 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification with Strategically Withheld Data
Jan 14, 2021
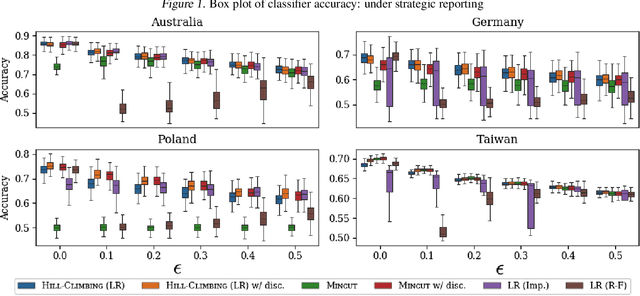

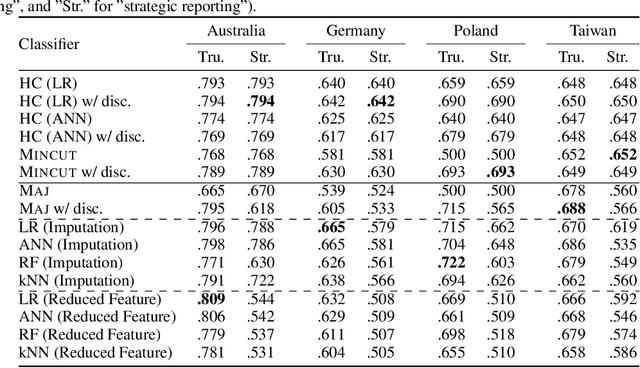
Machine learning techniques can be useful in applications such as credit approval and college admission. However, to be classified more favorably in such contexts, an agent may decide to strategically withhold some of her features, such as bad test scores. This is a missing data problem with a twist: which data is missing {\em depends on the chosen classifier}, because the specific classifier is what may create the incentive to withhold certain feature values. We address the problem of training classifiers that are robust to this behavior. We design three classification methods: {\sc Mincut}, {\sc Hill-Climbing} ({\sc HC}) and Incentive-Compatible Logistic Regression ({\sc IC-LR}). We show that {\sc Mincut} is optimal when the true distribution of data is fully known. However, it can produce complex decision boundaries, and hence be prone to overfitting in some cases. Based on a characterization of truthful classifiers (i.e., those that give no incentive to strategically hide features), we devise a simpler alternative called {\sc HC} which consists of a hierarchical ensemble of out-of-the-box classifiers, trained using a specialized hill-climbing procedure which we show to be convergent. For several reasons, {\sc Mincut} and {\sc HC} are not effective in utilizing a large number of complementarily informative features. To this end, we present {\sc IC-LR}, a modification of Logistic Regression that removes the incentive to strategically drop features. We also show that our algorithms perform well in experiments on real-world data sets, and present insights into their relative performance in different settings.
Fair for All: Best-effort Fairness Guarantees for Classification
Jan 08, 2021
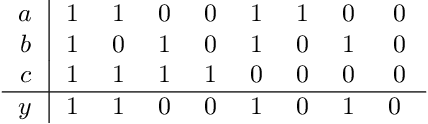
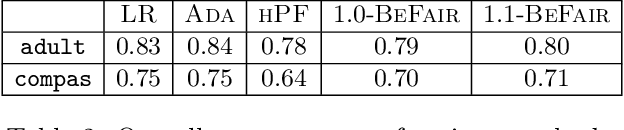

Standard approaches to group-based notions of fairness, such as \emph{parity} and \emph{equalized odds}, try to equalize absolute measures of performance across known groups (based on race, gender, etc.). Consequently, a group that is inherently harder to classify may hold back the performance on other groups; and no guarantees can be provided for unforeseen groups. Instead, we propose a fairness notion whose guarantee, on each group $g$ in a class $\mathcal{G}$, is relative to the performance of the best classifier on $g$. We apply this notion to broad classes of groups, in particular, where (a) $\mathcal{G}$ consists of all possible groups (subsets) in the data, and (b) $\mathcal{G}$ is more streamlined. For the first setting, which is akin to groups being completely unknown, we devise the {\sc PF} (Proportional Fairness) classifier, which guarantees, on any possible group $g$, an accuracy that is proportional to that of the optimal classifier for $g$, scaled by the relative size of $g$ in the data set. Due to including all possible groups, some of which could be too complex to be relevant, the worst-case theoretical guarantees here have to be proportionally weaker for smaller subsets. For the second setting, we devise the {\sc BeFair} (Best-effort Fair) framework which seeks an accuracy, on every $g \in \mathcal{G}$, which approximates that of the optimal classifier on $g$, independent of the size of $g$. Aiming for such a guarantee results in a non-convex problem, and we design novel techniques to get around this difficulty when $\mathcal{G}$ is the set of linear hypotheses. We test our algorithms on real-world data sets, and present interesting comparative insights on their performance.
Exploration vs. Exploitation in Team Formation
Oct 12, 2018
An online labor platform faces an online learning problem in matching workers with jobs and using the performance on these jobs to create better future matches. This learning problem is complicated by the rise of complex tasks on these platforms, such as web development and product design, that require a team of workers to complete. The success of a job is now a function of the skills and contributions of all workers involved, which may be unknown to both the platform and the client who posted the job. These team matchings result in a structured correlation between what is known about the individuals and this information can be utilized to create better future matches. We analyze two natural settings where the performance of a team is dictated by its strongest and its weakest member, respectively. We find that both problems pose an exploration-exploitation tradeoff between learning the performance of untested teams and repeating previously tested teams that resulted in a good performance. We establish fundamental regret bounds and design near-optimal algorithms that uncover several insights into these tradeoffs.