 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCAST: Human-Calibrated Autonomy Software Tasks
Mar 21, 2025To understand and predict the societal impacts of highly autonomous AI systems, we need benchmarks with grounding, i.e., metrics that directly connect AI performance to real-world effects we care about. We present HCAST (Human-Calibrated Autonomy Software Tasks), a benchmark of 189 machine learning engineering, cybersecurity, software engineering, and general reasoning tasks. We collect 563 human baselines (totaling over 1500 hours) from people skilled in these domains, working under identical conditions as AI agents, which lets us estimate that HCAST tasks take humans between one minute and 8+ hours. Measuring the time tasks take for humans provides an intuitive metric for evaluating AI capabilities, helping answer the question "can an agent be trusted to complete a task that would take a human X hours?" We evaluate the success rates of AI agents built on frontier foundation models, and we find that current agents succeed 70-80% of the time on tasks that take humans less than one hour, and less than 20% of the time on tasks that take humans more than 4 hours.
Measuring AI Ability to Complete Long Tasks
Mar 18, 2025Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
Training Language Models to Win Debates with Self-Play Improves Judge Accuracy
Sep 25, 2024



We test the robustness of debate as a method of scalable oversight by training models to debate with data generated via self-play. In a long-context reading comprehension task, we find that language model based evaluators answer questions more accurately when judging models optimized to win debates. By contrast, we find no such relationship for consultancy models trained to persuade a judge without an opposing debater present. In quantitative and qualitative comparisons between our debate models and novel consultancy baselines, we find evidence that debate training encourages stronger and more informative arguments, showing promise that it can help provide high-quality supervision for tasks that are difficult to directly evaluate.
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Nov 20, 2023



We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are "Google-proof"). The questions are also difficult for state-of-the-art AI systems, with our strongest GPT-4 based baseline achieving 39% accuracy. If we are to use future AI systems to help us answer very hard questions, for example, when developing new scientific knowledge, we need to develop scalable oversight methods that enable humans to supervise their outputs, which may be difficult even if the supervisors are themselves skilled and knowledgeable. The difficulty of GPQA both for skilled non-experts and frontier AI systems should enable realistic scalable oversight experiments, which we hope can help devise ways for human experts to reliably get truthful information from AI systems that surpass human capabilities.
Debate Helps Supervise Unreliable Experts
Nov 15, 2023As AI systems are used to answer more difficult questions and potentially help create new knowledge, judging the truthfulness of their outputs becomes more difficult and more important. How can we supervise unreliable experts, which have access to the truth but may not accurately report it, to give answers that are systematically true and don't just superficially seem true, when the supervisor can't tell the difference between the two on their own? In this work, we show that debate between two unreliable experts can help a non-expert judge more reliably identify the truth. We collect a dataset of human-written debates on hard reading comprehension questions where the judge has not read the source passage, only ever seeing expert arguments and short quotes selectively revealed by 'expert' debaters who have access to the passage. In our debates, one expert argues for the correct answer, and the other for an incorrect answer. Comparing debate to a baseline we call consultancy, where a single expert argues for only one answer which is correct half of the time, we find that debate performs significantly better, with 84% judge accuracy compared to consultancy's 74%. Debates are also more efficient, being 68% of the length of consultancies. By comparing human to AI debaters, we find evidence that with more skilled (in this case, human) debaters, the performance of debate goes up but the performance of consultancy goes down. Our error analysis also supports this trend, with 46% of errors in human debate attributable to mistakes by the honest debater (which should go away with increased skill); whereas 52% of errors in human consultancy are due to debaters obfuscating the relevant evidence from the judge (which should become worse with increased skill). Overall, these results show that debate is a promising approach for supervising increasingly capable but potentially unreliable AI systems.
Classification with Strategically Withheld Data
Jan 14, 2021
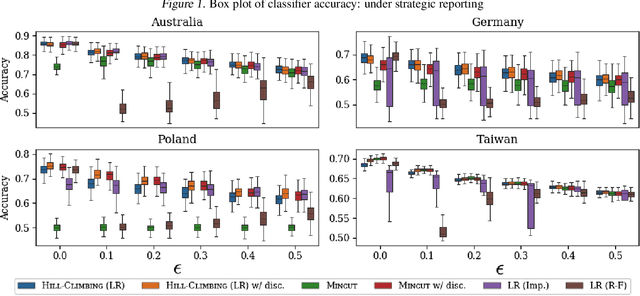

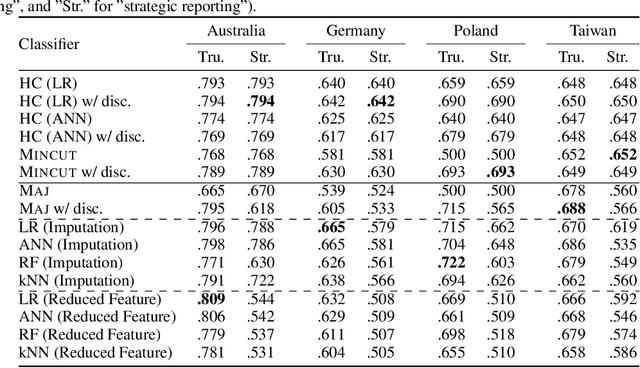
Machine learning techniques can be useful in applications such as credit approval and college admission. However, to be classified more favorably in such contexts, an agent may decide to strategically withhold some of her features, such as bad test scores. This is a missing data problem with a twist: which data is missing {\em depends on the chosen classifier}, because the specific classifier is what may create the incentive to withhold certain feature values. We address the problem of training classifiers that are robust to this behavior. We design three classification methods: {\sc Mincut}, {\sc Hill-Climbing} ({\sc HC}) and Incentive-Compatible Logistic Regression ({\sc IC-LR}). We show that {\sc Mincut} is optimal when the true distribution of data is fully known. However, it can produce complex decision boundaries, and hence be prone to overfitting in some cases. Based on a characterization of truthful classifiers (i.e., those that give no incentive to strategically hide features), we devise a simpler alternative called {\sc HC} which consists of a hierarchical ensemble of out-of-the-box classifiers, trained using a specialized hill-climbing procedure which we show to be convergent. For several reasons, {\sc Mincut} and {\sc HC} are not effective in utilizing a large number of complementarily informative features. To this end, we present {\sc IC-LR}, a modification of Logistic Regression that removes the incentive to strategically drop features. We also show that our algorithms perform well in experiments on real-world data sets, and present insights into their relative performance in different settings.