 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
HCAST: Human-Calibrated Autonomy Software Tasks
Mar 21, 2025To understand and predict the societal impacts of highly autonomous AI systems, we need benchmarks with grounding, i.e., metrics that directly connect AI performance to real-world effects we care about. We present HCAST (Human-Calibrated Autonomy Software Tasks), a benchmark of 189 machine learning engineering, cybersecurity, software engineering, and general reasoning tasks. We collect 563 human baselines (totaling over 1500 hours) from people skilled in these domains, working under identical conditions as AI agents, which lets us estimate that HCAST tasks take humans between one minute and 8+ hours. Measuring the time tasks take for humans provides an intuitive metric for evaluating AI capabilities, helping answer the question "can an agent be trusted to complete a task that would take a human X hours?" We evaluate the success rates of AI agents built on frontier foundation models, and we find that current agents succeed 70-80% of the time on tasks that take humans less than one hour, and less than 20% of the time on tasks that take humans more than 4 hours.
Measuring AI Ability to Complete Long Tasks
Mar 18, 2025Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
InterpBench: Semi-Synthetic Transformers for Evaluating Mechanistic Interpretability Techniques
Jul 19, 2024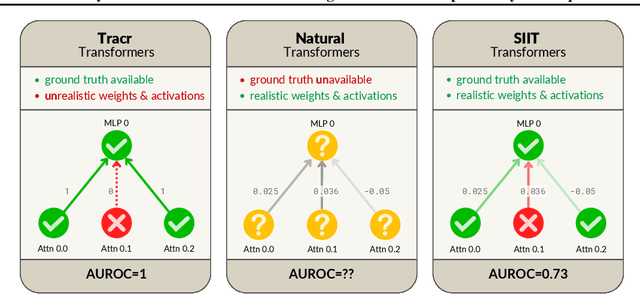
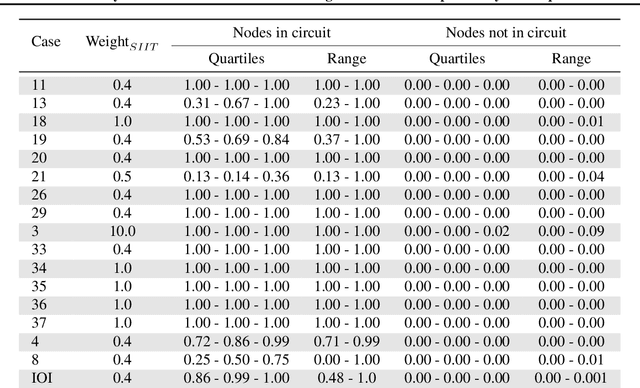
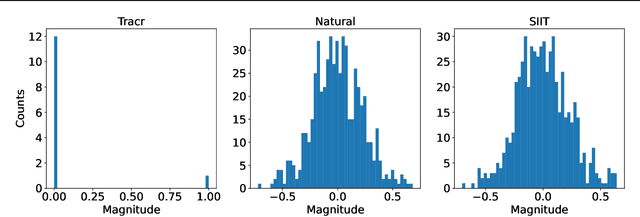
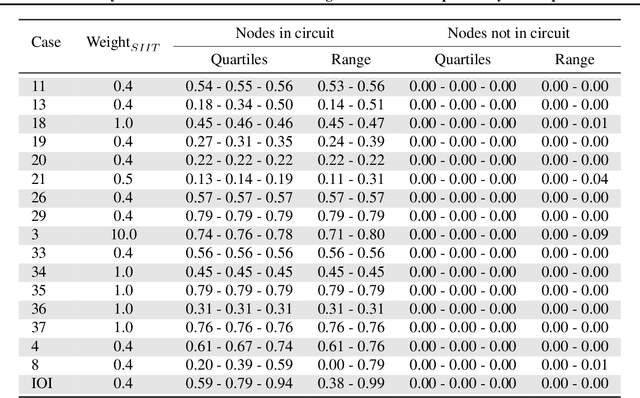
Mechanistic interpretability methods aim to identify the algorithm a neural network implements, but it is difficult to validate such methods when the true algorithm is unknown. This work presents InterpBench, a collection of semi-synthetic yet realistic transformers with known circuits for evaluating these techniques. We train these neural networks using a stricter version of Interchange Intervention Training (IIT) which we call Strict IIT (SIIT). Like the original, SIIT trains neural networks by aligning their internal computation with a desired high-level causal model, but it also prevents non-circuit nodes from affecting the model's output. We evaluate SIIT on sparse transformers produced by the Tracr tool and find that SIIT models maintain Tracr's original circuit while being more realistic. SIIT can also train transformers with larger circuits, like Indirect Object Identification (IOI). Finally, we use our benchmark to evaluate existing circuit discovery techniques.
Catastrophic Goodhart: regularizing RLHF with KL divergence does not mitigate heavy-tailed reward misspecification
Jul 19, 2024When applying reinforcement learning from human feedback (RLHF), the reward is learned from data and, therefore, always has some error. It is common to mitigate this by regularizing the policy with KL divergence from a base model, with the hope that balancing reward with regularization will achieve desirable outcomes despite this reward misspecification. We show that when the reward function has light-tailed error, optimal policies under less restrictive KL penalties achieve arbitrarily high utility. However, if error is heavy-tailed, some policies obtain arbitrarily high reward despite achieving no more utility than the base model--a phenomenon we call catastrophic Goodhart. We adapt a discrete optimization method to measure the tails of reward models, finding that they are consistent with light-tailed error. However, the pervasiveness of heavy-tailed distributions in many real-world applications indicates that future sources of RL reward could have heavy-tailed error, increasing the likelihood of reward hacking even with KL regularization.
Compact Proofs of Model Performance via Mechanistic Interpretability
Jun 24, 2024



In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Provable Guarantees for Model Performance via Mechanistic Interpretability
Jun 18, 2024In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.