 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompact Conformal Subgraphs
Feb 07, 2026Conformal prediction provides rigorous, distribution-free uncertainty guarantees, but often yields prohibitively large prediction sets in structured domains such as routing, planning, or sequential recommendation. We introduce "graph-based conformal compression", a framework for constructing compact subgraphs that preserve statistical validity while reducing structural complexity. We formulate compression as selecting a smallest subgraph capturing a prescribed fraction of the probability mass, and reduce to a weighted version of densest $k$-subgraphs in hypergraphs, in the regime where the subgraph has a large fraction of edges. We design efficient approximation algorithms that achieve constant factor coverage and size trade-offs. Crucially, we prove that our relaxation satisfies a monotonicity property, derived from a connection to parametric minimum cuts, which guarantees the nestedness required for valid conformal guarantees. Our results on the one hand bridge efficient conformal prediction with combinatorial graph compression via monotonicity, to provide rigorous guarantees on both statistical validity, and compression or size. On the other hand, they also highlight an algorithmic regime, distinct from classical densest-$k$-subgraph hardness settings, where the problem can be approximated efficiently. We finally validate our algorithmic approach via simulations for trip planning and navigation, and compare to natural baselines.
Multi-Selection for Recommendation Systems
Apr 10, 2025We present the construction of a multi-selection model to answer differentially private queries in the context of recommendation systems. The server sends back multiple recommendations and a ``local model'' to the user, which the user can run locally on its device to select the item that best fits its private features. We study a setup where the server uses a deep neural network (trained on the Movielens 25M dataset as the ground truth for movie recommendation. In the multi-selection paradigm, the average recommendation utility is approximately 97\% of the optimal utility (as determined by the ground truth neural network) while maintaining a local differential privacy guarantee with $\epsilon$ ranging around 1 with respect to feature vectors of neighboring users. This is in comparison to an average recommendation utility of 91\% in the non-multi-selection regime under the same constraints.
Combinatorial Optimization via LLM-driven Iterated Fine-tuning
Mar 10, 2025



We present a novel way to integrate flexible, context-dependent constraints into combinatorial optimization by leveraging Large Language Models (LLMs) alongside traditional algorithms. Although LLMs excel at interpreting nuanced, locally specified requirements, they struggle with enforcing global combinatorial feasibility. To bridge this gap, we propose an iterated fine-tuning framework where algorithmic feedback progressively refines the LLM's output distribution. Interpreting this as simulated annealing, we introduce a formal model based on a "coarse learnability" assumption, providing sample complexity bounds for convergence. Empirical evaluations on scheduling, graph connectivity, and clustering tasks demonstrate that our framework balances the flexibility of locally expressed constraints with rigorous global optimization more effectively compared to baseline sampling methods. Our results highlight a promising direction for hybrid AI-driven combinatorial reasoning.
Classification with Partially Private Features
Dec 11, 2023
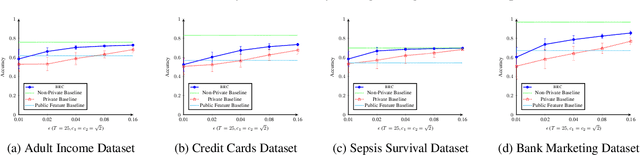
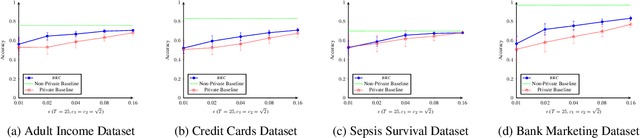
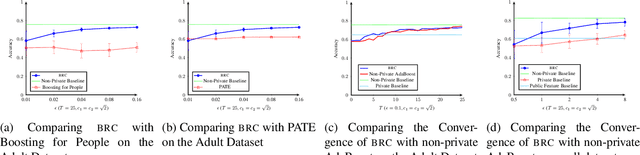
In this paper, we consider differentially private classification when some features are sensitive, while the rest of the features and the label are not. We adapt the definition of differential privacy naturally to this setting. Our main contribution is a novel adaptation of AdaBoost that is not only provably differentially private, but also significantly outperforms a natural benchmark that assumes the entire data of the individual is sensitive in the experiments. As a surprising observation, we show that boosting randomly generated classifiers suffices to achieve high accuracy. Our approach easily adapts to the classical setting where all the features are sensitive, providing an alternate algorithm for differentially private linear classification with a much simpler privacy proof and comparable or higher accuracy than differentially private logistic regression on real-world datasets.
Online Learning and Bandits with Queried Hints
Nov 04, 2022We consider the classic online learning and stochastic multi-armed bandit (MAB) problems, when at each step, the online policy can probe and find out which of a small number ($k$) of choices has better reward (or loss) before making its choice. In this model, we derive algorithms whose regret bounds have exponentially better dependence on the time horizon compared to the classic regret bounds. In particular, we show that probing with $k=2$ suffices to achieve time-independent regret bounds for online linear and convex optimization. The same number of probes improve the regret bound of stochastic MAB with independent arms from $O(\sqrt{nT})$ to $O(n^2 \log T)$, where $n$ is the number of arms and $T$ is the horizon length. For stochastic MAB, we also consider a stronger model where a probe reveals the reward values of the probed arms, and show that in this case, $k=3$ probes suffice to achieve parameter-independent constant regret, $O(n^2)$. Such regret bounds cannot be achieved even with full feedback after the play, showcasing the power of limited ``advice'' via probing before making the play. We also present extensions to the setting where the hints can be imperfect, and to the case of stochastic MAB where the rewards of the arms can be correlated.
Robust Allocations with Diversity Constraints
Sep 30, 2021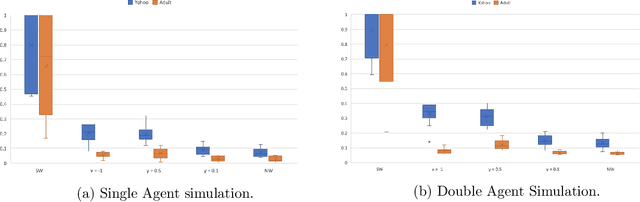
We consider the problem of allocating divisible items among multiple agents, and consider the setting where any agent is allowed to introduce diversity constraints on the items they are allocated. We motivate this via settings where the items themselves correspond to user ad slots or task workers with attributes such as race and gender on which the principal seeks to achieve demographic parity. We consider the following question: When an agent expresses diversity constraints into an allocation rule, is the allocation of other agents hurt significantly? If this happens, the cost of introducing such constraints is disproportionately borne by agents who do not benefit from diversity. We codify this via two desiderata capturing robustness. These are no negative externality -- other agents are not hurt -- and monotonicity -- the agent enforcing the constraint does not see a large increase in value. We show in a formal sense that the Nash Welfare rule that maximizes product of agent values is uniquely positioned to be robust when diversity constraints are introduced, while almost all other natural allocation rules fail this criterion. We also show that the guarantees achieved by Nash Welfare are nearly optimal within a widely studied class of allocation rules. We finally perform an empirical simulation on real-world data that models ad allocations to show that this gap between Nash Welfare and other rules persists in the wild.
Fair for All: Best-effort Fairness Guarantees for Classification
Jan 08, 2021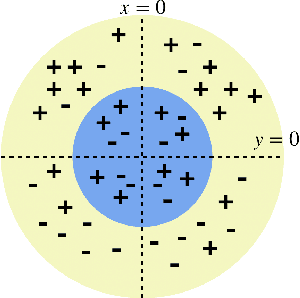
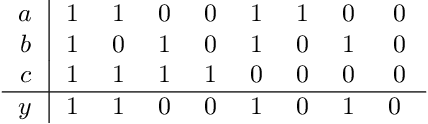
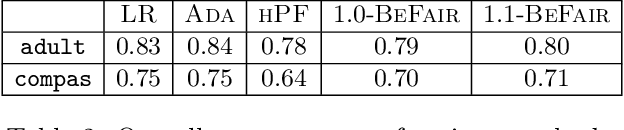

Standard approaches to group-based notions of fairness, such as \emph{parity} and \emph{equalized odds}, try to equalize absolute measures of performance across known groups (based on race, gender, etc.). Consequently, a group that is inherently harder to classify may hold back the performance on other groups; and no guarantees can be provided for unforeseen groups. Instead, we propose a fairness notion whose guarantee, on each group $g$ in a class $\mathcal{G}$, is relative to the performance of the best classifier on $g$. We apply this notion to broad classes of groups, in particular, where (a) $\mathcal{G}$ consists of all possible groups (subsets) in the data, and (b) $\mathcal{G}$ is more streamlined. For the first setting, which is akin to groups being completely unknown, we devise the {\sc PF} (Proportional Fairness) classifier, which guarantees, on any possible group $g$, an accuracy that is proportional to that of the optimal classifier for $g$, scaled by the relative size of $g$ in the data set. Due to including all possible groups, some of which could be too complex to be relevant, the worst-case theoretical guarantees here have to be proportionally weaker for smaller subsets. For the second setting, we devise the {\sc BeFair} (Best-effort Fair) framework which seeks an accuracy, on every $g \in \mathcal{G}$, which approximates that of the optimal classifier on $g$, independent of the size of $g$. Aiming for such a guarantee results in a non-convex problem, and we design novel techniques to get around this difficulty when $\mathcal{G}$ is the set of linear hypotheses. We test our algorithms on real-world data sets, and present interesting comparative insights on their performance.
Proportionally Fair Clustering
May 10, 2019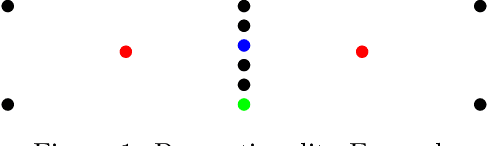
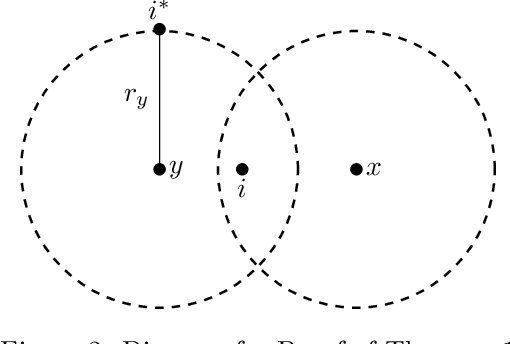

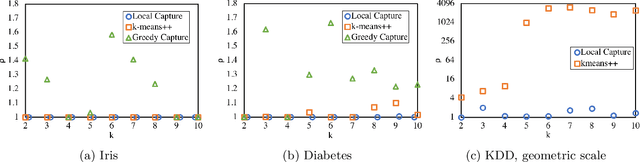
We extend the fair machine learning literature by considering the problem of proportional centroid clustering in a metric context. For clustering $n$ points with $k$ centers, we define fairness as proportionality to mean that any $n/k$ points are entitled to form their own cluster if there is another center that is closer in distance for all $n/k$ points. We seek clustering solutions to which there are no such justified complaints from any subsets of agents, without assuming any a priori notion of protected subsets. We present and analyze algorithms to efficiently compute, optimize, and audit proportional solutions. We conclude with an empirical examination of the tradeoff between proportional solutions and the $k$-means objective.
Random Dictators with a Random Referee: Constant Sample Complexity Mechanisms for Social Choice
Nov 13, 2018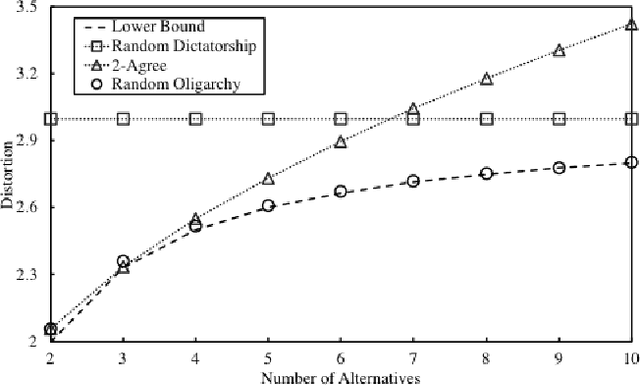
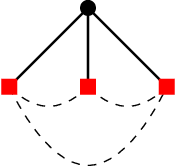
We study social choice mechanisms in an implicit utilitarian framework with a metric constraint, where the goal is to minimize \textit{Distortion}, the worst case social cost of an ordinal mechanism relative to underlying cardinal utilities. We consider two additional desiderata: Constant sample complexity and Squared Distortion. Constant sample complexity means that the mechanism (potentially randomized) only uses a constant number of ordinal queries regardless of the number of voters and alternatives. Squared Distortion is a measure of variance of the Distortion of a randomized mechanism. Our primary contribution is the first social choice mechanism with constant sample complexity \textit{and} constant Squared Distortion (which also implies constant Distortion). We call the mechanism Random Referee, because it uses a random agent to compare two alternatives that are the favorites of two other random agents. We prove that the use of a comparison query is necessary: no mechanism that only elicits the top-k preferred alternatives of voters (for constant k) can have Squared Distortion that is sublinear in the number of alternatives. We also prove that unlike any top-k only mechanism, the Distortion of Random Referee meaningfully improves on benign metric spaces, using the Euclidean plane as a canonical example. Finally, among top-1 only mechanisms, we introduce Random Oligarchy. The mechanism asks just 3 queries and is essentially optimal among the class of such mechanisms with respect to Distortion. In summary, we demonstrate the surprising power of constant sample complexity mechanisms generally, and just three random voters in particular, to provide some of the best known results in the implicit utilitarian framework.
Approximation Algorithms for Bayesian Multi-Armed Bandit Problems
Jul 17, 2013
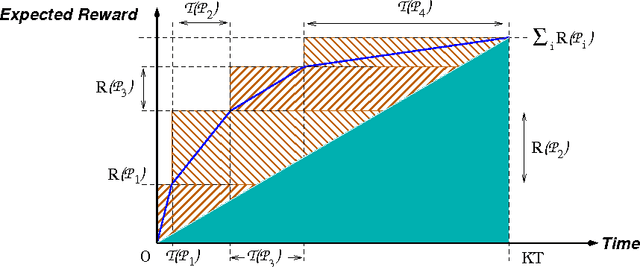
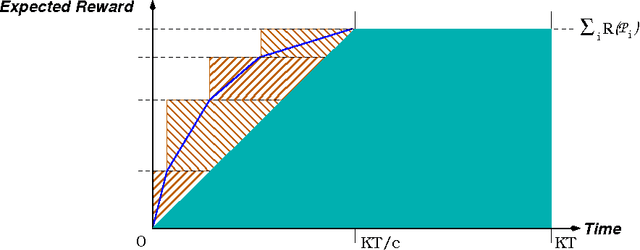

In this paper, we consider several finite-horizon Bayesian multi-armed bandit problems with side constraints which are computationally intractable (NP-Hard) and for which no optimal (or near optimal) algorithms are known to exist with sub-exponential running time. All of these problems violate the standard exchange property, which assumes that the reward from the play of an arm is not contingent upon when the arm is played. Not only are index policies suboptimal in these contexts, there has been little analysis of such policies in these problem settings. We show that if we consider near-optimal policies, in the sense of approximation algorithms, then there exists (near) index policies. Conceptually, if we can find policies that satisfy an approximate version of the exchange property, namely, that the reward from the play of an arm depends on when the arm is played to within a constant factor, then we have an avenue towards solving these problems. However such an approximate version of the idling bandit property does not hold on a per-play basis and are shown to hold in a global sense. Clearly, such a property is not necessarily true of arbitrary single arm policies and finding such single arm policies is nontrivial. We show that by restricting the state spaces of arms we can find single arm policies and that these single arm policies can be combined into global (near) index policies where the approximate version of the exchange property is true in expectation. The number of different bandit problems that can be addressed by this technique already demonstrate its wide applicability.