 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Performance Gap: Capability-Behavior Trade-offs in Feature Steering
Feb 03, 2026Feature steering has emerged as a promising approach for controlling LLM behavior through direct manipulation of internal representations, offering advantages over prompt engineering. However, its practical effectiveness in real-world applications remains poorly understood, particularly regarding potential trade-offs with output quality. We show that feature steering methods substantially degrade model performance even when successfully controlling target behaviors, a critical trade-off. Specifically, we evaluate Goodfire's Auto Steer against prompt engineering baselines across 14 steering queries (covering innocuous and safety-relevant behaviors) on 171 Massive Multitask Language Understanding (MMLU) questions using Llama-8B and Llama-70B, measuring accuracy, coherence, and behavioral control. Our findings show that Auto Steer successfully modifies target behaviors (achieving scores of 3.33 vs. 2.98 for prompting on Llama-8B and 3.57 vs. 3.10 on Llama-70B), but causes dramatic performance degradation: accuracy on the MMLU questions drops from 66% to 46% on Llama-8B and 87% to 73% on Llama-70B, with coherence falling from 4.62 to 2.24 and 4.94 to 3.89 respectively. Simple prompting achieves the best overall balance. These findings highlight limitations of current feature steering methods for practical deployment where task performance cannot be sacrificed. More broadly, our work demonstrates that mechanistic control methods face fundamental capability-behavior trade-offs that must be empirically characterized before deployment.
Measuring Chain-of-Thought Monitorability Through Faithfulness and Verbosity
Oct 31, 2025Chain-of-thought (CoT) outputs let us read a model's step-by-step reasoning. Since any long, serial reasoning process must pass through this textual trace, the quality of the CoT is a direct window into what the model is thinking. This visibility could help us spot unsafe or misaligned behavior (monitorability), but only if the CoT is transparent about its internal reasoning (faithfulness). Fully measuring faithfulness is difficult, so researchers often focus on examining the CoT in cases where the model changes its answer after adding a cue to the input. This proxy finds some instances of unfaithfulness but loses information when the model maintains its answer, and does not investigate aspects of reasoning not tied to the cue. We extend these results to a more holistic sense of monitorability by introducing verbosity: whether the CoT lists every factor needed to solve the task. We combine faithfulness and verbosity into a single monitorability score that shows how well the CoT serves as the model's external `working memory', a property that many safety schemes based on CoT monitoring depend on. We evaluate instruction-tuned and reasoning models on BBH, GPQA, and MMLU. Our results show that models can appear faithful yet remain hard to monitor when they leave out key factors, and that monitorability differs sharply across model families. We release our evaluation code using the Inspect library to support reproducible future work.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
Mar 13, 2025Chain-of-Thought (CoT) reasoning has significantly advanced state-of-the-art AI capabilities. However, recent studies have shown that CoT reasoning is not always faithful, i.e. CoT reasoning does not always reflect how models arrive at conclusions. So far, most of these studies have focused on unfaithfulness in unnatural contexts where an explicit bias has been introduced. In contrast, we show that unfaithful CoT can occur on realistic prompts with no artificial bias. Our results reveal non-negligible rates of several forms of unfaithful reasoning in frontier models: Sonnet 3.7 (16.3%), DeepSeek R1 (5.3%) and ChatGPT-4o (7.0%) all answer a notable proportion of question pairs unfaithfully. Specifically, we find that models rationalize their implicit biases in answers to binary questions ("implicit post-hoc rationalization"). For example, when separately presented with the questions "Is X bigger than Y?" and "Is Y bigger than X?", models sometimes produce superficially coherent arguments to justify answering Yes to both questions or No to both questions, despite such responses being logically contradictory. We also investigate restoration errors (Dziri et al., 2023), where models make and then silently correct errors in their reasoning, and unfaithful shortcuts, where models use clearly illogical reasoning to simplify solving problems in Putnam questions (a hard benchmark). Our findings raise challenges for AI safety work that relies on monitoring CoT to detect undesired behavior.
InterpBench: Semi-Synthetic Transformers for Evaluating Mechanistic Interpretability Techniques
Jul 19, 2024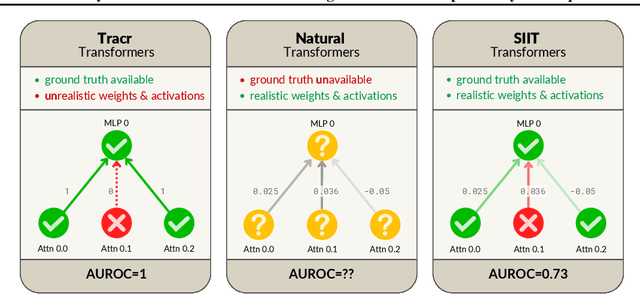
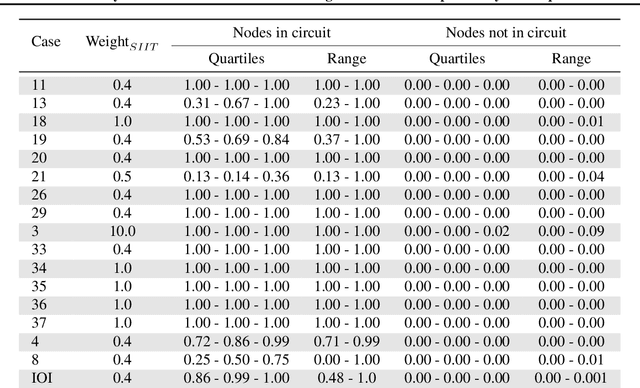
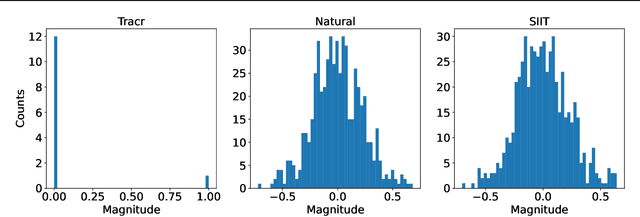
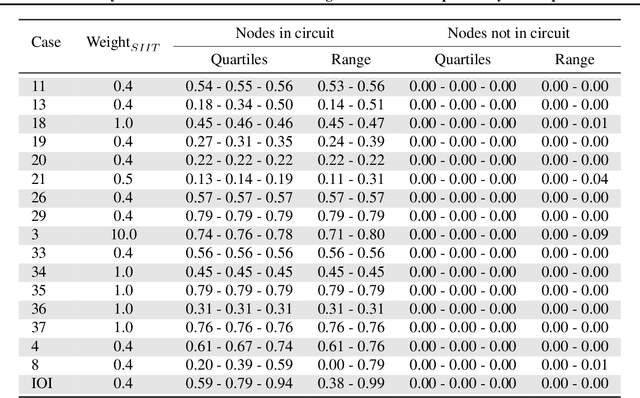
Mechanistic interpretability methods aim to identify the algorithm a neural network implements, but it is difficult to validate such methods when the true algorithm is unknown. This work presents InterpBench, a collection of semi-synthetic yet realistic transformers with known circuits for evaluating these techniques. We train these neural networks using a stricter version of Interchange Intervention Training (IIT) which we call Strict IIT (SIIT). Like the original, SIIT trains neural networks by aligning their internal computation with a desired high-level causal model, but it also prevents non-circuit nodes from affecting the model's output. We evaluate SIIT on sparse transformers produced by the Tracr tool and find that SIIT models maintain Tracr's original circuit while being more realistic. SIIT can also train transformers with larger circuits, like Indirect Object Identification (IOI). Finally, we use our benchmark to evaluate existing circuit discovery techniques.