 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Asynchronicity in Clinical Multimodal Fusion via Individualized Chest X-ray Generation
Oct 23, 2024



Integrating multi-modal clinical data, such as electronic health records (EHR) and chest X-ray images (CXR), is particularly beneficial for clinical prediction tasks. However, in a temporal setting, multi-modal data are often inherently asynchronous. EHR can be continuously collected but CXR is generally taken with a much longer interval due to its high cost and radiation dose. When clinical prediction is needed, the last available CXR image might have been outdated, leading to suboptimal predictions. To address this challenge, we propose DDL-CXR, a method that dynamically generates an up-to-date latent representation of the individualized CXR images. Our approach leverages latent diffusion models for patient-specific generation strategically conditioned on a previous CXR image and EHR time series, providing information regarding anatomical structures and disease progressions, respectively. In this way, the interaction across modalities could be better captured by the latent CXR generation process, ultimately improving the prediction performance. Experiments using MIMIC datasets show that the proposed model could effectively address asynchronicity in multimodal fusion and consistently outperform existing methods.
DrFuse: Learning Disentangled Representation for Clinical Multi-Modal Fusion with Missing Modality and Modal Inconsistency
Mar 10, 2024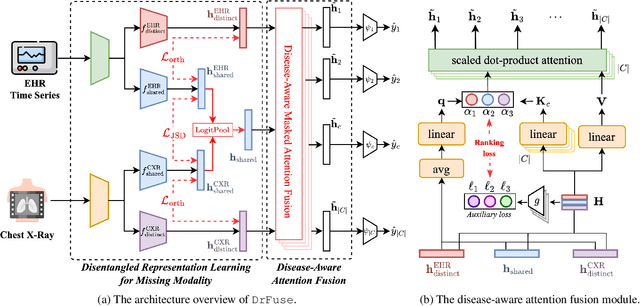
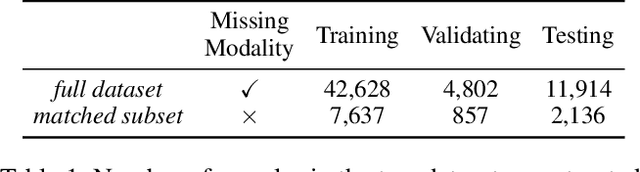
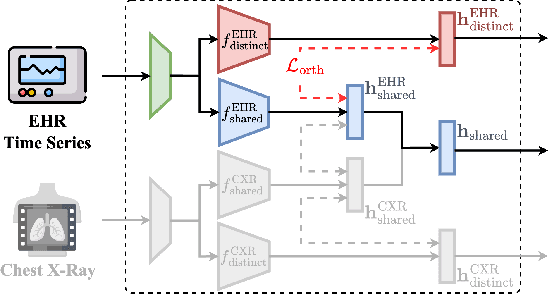
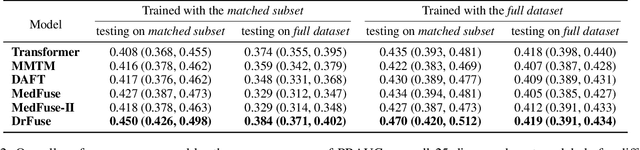
The combination of electronic health records (EHR) and medical images is crucial for clinicians in making diagnoses and forecasting prognosis. Strategically fusing these two data modalities has great potential to improve the accuracy of machine learning models in clinical prediction tasks. However, the asynchronous and complementary nature of EHR and medical images presents unique challenges. Missing modalities due to clinical and administrative factors are inevitable in practice, and the significance of each data modality varies depending on the patient and the prediction target, resulting in inconsistent predictions and suboptimal model performance. To address these challenges, we propose DrFuse to achieve effective clinical multi-modal fusion. It tackles the missing modality issue by disentangling the features shared across modalities and those unique within each modality. Furthermore, we address the modal inconsistency issue via a disease-wise attention layer that produces the patient- and disease-wise weighting for each modality to make the final prediction. We validate the proposed method using real-world large-scale datasets, MIMIC-IV and MIMIC-CXR. Experimental results show that the proposed method significantly outperforms the state-of-the-art models. Our implementation is publicly available at https://github.com/dorothy-yao/drfuse.
Learning Inter-Modal Correspondence and Phenotypes from Multi-Modal Electronic Health Records
Nov 12, 2020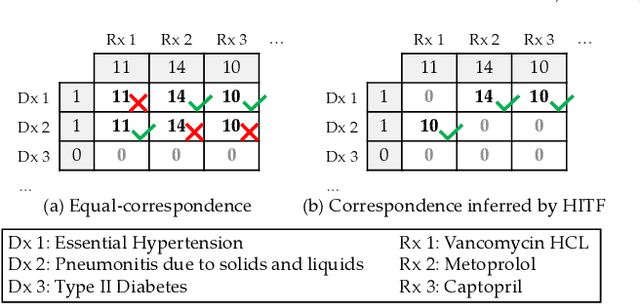
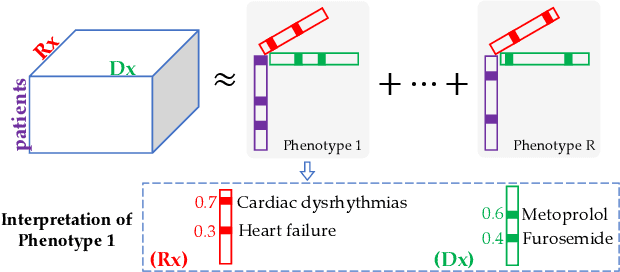

Non-negative tensor factorization has been shown a practical solution to automatically discover phenotypes from the electronic health records (EHR) with minimal human supervision. Such methods generally require an input tensor describing the inter-modal interactions to be pre-established; however, the correspondence between different modalities (e.g., correspondence between medications and diagnoses) can often be missing in practice. Although heuristic methods can be applied to estimate them, they inevitably introduce errors, and leads to sub-optimal phenotype quality. This is particularly important for patients with complex health conditions (e.g., in critical care) as multiple diagnoses and medications are simultaneously present in the records. To alleviate this problem and discover phenotypes from EHR with unobserved inter-modal correspondence, we propose the collective hidden interaction tensor factorization (cHITF) to infer the correspondence between multiple modalities jointly with the phenotype discovery. We assume that the observed matrix for each modality is marginalization of the unobserved inter-modal correspondence, which are reconstructed by maximizing the likelihood of the observed matrices. Extensive experiments conducted on the real-world MIMIC-III dataset demonstrate that cHITF effectively infers clinically meaningful inter-modal correspondence, discovers phenotypes that are more clinically relevant and diverse, and achieves better predictive performance compared with a number of state-of-the-art computational phenotyping models.
SWIFT: Scalable Wasserstein Factorization for Sparse Nonnegative Tensors
Oct 08, 2020


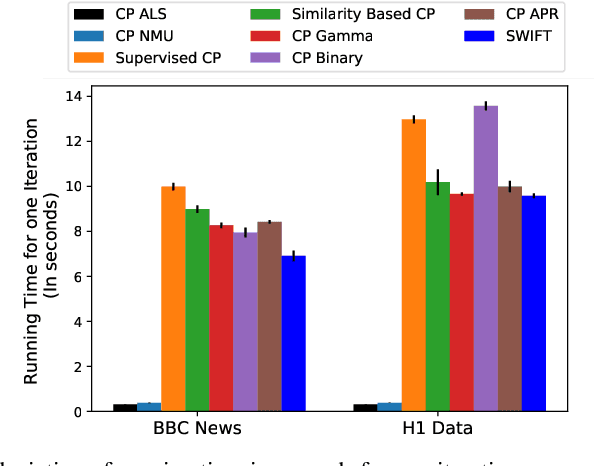
Existing tensor factorization methods assume that the input tensor follows some specific distribution (i.e. Poisson, Bernoulli and Gaussian), and solve the factorization by minimizing some empirical loss functions defined based on the corresponding distribution. However, it suffers from several drawbacks: 1) In reality, the underlying distributions are complicated and unknown, making it infeasible to be approximated by a simple distribution. 2) The correlation across dimensions of the input tensor is not well utilized, leading to sub-optimal performance. Although heuristics were proposed to incorporate such correlation as side information under Gaussian distribution, they can not easily be generalized to other distributions. Thus, a more principled way of utilizing the correlation in tensor factorization models is still an open challenge. Without assuming any explicit distribution, we formulate the tensor factorization as an optimal transport problem with Wasserstein distance, which can handle non-negative inputs. We introduce SWIFT, which minimizes the Wasserstein distance that measures the distance between the input tensor and that of the reconstruction. In particular, we define the N-th order tensor Wasserstein loss for the widely used tensor CP factorization, and derive the optimization algorithm that minimizes it. By leveraging sparsity structure and different equivalent formulations for optimizing computational efficiency, SWIFT is as scalable as other well-known CP algorithms. Using the factor matrices as features, SWIFT achieves up to 9.65% and 11.31% relative improvement over baselines for downstream prediction tasks. Under the noisy conditions, SWIFT achieves up to 15% and 17% relative improvements over the best competitors for the prediction tasks.