 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWIFT: Scalable Wasserstein Factorization for Sparse Nonnegative Tensors
Oct 08, 2020


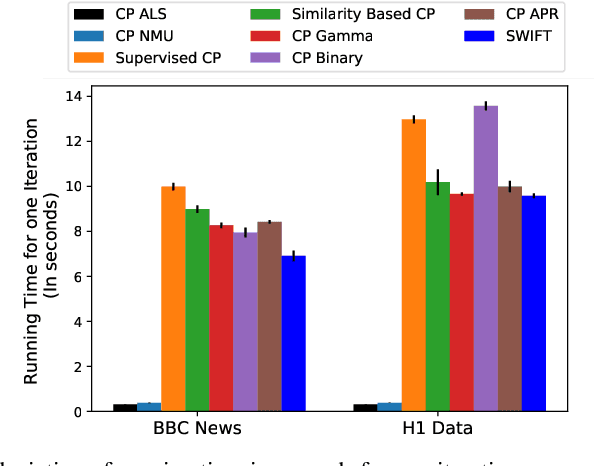
Existing tensor factorization methods assume that the input tensor follows some specific distribution (i.e. Poisson, Bernoulli and Gaussian), and solve the factorization by minimizing some empirical loss functions defined based on the corresponding distribution. However, it suffers from several drawbacks: 1) In reality, the underlying distributions are complicated and unknown, making it infeasible to be approximated by a simple distribution. 2) The correlation across dimensions of the input tensor is not well utilized, leading to sub-optimal performance. Although heuristics were proposed to incorporate such correlation as side information under Gaussian distribution, they can not easily be generalized to other distributions. Thus, a more principled way of utilizing the correlation in tensor factorization models is still an open challenge. Without assuming any explicit distribution, we formulate the tensor factorization as an optimal transport problem with Wasserstein distance, which can handle non-negative inputs. We introduce SWIFT, which minimizes the Wasserstein distance that measures the distance between the input tensor and that of the reconstruction. In particular, we define the N-th order tensor Wasserstein loss for the widely used tensor CP factorization, and derive the optimization algorithm that minimizes it. By leveraging sparsity structure and different equivalent formulations for optimizing computational efficiency, SWIFT is as scalable as other well-known CP algorithms. Using the factor matrices as features, SWIFT achieves up to 9.65% and 11.31% relative improvement over baselines for downstream prediction tasks. Under the noisy conditions, SWIFT achieves up to 15% and 17% relative improvements over the best competitors for the prediction tasks.
Clinical Concept Extraction for Document-Level Coding
Jun 08, 2019



The text of clinical notes can be a valuable source of patient information and clinical assessments. Historically, the primary approach for exploiting clinical notes has been information extraction: linking spans of text to concepts in a detailed domain ontology. However, recent work has demonstrated the potential of supervised machine learning to extract document-level codes directly from the raw text of clinical notes. We propose to bridge the gap between the two approaches with two novel syntheses: (1) treating extracted concepts as features, which are used to supplement or replace the text of the note; (2) treating extracted concepts as labels, which are used to learn a better representation of the text. Unfortunately, the resulting concepts do not yield performance gains on the document-level clinical coding task. We explore possible explanations and future research directions.