 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Neural Control Flow Execution: An Agent-Based Deep Equilibrium Approach for Binary Vulnerability Detection
Apr 03, 2024



Software vulnerabilities are a challenge in cybersecurity. Manual security patches are often difficult and slow to be deployed, while new vulnerabilities are created. Binary code vulnerability detection is less studied and more complex compared to source code, and this has important practical implications. Deep learning has become an efficient and powerful tool in the security domain, where it provides end-to-end and accurate prediction. Modern deep learning approaches learn the program semantics through sequence and graph neural networks, using various intermediate representation of programs, such as abstract syntax trees (AST) or control flow graphs (CFG). Due to the complex nature of program execution, the output of an execution depends on the many program states and inputs. Also, a CFG generated from static analysis can be an overestimation of the true program flow. Moreover, the size of programs often does not allow a graph neural network with fixed layers to aggregate global information. To address these issues, we propose DeepEXE, an agent-based implicit neural network that mimics the execution path of a program. We use reinforcement learning to enhance the branching decision at every program state transition and create a dynamic environment to learn the dependency between a vulnerability and certain program states. An implicitly defined neural network enables nearly infinite state transitions until convergence, which captures the structural information at a higher level. The experiments are conducted on two semi-synthetic and two real-world datasets. We show that DeepEXE is an accurate and efficient method and outperforms the state-of-the-art vulnerability detection methods.
Pluvio: Assembly Clone Search for Out-of-domain Architectures and Libraries through Transfer Learning and Conditional Variational Information Bottleneck
Jul 20, 2023



The practice of code reuse is crucial in software development for a faster and more efficient development lifecycle. In reality, however, code reuse practices lack proper control, resulting in issues such as vulnerability propagation and intellectual property infringements. Assembly clone search, a critical shift-right defence mechanism, has been effective in identifying vulnerable code resulting from reuse in released executables. Recent studies on assembly clone search demonstrate a trend towards using machine learning-based methods to match assembly code variants produced by different toolchains. However, these methods are limited to what they learn from a small number of toolchain variants used in training, rendering them inapplicable to unseen architectures and their corresponding compilation toolchain variants. This paper presents the first study on the problem of assembly clone search with unseen architectures and libraries. We propose incorporating human common knowledge through large-scale pre-trained natural language models, in the form of transfer learning, into current learning-based approaches for assembly clone search. Transfer learning can aid in addressing the limitations of the existing approaches, as it can bring in broader knowledge from human experts in assembly code. We further address the sequence limit issue by proposing a reinforcement learning agent to remove unnecessary and redundant tokens. Coupled with a new Variational Information Bottleneck learning strategy, the proposed system minimizes the reliance on potential indicators of architectures and optimization settings, for a better generalization of unseen architectures. We simulate the unseen architecture clone search scenarios and the experimental results show the effectiveness of the proposed approach against the state-of-the-art solutions.
I-MAD: A Novel Interpretable Malware Detector Using Hierarchical Transformer
Sep 26, 2019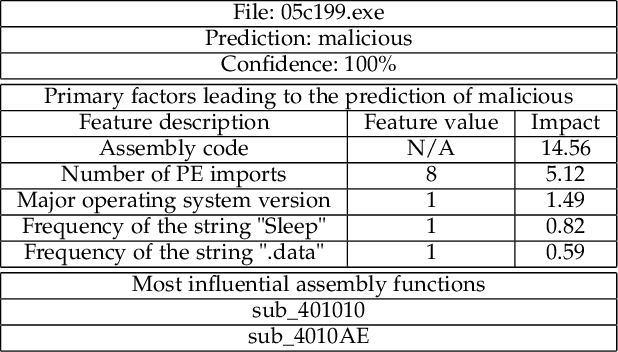
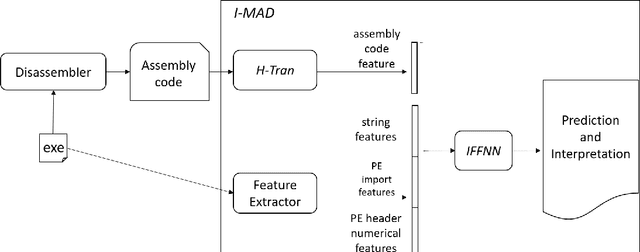


Malware imposes tremendous threats to computer users nowadays. Since signature-based malware detection methods are neither effective nor efficient to identify new malware, many machine learning-based methods have been proposed. A common disadvantage of existing machine learning methods is that they are not based on understanding the full semantic meaning of assembly code of an executable. They rather use short assembly code fragments, because assembly code is usually too long to be modelled in its entirety. Another disadvantage is that those methods have either inferior performance or bad interpretability. To overcome these challenges, we propose an Interpretable MAware Detector (I-MAD), which achieves state-of-the-art performance on static malware detection with excellent interpretability. It integrates a hierarchical Transformer network that can understand assembly code at the basic block, function, and executable level. It also integrates our novel interpretable feed-forward neural network to provide interpretations for its detection results by pointing out the impact of each feature with respect to the prediction. Experiment results show that our model significantly outperforms previous state-of-the-art static malware detection models and presents meaningful interpretations.
ER-AE: Differentially-private Text Generation for Authorship Anonymization
Sep 10, 2019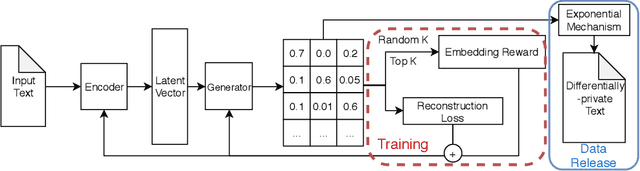
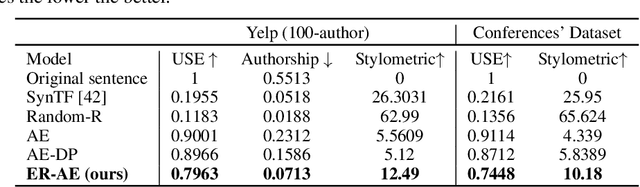

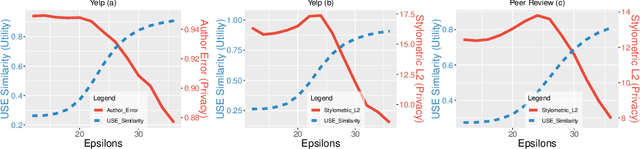
Most of privacy protection studies for textual data focus on removing explicit sensitive identifiers. However, personal writing style, as a strong indicator of the authorship, is often neglected. Recent studies on writing style anonymization can only output numeric vectors which are difficult for the recipients to interpret. We propose a novel text generation model with the exponential mechanism for authorship anonymization. By augmenting the semantic information through a REINFORCE training reward function, the model can generate differentially-private text that has a close semantic and similar grammatical structure to the original text while removing personal traits of the writing style. It does not assume any conditioned labels or paralleled text data for training. We evaluate the performance of the proposed model on the real-life peer reviews dataset and the Yelp review dataset. The result suggests that our model outperforms the state-of-the-art on semantic preservation, authorship obfuscation, and stylometric transformation.
Learning Stylometric Representations for Authorship Analysis
Jun 03, 2016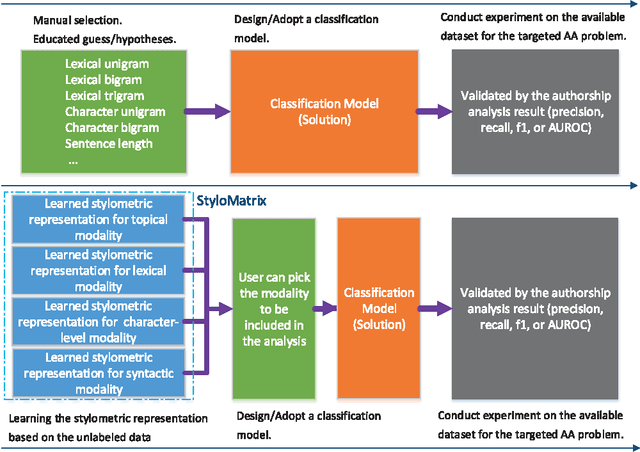
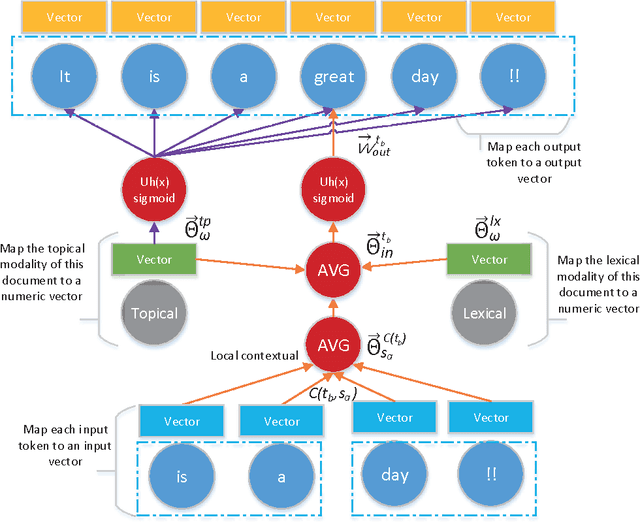
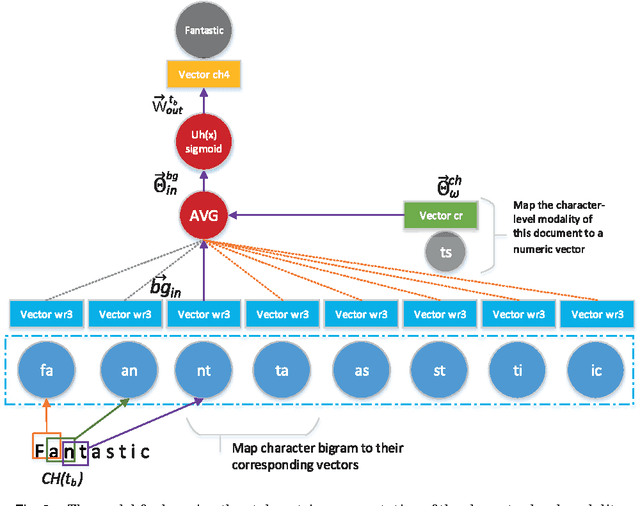
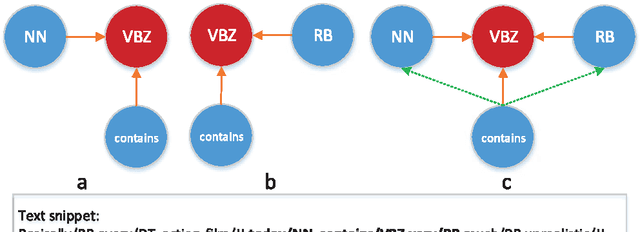
Authorship analysis (AA) is the study of unveiling the hidden properties of authors from a body of exponentially exploding textual data. It extracts an author's identity and sociolinguistic characteristics based on the reflected writing styles in the text. It is an essential process for various areas, such as cybercrime investigation, psycholinguistics, political socialization, etc. However, most of the previous techniques critically depend on the manual feature engineering process. Consequently, the choice of feature set has been shown to be scenario- or dataset-dependent. In this paper, to mimic the human sentence composition process using a neural network approach, we propose to incorporate different categories of linguistic features into distributed representation of words in order to learn simultaneously the writing style representations based on unlabeled texts for authorship analysis. In particular, the proposed models allow topical, lexical, syntactical, and character-level feature vectors of each document to be extracted as stylometrics. We evaluate the performance of our approach on the problems of authorship characterization and authorship verification with the Twitter, novel, and essay datasets. The experiments suggest that our proposed text representation outperforms the bag-of-lexical-n-grams, Latent Dirichlet Allocation, Latent Semantic Analysis, PVDM, PVDBOW, and word2vec representations.