to be pre-established; however, the correspondence between different modalities (e.g., correspondence between medications and diagnoses) can often be missing in practice. Although heuristic methods can be applied to estimate them, they inevitably introduce errors, and leads to sub-optimal phenotype quality. This is particularly important for patients with complex health conditions (e.g., in critical care) as multiple diagnoses and medications are simultaneously present in the records. To alleviate this problem and discover phenotypes from EHR with unobserved inter-modal correspondence, we propose the collective hidden interaction tensor factorization (cHITF) to infer the correspondence between multiple modalities jointly with the phenotype discovery. We assume that the observed matrix for each modality is marginalization of the unobserved inter-modal correspondence, which are reconstructed by maximizing the likelihood of the observed matrices. Extensive experiments conducted on the real-world MIMIC-III dataset demonstrate that cHITF effectively infers clinically meaningful inter-modal correspondence, discovers phenotypes that are more clinically relevant and diverse, and achieves better predictive performance compared with a number of state-of-the-art computational phenotyping models.
Deep Learning-based Stress Determinator for Mouse Psychiatric Analysis using Hippocampus Activity
Jun 27, 2020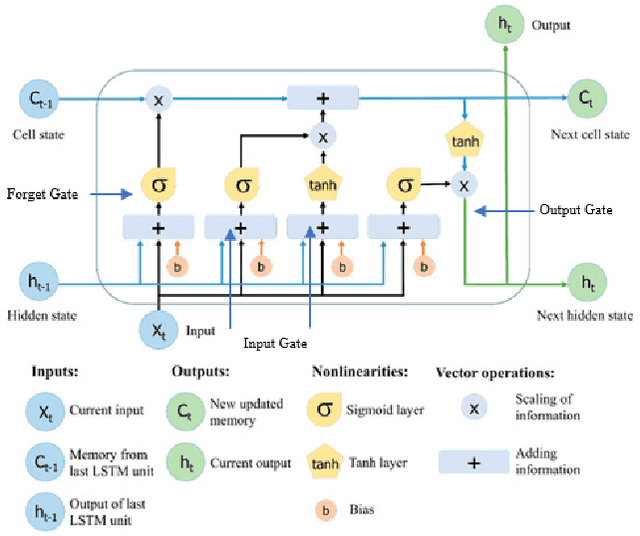

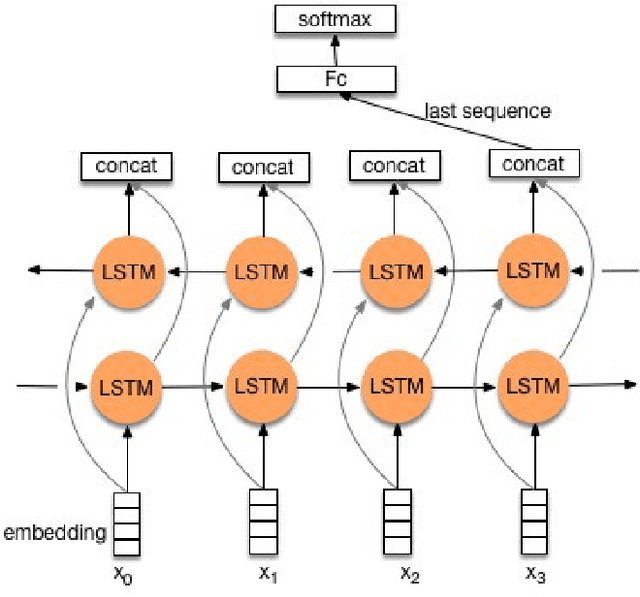
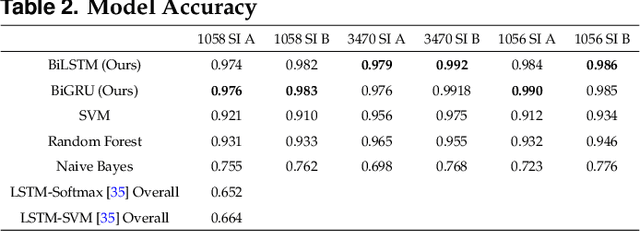
Decoding neurons to extract information from transmission and employ them into other use is the goal of neuroscientists' study. Due to that the field of neuroscience is utilizing the traditional methods presently, we hence combine the state-of-the-art deep learning techniques with the theory of neuron decoding to discuss its potential of accomplishment. Besides, the stress level that is related to neuron activity in hippocampus is statistically examined as well. The experiments suggest that our state-of-the-art deep learning-based stress determinator provides good performance with respect to its model prediction accuracy and additionally, there is strong evidence against equivalence of mouse stress level under diverse environments.