 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Spot Phishing Emails with Surprising Accuracy: A Comparative Analysis of Performance
Apr 23, 2024


Phishing, a prevalent cybercrime tactic for decades, remains a significant threat in today's digital world. By leveraging clever social engineering elements and modern technology, cybercrime targets many individuals, businesses, and organizations to exploit trust and security. These cyber-attackers are often disguised in many trustworthy forms to appear as legitimate sources. By cleverly using psychological elements like urgency, fear, social proof, and other manipulative strategies, phishers can lure individuals into revealing sensitive and personalized information. Building on this pervasive issue within modern technology, this paper aims to analyze the effectiveness of 15 Large Language Models (LLMs) in detecting phishing attempts, specifically focusing on a randomized set of "419 Scam" emails. The objective is to determine which LLMs can accurately detect phishing emails by analyzing a text file containing email metadata based on predefined criteria. The experiment concluded that the following models, ChatGPT 3.5, GPT-3.5-Turbo-Instruct, and ChatGPT, were the most effective in detecting phishing emails.
ER-AE: Differentially-private Text Generation for Authorship Anonymization
Sep 10, 2019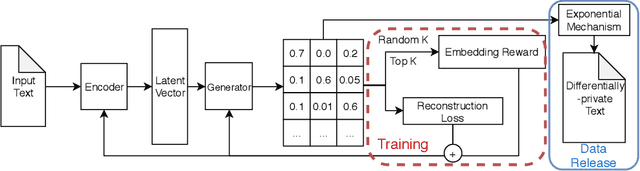
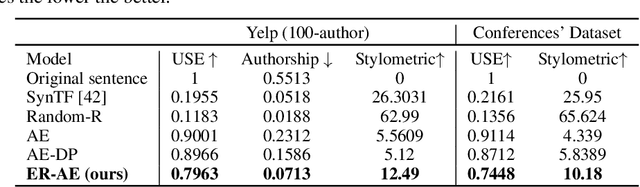

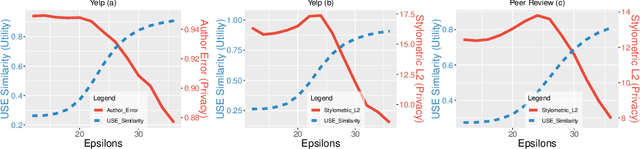
Most of privacy protection studies for textual data focus on removing explicit sensitive identifiers. However, personal writing style, as a strong indicator of the authorship, is often neglected. Recent studies on writing style anonymization can only output numeric vectors which are difficult for the recipients to interpret. We propose a novel text generation model with the exponential mechanism for authorship anonymization. By augmenting the semantic information through a REINFORCE training reward function, the model can generate differentially-private text that has a close semantic and similar grammatical structure to the original text while removing personal traits of the writing style. It does not assume any conditioned labels or paralleled text data for training. We evaluate the performance of the proposed model on the real-life peer reviews dataset and the Yelp review dataset. The result suggests that our model outperforms the state-of-the-art on semantic preservation, authorship obfuscation, and stylometric transformation.
Learning Stylometric Representations for Authorship Analysis
Jun 03, 2016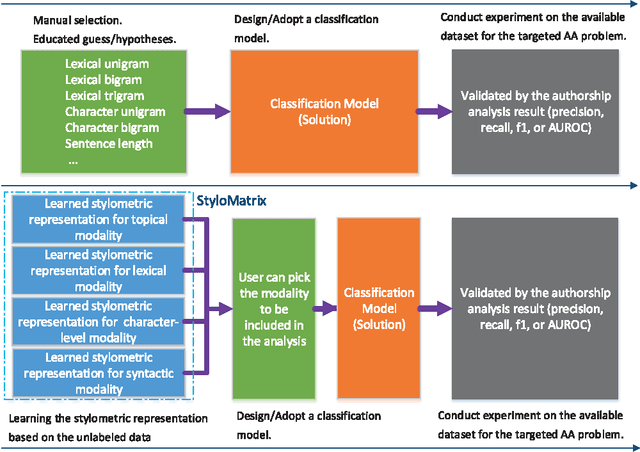
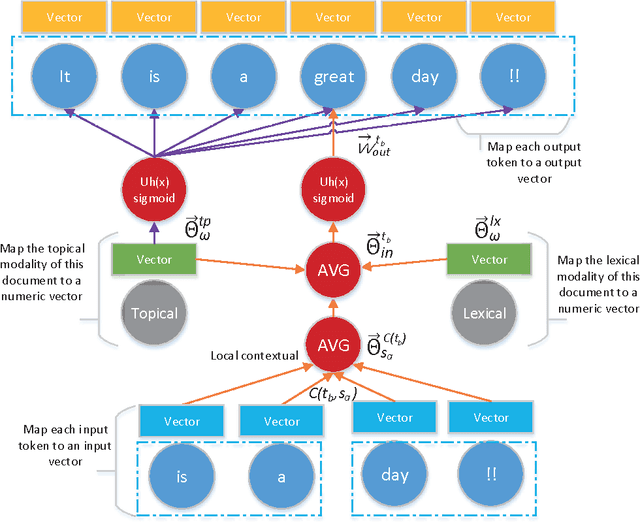
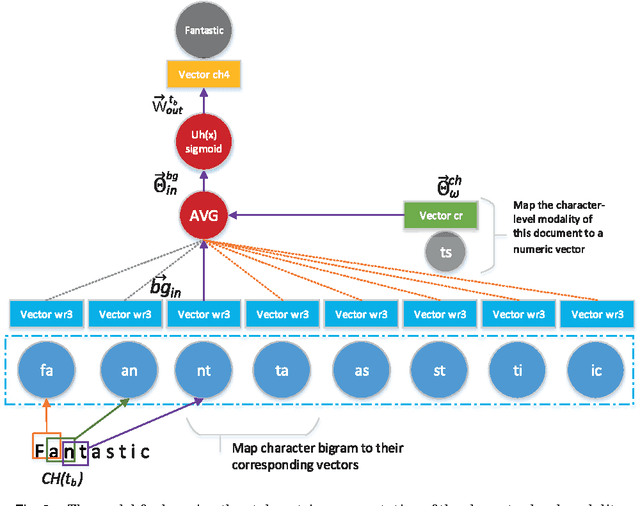
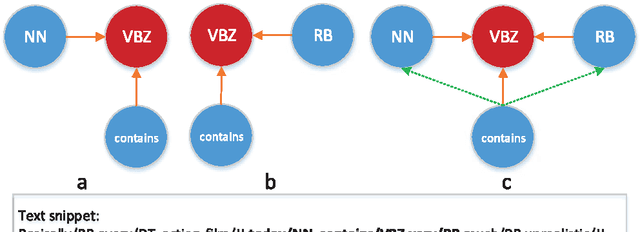
Authorship analysis (AA) is the study of unveiling the hidden properties of authors from a body of exponentially exploding textual data. It extracts an author's identity and sociolinguistic characteristics based on the reflected writing styles in the text. It is an essential process for various areas, such as cybercrime investigation, psycholinguistics, political socialization, etc. However, most of the previous techniques critically depend on the manual feature engineering process. Consequently, the choice of feature set has been shown to be scenario- or dataset-dependent. In this paper, to mimic the human sentence composition process using a neural network approach, we propose to incorporate different categories of linguistic features into distributed representation of words in order to learn simultaneously the writing style representations based on unlabeled texts for authorship analysis. In particular, the proposed models allow topical, lexical, syntactical, and character-level feature vectors of each document to be extracted as stylometrics. We evaluate the performance of our approach on the problems of authorship characterization and authorship verification with the Twitter, novel, and essay datasets. The experiments suggest that our proposed text representation outperforms the bag-of-lexical-n-grams, Latent Dirichlet Allocation, Latent Semantic Analysis, PVDM, PVDBOW, and word2vec representations.