 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Multimodal Learning Help in Healthcare? A Benchmark on EHR and Chest X-Ray Fusion
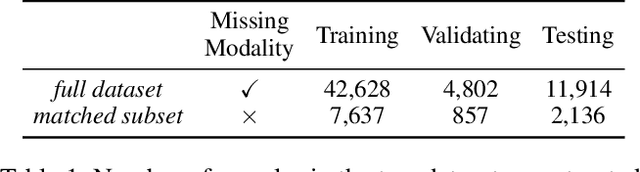
Feb 27, 2026Machine learning holds promise for advancing clinical decision support, yet it remains unclear when multimodal learning truly helps in practice, particularly under modality missingness and fairness constraints. In this work, we conduct a systematic benchmark of multimodal fusion between Electronic Health Records (EHR) and chest X-rays (CXR) on standardized cohorts from MIMIC-IV and MIMIC-CXR, aiming to answer four fundamental questions: when multimodal fusion improves clinical prediction, how different fusion strategies compare, how robust existing methods are to missing modalities, and whether multimodal models achieve algorithmic fairness. Our study reveals several key insights. Multimodal fusion improves performance when modalities are complete, with gains concentrating in diseases that require complementary information from both EHR and CXR. While cross-modal learning mechanisms capture clinically meaningful dependencies beyond simple concatenation, the rich temporal structure of EHR introduces strong modality imbalance that architectural complexity alone cannot overcome. Under realistic missingness, multimodal benefits rapidly degrade unless models are explicitly designed to handle incomplete inputs. Moreover, multimodal fusion does not inherently improve fairness, with subgroup disparities mainly arising from unequal sensitivity across demographic groups. To support reproducible and extensible evaluation, we further release a flexible benchmarking toolkit that enables plug-and-play integration of new models and datasets. Together, this work provides actionable guidance on when multimodal learning helps, when it fails, and why, laying the foundation for developing clinically deployable multimodal systems that are both effective and reliable. The open-source toolkit can be found at https://github.com/jakeykj/CareBench.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Addressing Asynchronicity in Clinical Multimodal Fusion via Individualized Chest X-ray Generation
Oct 23, 2024



Integrating multi-modal clinical data, such as electronic health records (EHR) and chest X-ray images (CXR), is particularly beneficial for clinical prediction tasks. However, in a temporal setting, multi-modal data are often inherently asynchronous. EHR can be continuously collected but CXR is generally taken with a much longer interval due to its high cost and radiation dose. When clinical prediction is needed, the last available CXR image might have been outdated, leading to suboptimal predictions. To address this challenge, we propose DDL-CXR, a method that dynamically generates an up-to-date latent representation of the individualized CXR images. Our approach leverages latent diffusion models for patient-specific generation strategically conditioned on a previous CXR image and EHR time series, providing information regarding anatomical structures and disease progressions, respectively. In this way, the interaction across modalities could be better captured by the latent CXR generation process, ultimately improving the prediction performance. Experiments using MIMIC datasets show that the proposed model could effectively address asynchronicity in multimodal fusion and consistently outperform existing methods.
Large Language Models as Partners in Student Essay Evaluation
May 28, 2024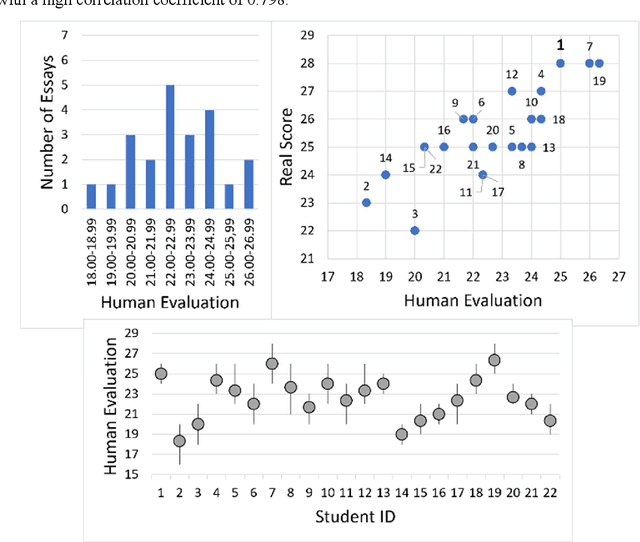

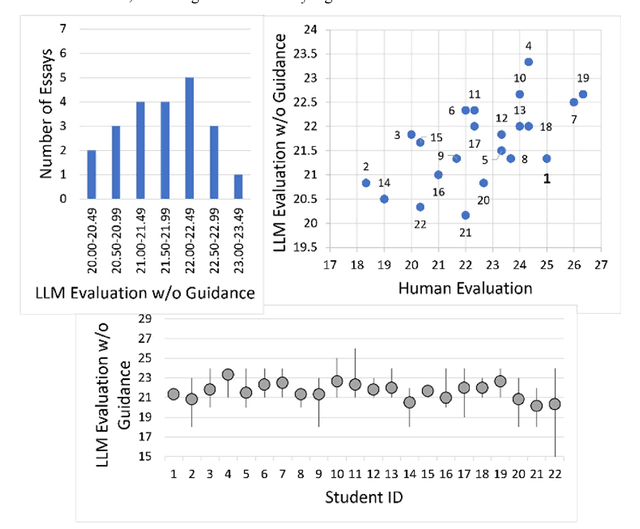
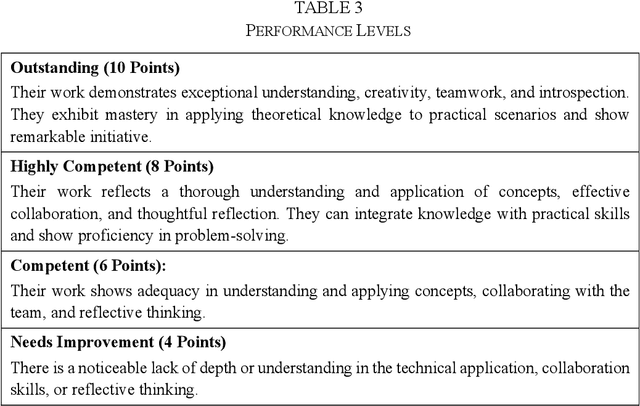
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.
DrFuse: Learning Disentangled Representation for Clinical Multi-Modal Fusion with Missing Modality and Modal Inconsistency
Mar 10, 2024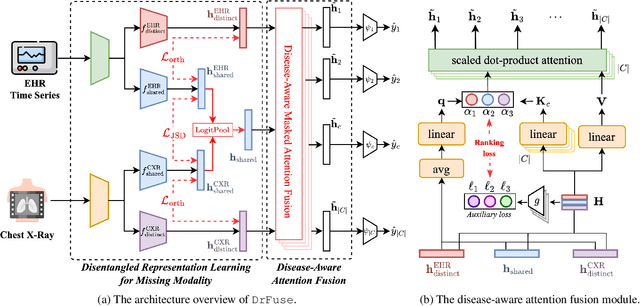
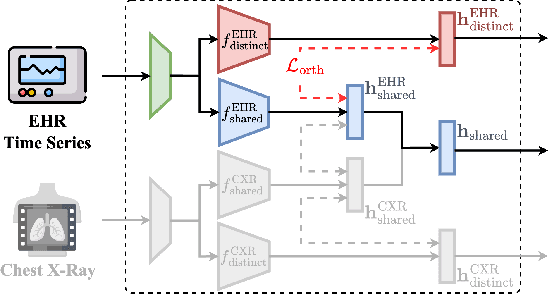
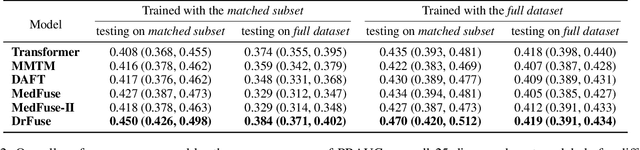
The combination of electronic health records (EHR) and medical images is crucial for clinicians in making diagnoses and forecasting prognosis. Strategically fusing these two data modalities has great potential to improve the accuracy of machine learning models in clinical prediction tasks. However, the asynchronous and complementary nature of EHR and medical images presents unique challenges. Missing modalities due to clinical and administrative factors are inevitable in practice, and the significance of each data modality varies depending on the patient and the prediction target, resulting in inconsistent predictions and suboptimal model performance. To address these challenges, we propose DrFuse to achieve effective clinical multi-modal fusion. It tackles the missing modality issue by disentangling the features shared across modalities and those unique within each modality. Furthermore, we address the modal inconsistency issue via a disease-wise attention layer that produces the patient- and disease-wise weighting for each modality to make the final prediction. We validate the proposed method using real-world large-scale datasets, MIMIC-IV and MIMIC-CXR. Experimental results show that the proposed method significantly outperforms the state-of-the-art models. Our implementation is publicly available at https://github.com/dorothy-yao/drfuse.
WL-Align: Weisfeiler-Lehman Relabeling for Aligning Users across Networks via Regularized Representation Learning
Dec 29, 2022



Aligning users across networks using graph representation learning has been found effective where the alignment is accomplished in a low-dimensional embedding space. Yet, achieving highly precise alignment is still challenging, especially when nodes with long-range connectivity to the labeled anchors are encountered. To alleviate this limitation, we purposefully designed WL-Align which adopts a regularized representation learning framework to learn distinctive node representations. It extends the Weisfeiler-Lehman Isormorphism Test and learns the alignment in alternating phases of "across-network Weisfeiler-Lehman relabeling" and "proximity-preserving representation learning". The across-network Weisfeiler-Lehman relabeling is achieved through iterating the anchor-based label propagation and a similarity-based hashing to exploit the known anchors' connectivity to different nodes in an efficient and robust manner. The representation learning module preserves the second-order proximity within individual networks and is regularized by the across-network Weisfeiler-Lehman hash labels. Extensive experiments on real-world and synthetic datasets have demonstrated that our proposed WL-Align outperforms the state-of-the-art methods, achieving significant performance improvements in the "exact matching" scenario. Data and code of WL-Align are available at https://github.com/ChenPengGang/WLAlignCode.
Attributed Abnormality Graph Embedding for Clinically Accurate X-Ray Report Generation
Jul 05, 2022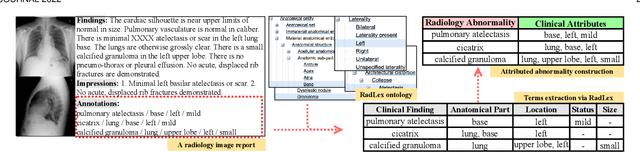
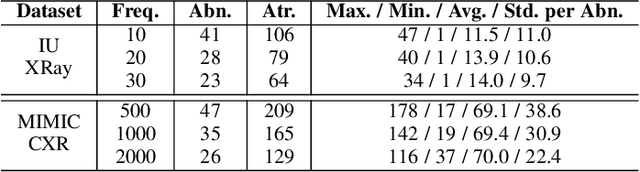
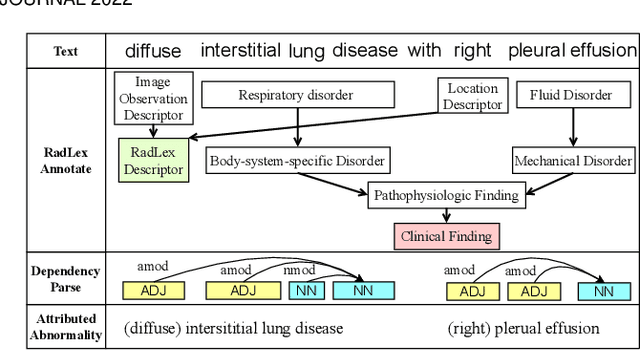
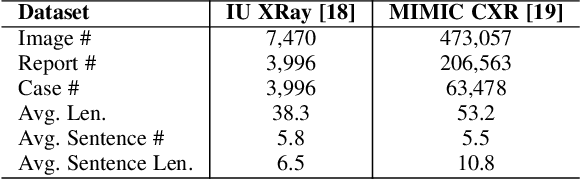
Automatic generation of medical reports from X-ray images can assist radiologists to perform the time-consuming and yet important reporting task. Yet, achieving clinically accurate generated reports remains challenging. Modeling the underlying abnormalities using the knowledge graph approach has been found promising in enhancing the clinical accuracy. In this paper, we introduce a novel fined-grained knowledge graph structure called an attributed abnormality graph (ATAG). The ATAG consists of interconnected abnormality nodes and attribute nodes, allowing it to better capture the abnormality details. In contrast to the existing methods where the abnormality graph was constructed manually, we propose a methodology to automatically construct the fine-grained graph structure based on annotations, medical reports in X-ray datasets, and the RadLex radiology lexicon. We then learn the ATAG embedding using a deep model with an encoder-decoder architecture for the report generation. In particular, graph attention networks are explored to encode the relationships among the abnormalities and their attributes. A gating mechanism is adopted and integrated with various decoders for the generation. We carry out extensive experiments based on the benchmark datasets, and show that the proposed ATAG-based deep model outperforms the SOTA methods by a large margin and can improve the clinical accuracy of the generated reports.
Towards Improving Embedding Based Models of Social Network Alignment via Pseudo Anchors
Nov 22, 2021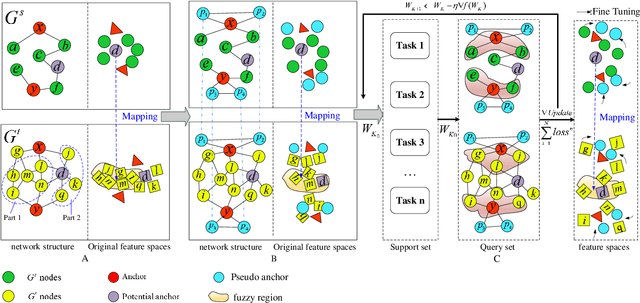
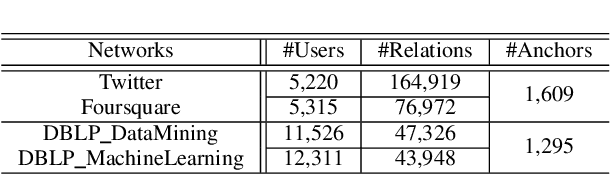
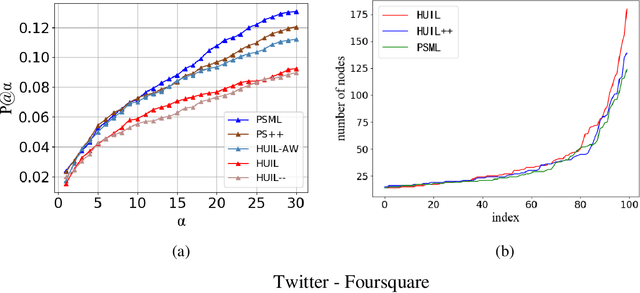
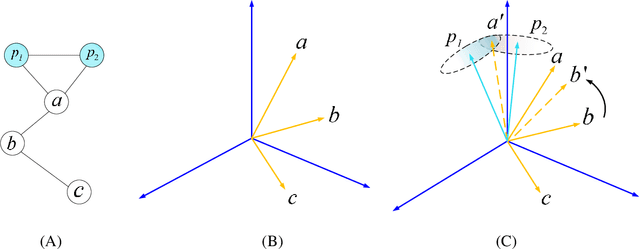
Social network alignment aims at aligning person identities across social networks. Embedding based models have been shown effective for the alignment where the structural proximity preserving objective is typically adopted for the model training. With the observation that ``overly-close'' user embeddings are unavoidable for such models causing alignment inaccuracy, we propose a novel learning framework which tries to enforce the resulting embeddings to be more widely apart among the users via the introduction of carefully implanted pseudo anchors. We further proposed a meta-learning algorithm to guide the updating of the pseudo anchor embeddings during the learning process. The proposed intervention via the use of pseudo anchors and meta-learning allows the learning framework to be applicable to a wide spectrum of network alignment methods. We have incorporated the proposed learning framework into several state-of-the-art models. Our experimental results demonstrate its efficacy where the methods with the pseudo anchors implanted can outperform their counterparts without pseudo anchors by a fairly large margin, especially when there only exist very few labeled anchors.
TOHAN: A One-step Approach towards Few-shot Hypothesis Adaptation
Jun 11, 2021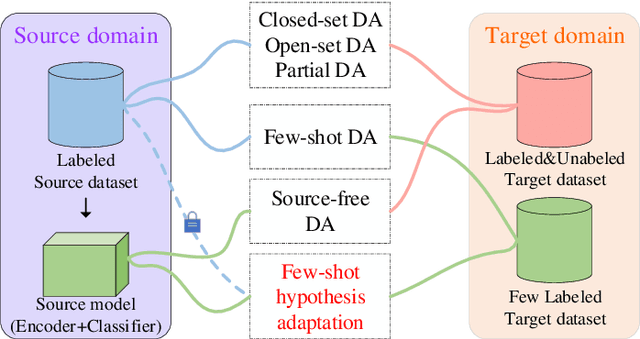
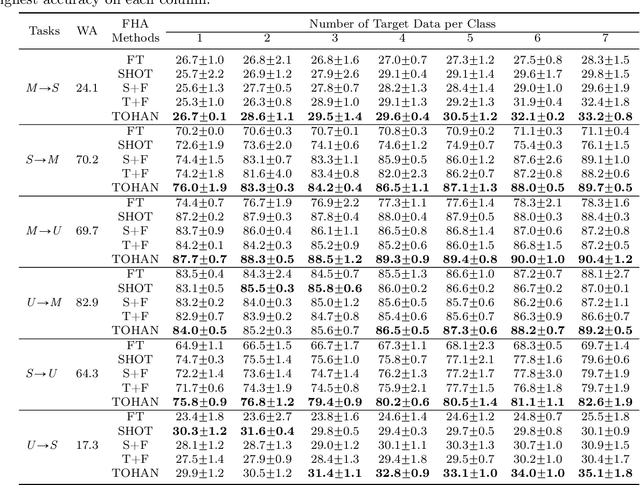
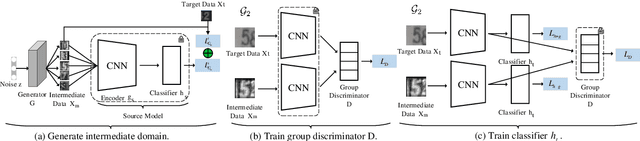

In few-shot domain adaptation (FDA), classifiers for the target domain are trained with accessible labeled data in the source domain (SD) and few labeled data in the target domain (TD). However, data usually contain private information in the current era, e.g., data distributed on personal phones. Thus, the private information will be leaked if we directly access data in SD to train a target-domain classifier (required by FDA methods). In this paper, to thoroughly prevent the privacy leakage in SD, we consider a very challenging problem setting, where the classifier for the TD has to be trained using few labeled target data and a well-trained SD classifier, named few-shot hypothesis adaptation (FHA). In FHA, we cannot access data in SD, as a result, the private information in SD will be protected well. To this end, we propose a target orientated hypothesis adaptation network (TOHAN) to solve the FHA problem, where we generate highly-compatible unlabeled data (i.e., an intermediate domain) to help train a target-domain classifier. TOHAN maintains two deep networks simultaneously, where one focuses on learning an intermediate domain and the other takes care of the intermediate-to-target distributional adaptation and the target-risk minimization. Experimental results show that TOHAN outperforms competitive baselines significantly.
Learning Inter-Modal Correspondence and Phenotypes from Multi-Modal Electronic Health Records
Nov 12, 2020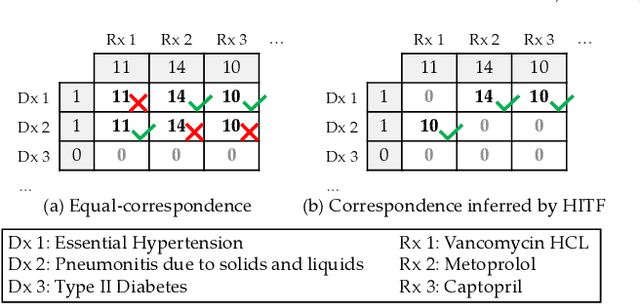
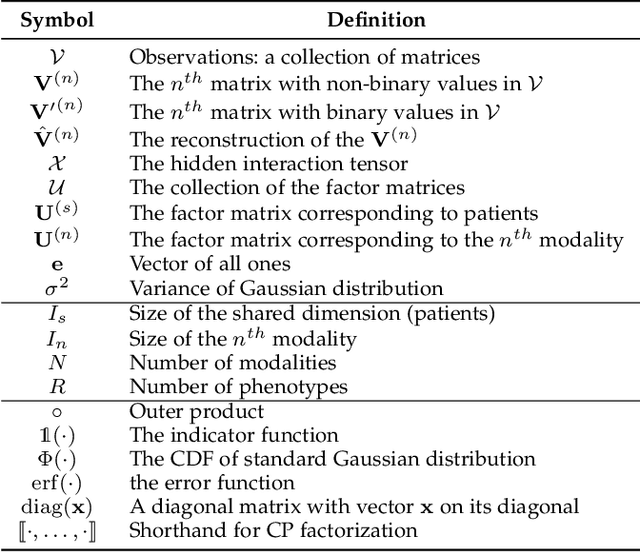
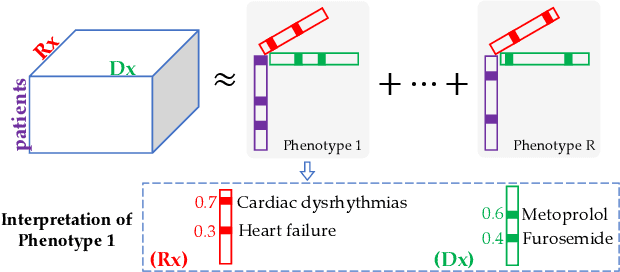

Non-negative tensor factorization has been shown a practical solution to automatically discover phenotypes from the electronic health records (EHR) with minimal human supervision. Such methods generally require an input tensor describing the inter-modal interactions to be pre-established; however, the correspondence between different modalities (e.g., correspondence between medications and diagnoses) can often be missing in practice. Although heuristic methods can be applied to estimate them, they inevitably introduce errors, and leads to sub-optimal phenotype quality. This is particularly important for patients with complex health conditions (e.g., in critical care) as multiple diagnoses and medications are simultaneously present in the records. To alleviate this problem and discover phenotypes from EHR with unobserved inter-modal correspondence, we propose the collective hidden interaction tensor factorization (cHITF) to infer the correspondence between multiple modalities jointly with the phenotype discovery. We assume that the observed matrix for each modality is marginalization of the unobserved inter-modal correspondence, which are reconstructed by maximizing the likelihood of the observed matrices. Extensive experiments conducted on the real-world MIMIC-III dataset demonstrate that cHITF effectively infers clinically meaningful inter-modal correspondence, discovers phenotypes that are more clinically relevant and diverse, and achieves better predictive performance compared with a number of state-of-the-art computational phenotyping models.