 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Gap between Understanding and Generation within Unified Multimodal Models
Feb 02, 2026Recent advances in unified multimodal models (UMM) have demonstrated remarkable progress in both understanding and generation tasks. However, whether these two capabilities are genuinely aligned and integrated within a single model remains unclear. To investigate this question, we introduce GapEval, a bidirectional benchmark designed to quantify the gap between understanding and generation capabilities, and quantitatively measure the cognitive coherence of the two "unified" directions. Each question can be answered in both modalities (image and text), enabling a symmetric evaluation of a model's bidirectional inference capability and cross-modal consistency. Experiments reveal a persistent gap between the two directions across a wide range of UMMs with different architectures, suggesting that current models achieve only surface-level unification rather than deep cognitive convergence of the two. To further explore the underlying mechanism, we conduct an empirical study from the perspective of knowledge manipulation to illustrate the underlying limitations. Our findings indicate that knowledge within UMMs often remains disjoint. The capability emergence and knowledge across modalities are unsynchronized, paving the way for further exploration.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
On Linear Representations and Pretraining Data Frequency in Language Models
Apr 16, 2025Pretraining data has a direct impact on the behaviors and quality of language models (LMs), but we only understand the most basic principles of this relationship. While most work focuses on pretraining data's effect on downstream task behavior, we investigate its relationship to LM representations. Previous work has discovered that, in language models, some concepts are encoded `linearly' in the representations, but what factors cause these representations to form? We study the connection between pretraining data frequency and models' linear representations of factual relations. We find evidence that the formation of linear representations is strongly connected to pretraining term frequencies; specifically for subject-relation-object fact triplets, both subject-object co-occurrence frequency and in-context learning accuracy for the relation are highly correlated with linear representations. This is the case across all phases of pretraining. In OLMo-7B and GPT-J, we discover that a linear representation consistently (but not exclusively) forms when the subjects and objects within a relation co-occur at least 1k and 2k times, respectively, regardless of when these occurrences happen during pretraining. Finally, we train a regression model on measurements of linear representation quality in fully-trained LMs that can predict how often a term was seen in pretraining. Our model achieves low error even on inputs from a different model with a different pretraining dataset, providing a new method for estimating properties of the otherwise-unknown training data of closed-data models. We conclude that the strength of linear representations in LMs contains signal about the models' pretraining corpora that may provide new avenues for controlling and improving model behavior: particularly, manipulating the models' training data to meet specific frequency thresholds.
Mechanistic?
Oct 07, 2024The rise of the term "mechanistic interpretability" has accompanied increasing interest in understanding neural models -- particularly language models. However, this jargon has also led to a fair amount of confusion. So, what does it mean to be "mechanistic"? We describe four uses of the term in interpretability research. The most narrow technical definition requires a claim of causality, while a broader technical definition allows for any exploration of a model's internals. However, the term also has a narrow cultural definition describing a cultural movement. To understand this semantic drift, we present a history of the NLP interpretability community and the formation of the separate, parallel "mechanistic" interpretability community. Finally, we discuss the broad cultural definition -- encompassing the entire field of interpretability -- and why the traditional NLP interpretability community has come to embrace it. We argue that the polysemy of "mechanistic" is the product of a critical divide within the interpretability community.
Plausibly Problematic Questions in Multiple-Choice Benchmarks for Commonsense Reasoning
Oct 06, 2024Questions involving commonsense reasoning about everyday situations often admit many $\textit{possible}$ or $\textit{plausible}$ answers. In contrast, multiple-choice question (MCQ) benchmarks for commonsense reasoning require a hard selection of a single correct answer, which, in principle, should represent the $\textit{most}$ plausible answer choice. On $250$ MCQ items sampled from two commonsense reasoning benchmarks, we collect $5,000$ independent plausibility judgments on answer choices. We find that for over 20% of the sampled MCQs, the answer choice rated most plausible does not match the benchmark gold answers; upon manual inspection, we confirm that this subset exhibits higher rates of problems like ambiguity or semantic mismatch between question and answer choices. Experiments with LLMs reveal low accuracy and high variation in performance on the subset, suggesting our plausibility criterion may be helpful in identifying more reliable benchmark items for commonsense evaluation.
Answer, Assemble, Ace: Understanding How Transformers Answer Multiple Choice Questions
Jul 21, 2024Multiple-choice question answering (MCQA) is a key competence of performant transformer language models that is tested by mainstream benchmarks. However, recent evidence shows that models can have quite a range of performance, particularly when the task format is diversified slightly (such as by shuffling answer choice order). In this work we ask: how do successful models perform formatted MCQA? We employ vocabulary projection and activation patching methods to localize key hidden states that encode relevant information for predicting the correct answer. We find that prediction of a specific answer symbol is causally attributed to a single middle layer, and specifically its multi-head self-attention mechanism. We show that subsequent layers increase the probability of the predicted answer symbol in vocabulary space, and that this probability increase is associated with a sparse set of attention heads with unique roles. We additionally uncover differences in how different models adjust to alternative symbols. Finally, we demonstrate that a synthetic task can disentangle sources of model error to pinpoint when a model has learned formatted MCQA, and show that an inability to separate answer symbol tokens in vocabulary space is a property of models unable to perform formatted MCQA tasks.
The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
Jan 12, 2024How can we train models to perform well on hard test data when hard training data is by definition difficult to label correctly? This question has been termed the scalable oversight problem and has drawn increasing attention as language models have continually improved. In this paper, we present the surprising conclusion that current language models often generalize relatively well from easy to hard data, even performing as well as "oracle" models trained on hard data. We demonstrate this kind of easy-to-hard generalization using simple training methods like in-context learning, linear classifier heads, and QLoRA for seven different measures of datapoint hardness, including six empirically diverse human hardness measures (like grade level) and one model-based measure (loss-based). Furthermore, we show that even if one cares most about model performance on hard data, it can be better to collect and train on easy data rather than hard data, since hard data is generally noisier and costlier to collect. Our experiments use open models up to 70b in size and four publicly available question-answering datasets with questions ranging in difficulty from 3rd grade science questions to college level STEM questions and general-knowledge trivia. We conclude that easy-to-hard generalization in LMs is surprisingly strong for the tasks studied, suggesting the scalable oversight problem may be easier than previously thought. Our code is available at https://github.com/allenai/easy-to-hard-generalization
Measuring and Improving Attentiveness to Partial Inputs with Counterfactuals
Nov 16, 2023The inevitable appearance of spurious correlations in training datasets hurts the generalization of NLP models on unseen data. Previous work has found that datasets with paired inputs are prone to correlations between a specific part of the input (e.g., the hypothesis in NLI) and the label; consequently, models trained only on those outperform chance. Are these correlations picked up by models trained on the full input data? To address this question, we propose a new evaluation method, Counterfactual Attentiveness Test (CAT). CAT uses counterfactuals by replacing part of the input with its counterpart from a different example (subject to some restrictions), expecting an attentive model to change its prediction. Using CAT, we systematically investigate established supervised and in-context learning models on ten datasets spanning four tasks: natural language inference, reading comprehension, paraphrase detection, and visual & language reasoning. CAT reveals that reliance on such correlations is mainly data-dependent. Surprisingly, we find that GPT3 becomes less attentive with an increased number of demonstrations, while its accuracy on the test data improves. Our results demonstrate that augmenting training or demonstration data with counterfactuals is effective in improving models' attentiveness. We show that models' attentiveness measured by CAT reveals different conclusions from solely measuring correlations in data.
Editing Commonsense Knowledge in GPT
May 24, 2023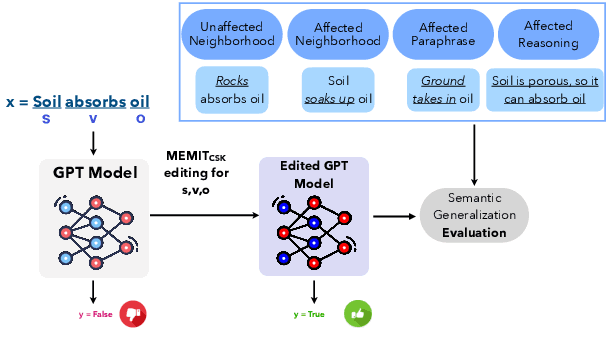
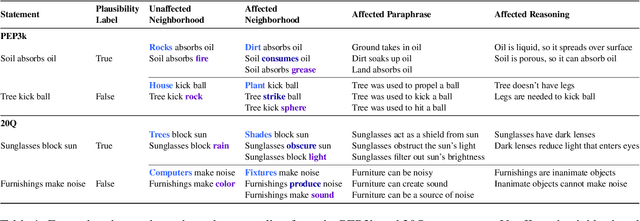
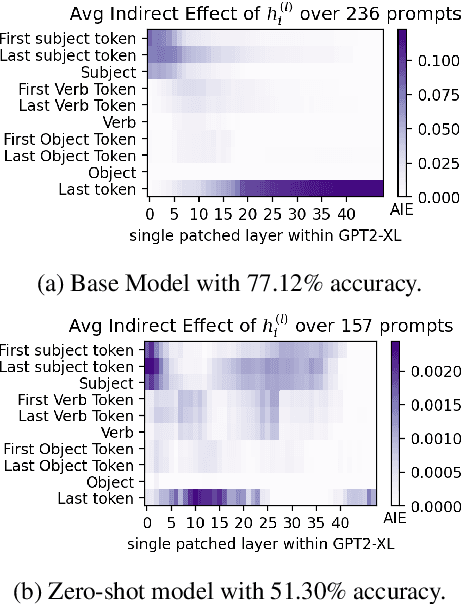
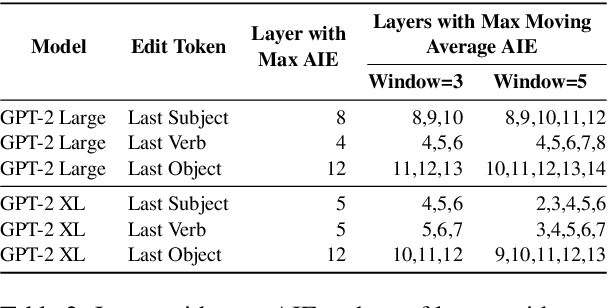
Memory editing methods for updating encyclopedic knowledge in transformers have received increasing attention for their efficacy, specificity, and generalization advantages. However, it remains unclear if such methods can be adapted for the more nuanced domain of commonsense knowledge. We propose $MEMIT_{CSK}$, an adaptation of MEMIT to edit commonsense mistakes in GPT-2 Large and XL. We extend editing to various token locations and employ a robust layer selection strategy. Models edited by $MEMIT_{CSK}$ outperforms the fine-tuning baselines by 10.97% and 10.73% F1 scores on subsets of PEP3k and 20Q. We further propose a novel evaluation dataset, MEMIT-CSK-PROBE, that contains unaffected neighborhood, affected neighborhood, affected paraphrase, and affected reasoning challenges. $MEMIT_{CSK}$ demonstrates favorable semantic generalization, outperforming fine-tuning baselines by 13.72% and 5.57% overall scores on MEMIT-CSK-PROBE. These results suggest a compelling future direction of incorporating context-specific user feedback concerning commonsense in GPT by direct model editing, rectifying and customizing model behaviors via human-in-the-loop systems.
Attentiveness to Answer Choices Doesn't Always Entail High QA Accuracy
May 24, 2023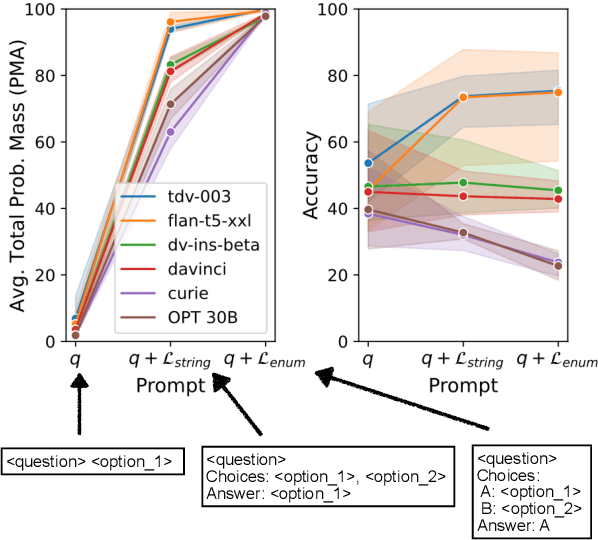



When large language models (LMs) are applied in zero- or few-shot settings to discriminative tasks such as multiple-choice questions, their attentiveness (i.e., probability mass) is spread across many vocabulary tokens that are not valid choices. Such a spread across multiple surface forms with identical meaning is thought to cause an underestimation of a model's true performance, referred to as the "surface form competition" (SFC) hypothesis. This has motivated the introduction of various probability normalization methods. However, many core questions remain unanswered. How do we measure SFC or attentiveness? Are there direct ways of increasing attentiveness on valid choices? Does increasing attentiveness always improve task accuracy? We propose a mathematical formalism for studying this phenomenon, provide a metric for quantifying attentiveness, and identify a simple method for increasing it -- namely, in-context learning with even just one example containing answer choices. The formalism allows us to quantify SFC and bound its impact. Our experiments on three diverse datasets and six LMs reveal several surprising findings. For example, encouraging models to generate a valid answer choice can, in fact, be detrimental to task performance for some LMs, and prior probability normalization methods are less effective (sometimes even detrimental) to instruction-tuned LMs. We conclude with practical insights for effectively using prompted LMs for multiple-choice tasks.