 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-Obfuscation: Can Language Models Learn to Evade Latent-Space Monitors?
Jun 18, 2025Latent-space monitors aim to detect undesirable behaviours in large language models by leveraging internal model representations rather than relying solely on black-box outputs. These methods have shown promise in identifying behaviours such as deception and unsafe completions, but a critical open question remains: can LLMs learn to evade such monitors? To study this, we introduce RL-Obfuscation, in which LLMs are finetuned via reinforcement learning to bypass latent-space monitors while maintaining coherent generations. We apply RL-Obfuscation to LLMs ranging from 7B to 14B parameters and evaluate evasion success against a suite of monitors. We find that token-level latent-space monitors are highly vulnerable to this attack. More holistic monitors, such as max-pooling or attention-based probes, remain robust. Moreover, we show that adversarial policies trained to evade a single static monitor generalise to unseen monitors of the same type. Finally, we study how the policy learned by RL bypasses these monitors and find that the model can also learn to repurpose tokens to mean something different internally.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
FragmentNet: Adaptive Graph Fragmentation for Graph-to-Sequence Molecular Representation Learning
Feb 03, 2025



Molecular property prediction uses molecular structure to infer chemical properties. Chemically interpretable representations that capture meaningful intramolecular interactions enhance the usability and effectiveness of these predictions. However, existing methods often rely on atom-based or rule-based fragment tokenization, which can be chemically suboptimal and lack scalability. We introduce FragmentNet, a graph-to-sequence foundation model with an adaptive, learned tokenizer that decomposes molecular graphs into chemically valid fragments while preserving structural connectivity. FragmentNet integrates VQVAE-GCN for hierarchical fragment embeddings, spatial positional encodings for graph serialization, global molecular descriptors, and a transformer. Pre-trained with Masked Fragment Modeling and fine-tuned on MoleculeNet tasks, FragmentNet outperforms models with similarly scaled architectures and datasets while rivaling larger state-of-the-art models requiring significantly more resources. This novel framework enables adaptive decomposition, serialization, and reconstruction of molecular graphs, facilitating fragment-based editing and visualization of property trends in learned embeddings - a powerful tool for molecular design and optimization.
InterpBench: Semi-Synthetic Transformers for Evaluating Mechanistic Interpretability Techniques
Jul 19, 2024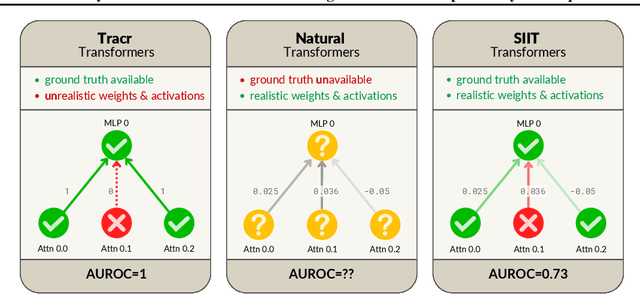
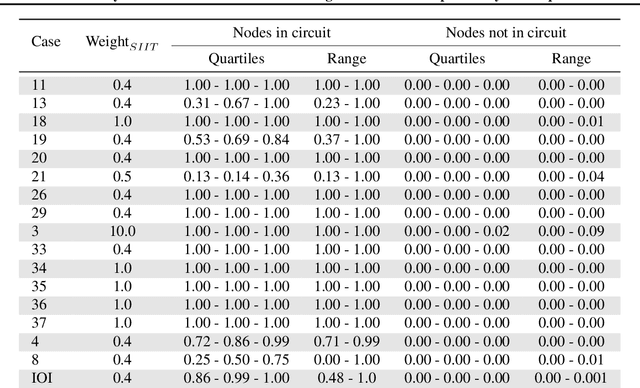
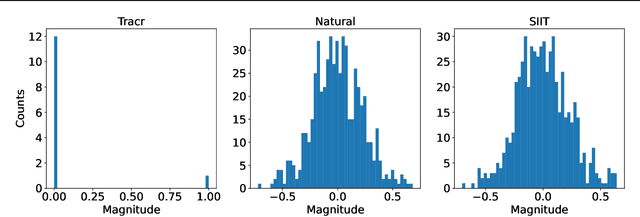
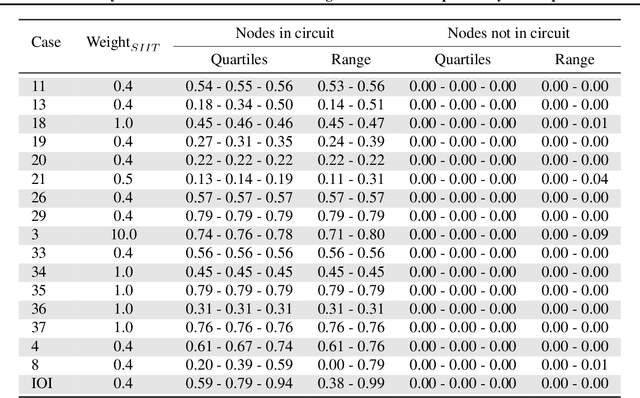
Mechanistic interpretability methods aim to identify the algorithm a neural network implements, but it is difficult to validate such methods when the true algorithm is unknown. This work presents InterpBench, a collection of semi-synthetic yet realistic transformers with known circuits for evaluating these techniques. We train these neural networks using a stricter version of Interchange Intervention Training (IIT) which we call Strict IIT (SIIT). Like the original, SIIT trains neural networks by aligning their internal computation with a desired high-level causal model, but it also prevents non-circuit nodes from affecting the model's output. We evaluate SIIT on sparse transformers produced by the Tracr tool and find that SIIT models maintain Tracr's original circuit while being more realistic. SIIT can also train transformers with larger circuits, like Indirect Object Identification (IOI). Finally, we use our benchmark to evaluate existing circuit discovery techniques.
Contrast Sets for Evaluating Language-Guided Robot Policies
Jun 19, 2024
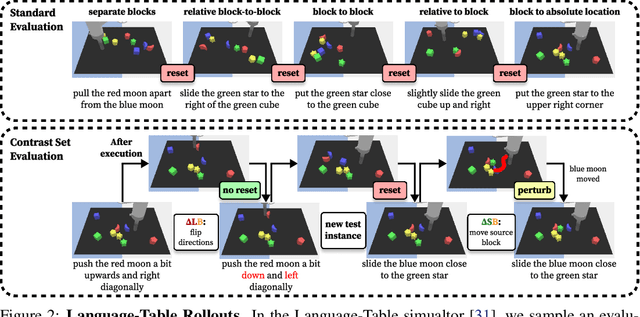
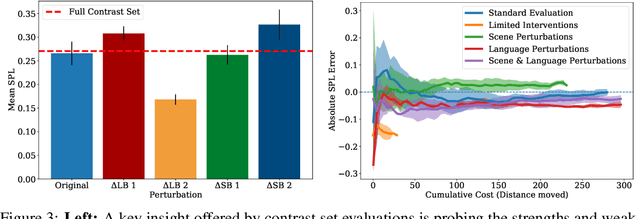

Robot evaluations in language-guided, real world settings are time-consuming and often sample only a small space of potential instructions across complex scenes. In this work, we introduce contrast sets for robotics as an approach to make small, but specific, perturbations to otherwise independent, identically distributed (i.i.d.) test instances. We investigate the relationship between experimenter effort to carry out an evaluation and the resulting estimated test performance as well as the insights that can be drawn from performance on perturbed instances. We use contrast sets to characterize policies at reduced experimenter effort in both a simulated manipulation task and a physical robot vision-and-language navigation task. We encourage the use of contrast set evaluations as a more informative alternative to small scale, i.i.d. demonstrations on physical robots, and as a scalable alternative to industry-scale real world evaluations.
Augmenting End-to-End Steering Angle Prediction with CAN Bus Data
Oct 22, 2023



In recent years, end to end steering prediction for autonomous vehicles has become a major area of research. The primary method for achieving end to end steering was to use computer vision models on a live feed of video data. However, to further increase accuracy, many companies have added data from light detection and ranging (LiDAR) and or radar sensors through sensor fusion. However, the addition of lasers and sensors comes at a high financial cost. In this paper, I address both of these issues by increasing the accuracy of the computer vision models without the increased cost of using LiDAR and or sensors. I achieved this by improving the accuracy of computer vision models by sensor fusing CAN bus data, a vehicle protocol, with video data. CAN bus data is a rich source of information about the vehicle's state, including its speed, steering angle, and acceleration. By fusing this data with video data, the accuracy of the computer vision model's predictions can be improved. When I trained the model without CAN bus data, I obtained an RMSE of 0.02492, while the model trained with the CAN bus data achieved an RMSE of 0.01970. This finding indicates that fusing CAN Bus data with video data can reduce the computer vision model's prediction error by 20% with some models decreasing the error by 80%.
Optical Script Identification for multi-lingual Indic-script
Aug 10, 2023Script identification and text recognition are some of the major domains in the application of Artificial Intelligence. In this era of digitalization, the use of digital note-taking has become a common practice. Still, conventional methods of using pen and paper is a prominent way of writing. This leads to the classification of scripts based on the method they are obtained. A survey on the current methodologies and state-of-art methods used for processing and identification would prove beneficial for researchers. The aim of this article is to discuss the advancement in the techniques for script pre-processing and text recognition. In India there are twelve prominent Indic scripts, unlike the English language, these scripts have layers of characteristics. Complex characteristics such as similarity in text shape make them difficult to recognize and analyze, thus this requires advance preprocessing methods for their accurate recognition. A sincere attempt is made in this survey to provide a comparison between all algorithms. We hope that this survey would provide insight to a researcher working not only on Indic scripts but also other languages.
WASSA@IITK at WASSA 2021: Multi-task Learning and Transformer Finetuning for Emotion Classification and Empathy Prediction
Apr 20, 2021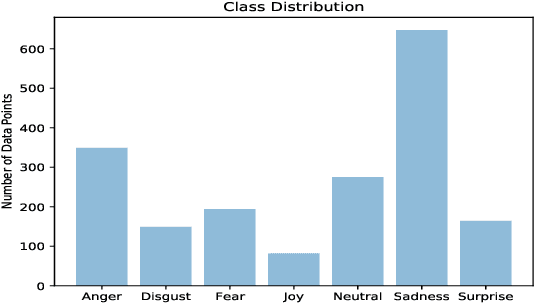
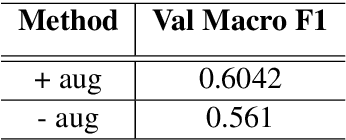
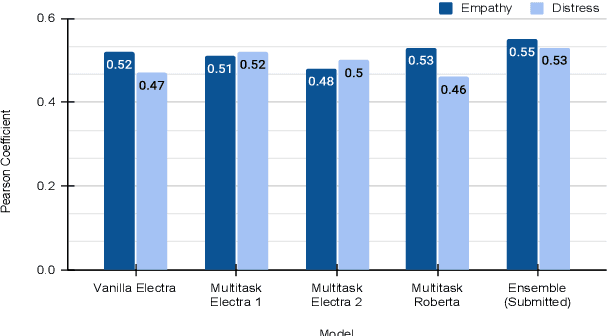
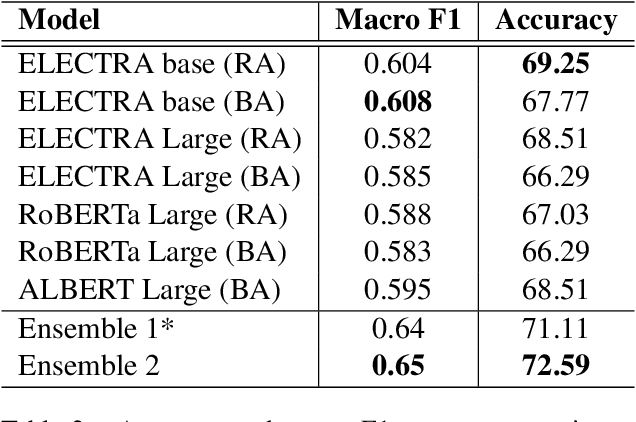
This paper describes our contribution to the WASSA 2021 shared task on Empathy Prediction and Emotion Classification. The broad goal of this task was to model an empathy score, a distress score and the overall level of emotion of an essay written in response to a newspaper article associated with harm to someone. We have used the ELECTRA model abundantly and also advanced deep learning approaches like multi-task learning. Additionally, we also leveraged standard machine learning techniques like ensembling. Our system achieves a Pearson Correlation Coefficient of 0.533 on sub-task I and a macro F1 score of 0.5528 on sub-task II. We ranked 1st in Emotion Classification sub-task and 3rd in Empathy Prediction sub-task
MCL@IITK at SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation using Augmented Data, Signals, and Transformers
Apr 04, 2021

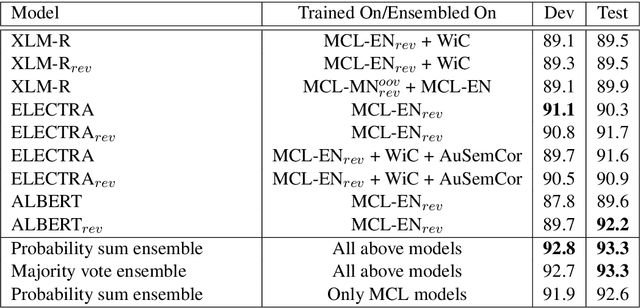

In this work, we present our approach for solving the SemEval 2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC). The task is a sentence pair classification problem where the goal is to detect whether a given word common to both the sentences evokes the same meaning. We submit systems for both the settings - Multilingual (the pair's sentences belong to the same language) and Cross-Lingual (the pair's sentences belong to different languages). The training data is provided only in English. Consequently, we employ cross-lingual transfer techniques. Our approach employs fine-tuning pre-trained transformer-based language models, like ELECTRA and ALBERT, for the English task and XLM-R for all other tasks. To improve these systems' performance, we propose adding a signal to the word to be disambiguated and augmenting our data by sentence pair reversal. We further augment the dataset provided to us with WiC, XL-WiC and SemCor 3.0. Using ensembles, we achieve strong performance in the Multilingual task, placing first in the EN-EN and FR-FR sub-tasks. For the Cross-Lingual setting, we employed translate-test methods and a zero-shot method, using our multilingual models, with the latter performing slightly better.