 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion the Questions: Auditing Representation in Online Deliberative Processes
Nov 06, 2025A central feature of many deliberative processes, such as citizens' assemblies and deliberative polls, is the opportunity for participants to engage directly with experts. While participants are typically invited to propose questions for expert panels, only a limited number can be selected due to time constraints. This raises the challenge of how to choose a small set of questions that best represent the interests of all participants. We introduce an auditing framework for measuring the level of representation provided by a slate of questions, based on the social choice concept known as justified representation (JR). We present the first algorithms for auditing JR in the general utility setting, with our most efficient algorithm achieving a runtime of $O(mn\log n)$, where $n$ is the number of participants and $m$ is the number of proposed questions. We apply our auditing methods to historical deliberations, comparing the representativeness of (a) the actual questions posed to the expert panel (chosen by a moderator), (b) participants' questions chosen via integer linear programming, (c) summary questions generated by large language models (LLMs). Our results highlight both the promise and current limitations of LLMs in supporting deliberative processes. By integrating our methods into an online deliberation platform that has been used for over hundreds of deliberations across more than 50 countries, we make it easy for practitioners to audit and improve representation in future deliberations.
Estimating Contribution Quality in Online Deliberations Using a Large Language Model
Aug 21, 2024
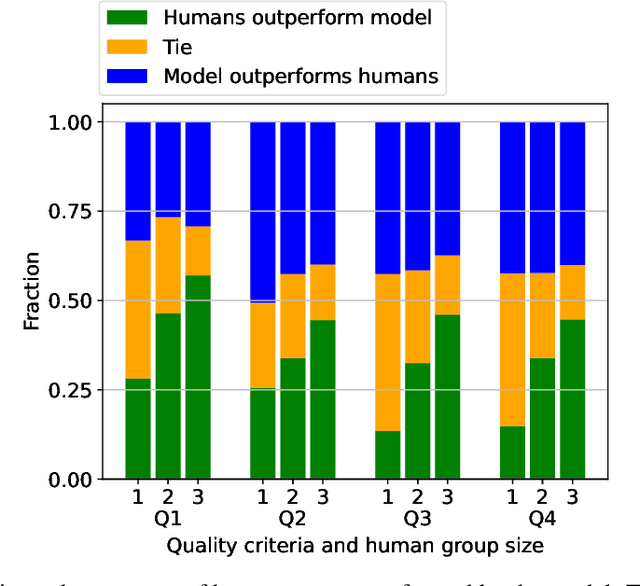
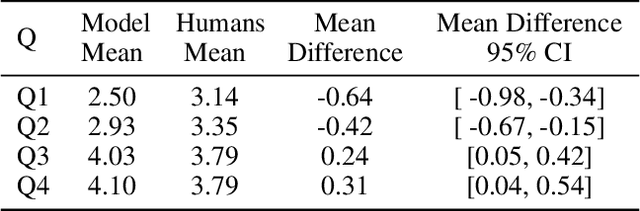

Deliberation involves participants exchanging knowledge, arguments, and perspectives and has been shown to be effective at addressing polarization. The Stanford Online Deliberation Platform facilitates large-scale deliberations. It enables video-based online discussions on a structured agenda for small groups without requiring human moderators. This paper's data comes from various deliberation events, including one conducted in collaboration with Meta in 32 countries, and another with 38 post-secondary institutions in the US. Estimating the quality of contributions in a conversation is crucial for assessing feature and intervention impacts. Traditionally, this is done by human annotators, which is time-consuming and costly. We use a large language model (LLM) alongside eight human annotators to rate contributions based on justification, novelty, expansion of the conversation, and potential for further expansion, with scores ranging from 1 to 5. Annotators also provide brief justifications for their ratings. Using the average rating from other human annotators as the ground truth, we find the model outperforms individual human annotators. While pairs of human annotators outperform the model in rating justification and groups of three outperform it on all four metrics, the model remains competitive. We illustrate the usefulness of the automated quality rating by assessing the effect of nudges on the quality of deliberation. We first observe that individual nudges after prolonged inactivity are highly effective, increasing the likelihood of the individual requesting to speak in the next 30 seconds by 65%. Using our automated quality estimation, we show that the quality ratings for statements prompted by nudging are similar to those made without nudging, signifying that nudging leads to more ideas being generated in the conversation without losing overall quality.
Robust Allocations with Diversity Constraints
Sep 30, 2021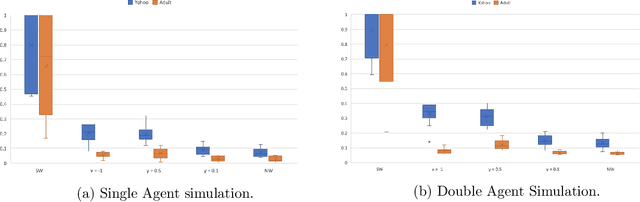
We consider the problem of allocating divisible items among multiple agents, and consider the setting where any agent is allowed to introduce diversity constraints on the items they are allocated. We motivate this via settings where the items themselves correspond to user ad slots or task workers with attributes such as race and gender on which the principal seeks to achieve demographic parity. We consider the following question: When an agent expresses diversity constraints into an allocation rule, is the allocation of other agents hurt significantly? If this happens, the cost of introducing such constraints is disproportionately borne by agents who do not benefit from diversity. We codify this via two desiderata capturing robustness. These are no negative externality -- other agents are not hurt -- and monotonicity -- the agent enforcing the constraint does not see a large increase in value. We show in a formal sense that the Nash Welfare rule that maximizes product of agent values is uniquely positioned to be robust when diversity constraints are introduced, while almost all other natural allocation rules fail this criterion. We also show that the guarantees achieved by Nash Welfare are nearly optimal within a widely studied class of allocation rules. We finally perform an empirical simulation on real-world data that models ad allocations to show that this gap between Nash Welfare and other rules persists in the wild.
Who is in Your Top Three? Optimizing Learning in Elections with Many Candidates
Jun 19, 2019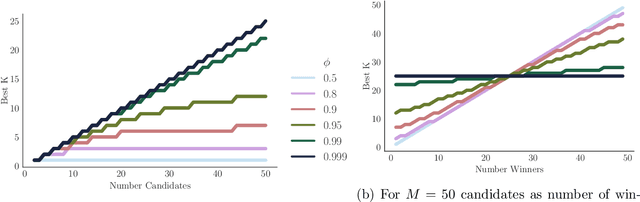
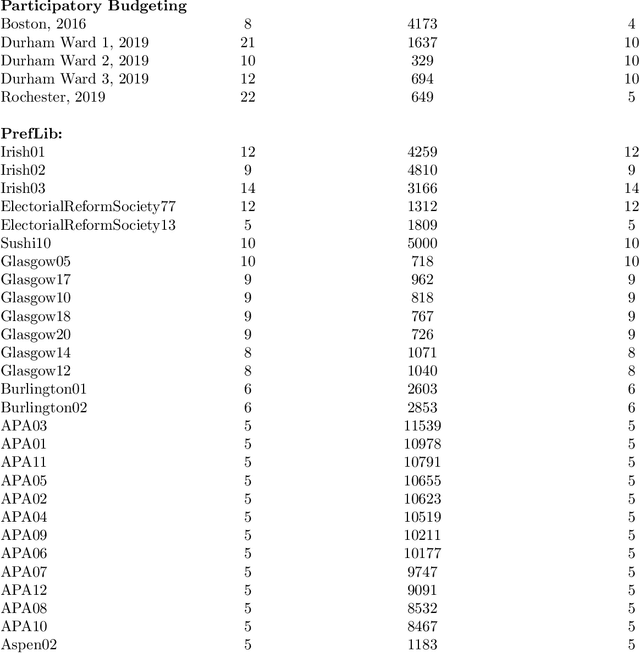
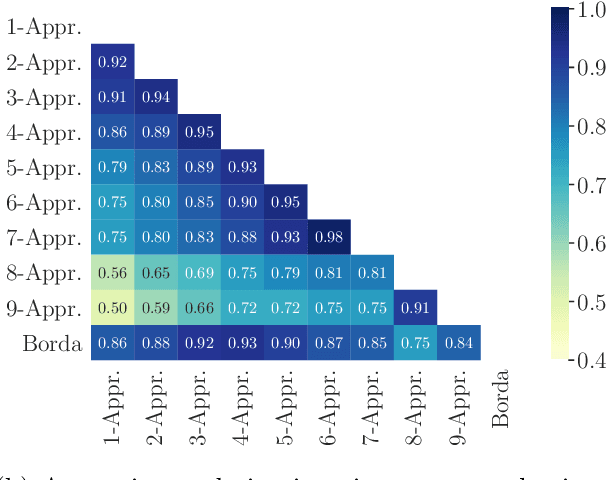
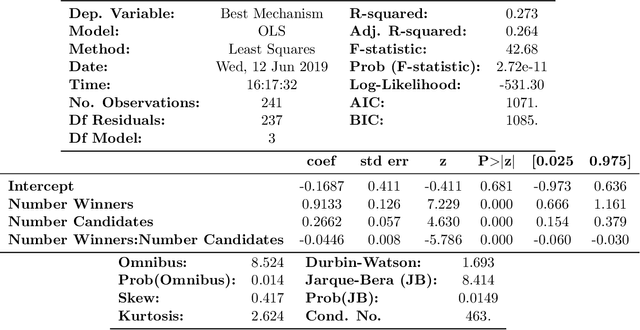
Elections and opinion polls often have many candidates, with the aim to either rank the candidates or identify a small set of winners according to voters' preferences. In practice, voters do not provide a full ranking; instead, each voter provides their favorite K candidates, potentially in ranked order. The election organizer must choose K and an aggregation rule. We provide a theoretical framework to make these choices. Each K-Approval or K-partial ranking mechanism (with a corresponding positional scoring rule) induces a learning rate for the speed at which the election correctly recovers the asymptotic outcome. Given the voter choice distribution, the election planner can thus identify the rate optimal mechanism. Earlier work in this area provides coarse order-of-magnitude guaranties which are not sufficient to make such choices. Our framework further resolves questions of when randomizing between multiple mechanisms may improve learning, for arbitrary voter noise models. Finally, we use data from 5 large participatory budgeting elections that we organized across several US cities, along with other ranking data, to demonstrate the utility of our methods. In particular, we find that historically such elections have set K too low and that picking the right mechanism can be the difference between identifying the ultimate winner with only a 80% probability or a 99.9% probability after 400 voters.