 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion the Questions: Auditing Representation in Online Deliberative Processes
Nov 06, 2025A central feature of many deliberative processes, such as citizens' assemblies and deliberative polls, is the opportunity for participants to engage directly with experts. While participants are typically invited to propose questions for expert panels, only a limited number can be selected due to time constraints. This raises the challenge of how to choose a small set of questions that best represent the interests of all participants. We introduce an auditing framework for measuring the level of representation provided by a slate of questions, based on the social choice concept known as justified representation (JR). We present the first algorithms for auditing JR in the general utility setting, with our most efficient algorithm achieving a runtime of $O(mn\log n)$, where $n$ is the number of participants and $m$ is the number of proposed questions. We apply our auditing methods to historical deliberations, comparing the representativeness of (a) the actual questions posed to the expert panel (chosen by a moderator), (b) participants' questions chosen via integer linear programming, (c) summary questions generated by large language models (LLMs). Our results highlight both the promise and current limitations of LLMs in supporting deliberative processes. By integrating our methods into an online deliberation platform that has been used for over hundreds of deliberations across more than 50 countries, we make it easy for practitioners to audit and improve representation in future deliberations.
AI Space Cortex: An Experimental System for Future Era Space Exploration
Jul 09, 2025Our Robust, Explainable Autonomy for Scientific Icy Moon Operations (REASIMO) effort contributes to NASA's Concepts for Ocean worlds Life Detection Technology (COLDTech) program, which explores science platform technologies for ocean worlds such as Europa and Enceladus. Ocean world missions pose significant operational challenges. These include long communication lags, limited power, and lifetime limitations caused by radiation damage and hostile conditions. Given these operational limitations, onboard autonomy will be vital for future Ocean world missions. Besides the management of nominal lander operations, onboard autonomy must react appropriately in the event of anomalies. Traditional spacecraft rely on a transition into 'safe-mode' in which non-essential components and subsystems are powered off to preserve safety and maintain communication with Earth. For a severely time-limited Ocean world mission, resolutions to these anomalies that can be executed without Earth-in-the-loop communication and associated delays are paramount for completion of the mission objectives and science goals. To address these challenges, the REASIMO effort aims to demonstrate a robust level of AI-assisted autonomy for such missions, including the ability to detect and recover from anomalies, and to perform missions based on pre-trained behaviors rather than hard-coded, predetermined logic like all prior space missions. We developed an AI-assisted, personality-driven, intelligent framework for control of an Ocean world mission by combining a mix of advanced technologies. To demonstrate the capabilities of the framework, we perform tests of autonomous sampling operations on a lander-manipulator testbed at the NASA Jet Propulsion Laboratory, approximating possible surface conditions such a mission might encounter.
Multi-Selection for Recommendation Systems
Apr 10, 2025We present the construction of a multi-selection model to answer differentially private queries in the context of recommendation systems. The server sends back multiple recommendations and a ``local model'' to the user, which the user can run locally on its device to select the item that best fits its private features. We study a setup where the server uses a deep neural network (trained on the Movielens 25M dataset as the ground truth for movie recommendation. In the multi-selection paradigm, the average recommendation utility is approximately 97\% of the optimal utility (as determined by the ground truth neural network) while maintaining a local differential privacy guarantee with $\epsilon$ ranging around 1 with respect to feature vectors of neighboring users. This is in comparison to an average recommendation utility of 91\% in the non-multi-selection regime under the same constraints.
Flight Demonstration and Model Validation of a Prototype Variable-Altitude Venus Aerobot
Nov 11, 2024
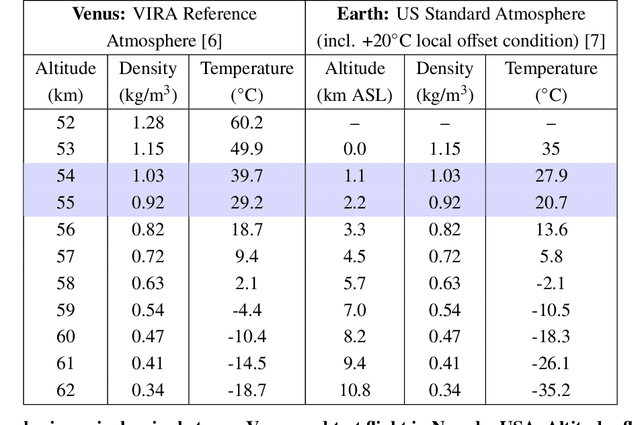

This paper details a significant milestone towards maturing a buoyant aerial robotic platform, or aerobot, for flight in the Venus clouds. We describe two flights of our subscale altitude-controlled aerobot, fabricated from the materials necessary to survive Venus conditions. During these flights over the Nevada Black Rock desert, the prototype flew at the identical atmospheric densities as 54 to 55 km cloud layer altitudes on Venus. We further describe a first-principle aerobot dynamics model which we validate against the Nevada flight data and subsequently employ to predict the performance of future aerobots on Venus. The aerobot discussed in this paper is under JPL development for an in-situ mission flying multiple circumnavigations of Venus, sampling the chemical and physical properties of the planet's atmosphere and also remotely sensing surface properties.
Estimating Contribution Quality in Online Deliberations Using a Large Language Model
Aug 21, 2024
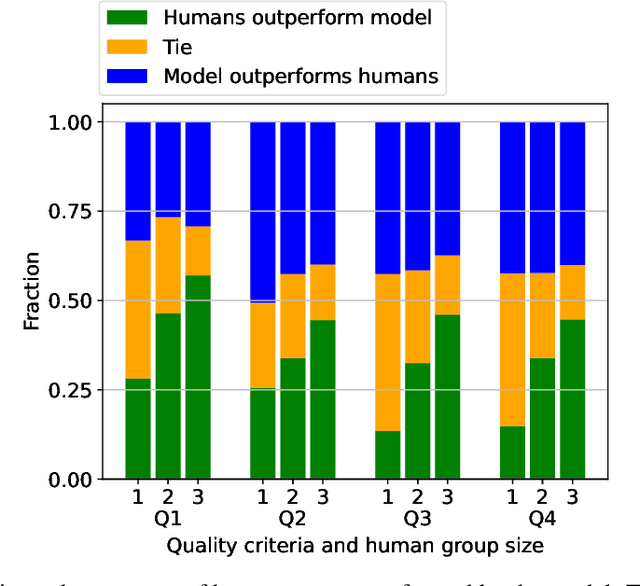
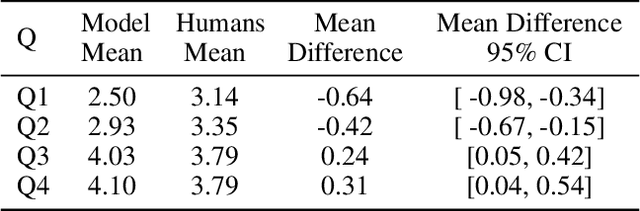

Deliberation involves participants exchanging knowledge, arguments, and perspectives and has been shown to be effective at addressing polarization. The Stanford Online Deliberation Platform facilitates large-scale deliberations. It enables video-based online discussions on a structured agenda for small groups without requiring human moderators. This paper's data comes from various deliberation events, including one conducted in collaboration with Meta in 32 countries, and another with 38 post-secondary institutions in the US. Estimating the quality of contributions in a conversation is crucial for assessing feature and intervention impacts. Traditionally, this is done by human annotators, which is time-consuming and costly. We use a large language model (LLM) alongside eight human annotators to rate contributions based on justification, novelty, expansion of the conversation, and potential for further expansion, with scores ranging from 1 to 5. Annotators also provide brief justifications for their ratings. Using the average rating from other human annotators as the ground truth, we find the model outperforms individual human annotators. While pairs of human annotators outperform the model in rating justification and groups of three outperform it on all four metrics, the model remains competitive. We illustrate the usefulness of the automated quality rating by assessing the effect of nudges on the quality of deliberation. We first observe that individual nudges after prolonged inactivity are highly effective, increasing the likelihood of the individual requesting to speak in the next 30 seconds by 65%. Using our automated quality estimation, we show that the quality ratings for statements prompted by nudging are similar to those made without nudging, signifying that nudging leads to more ideas being generated in the conversation without losing overall quality.
Few-shot Scooping Under Domain Shift via Simulated Maximal Deployment Gaps
Aug 06, 2024



Autonomous lander missions on extraterrestrial bodies need to sample granular materials while coping with domain shifts, even when sampling strategies are extensively tuned on Earth. To tackle this challenge, this paper studies the few-shot scooping problem and proposes a vision-based adaptive scooping strategy that uses the deep kernel Gaussian process method trained with a novel meta-training strategy to learn online from very limited experience on out-of-distribution target terrains. Our Deep Kernel Calibration with Maximal Deployment Gaps (kCMD) strategy explicitly trains a deep kernel model to adapt to large domain shifts by creating simulated maximal deployment gaps from an offline training dataset and training models to overcome these deployment gaps during training. Employed in a Bayesian Optimization sequential decision-making framework, the proposed method allows the robot to perform high-quality scooping actions on out-of-distribution terrains after a few attempts, significantly outperforming non-adaptive methods proposed in the excavation literature as well as other state-of-the-art meta-learning methods. The proposed method also demonstrates zero-shot transfer capability, successfully adapting to the NASA OWLAT platform, which serves as a state-of-the-art simulator for potential future planetary missions. These results demonstrate the potential of training deep models with simulated deployment gaps for more generalizable meta-learning in high-capacity models. Furthermore, they highlight the promise of our method in autonomous lander sampling missions by enabling landers to overcome the deployment gap between Earth and extraterrestrial bodies.
Learning and Autonomy for Extraterrestrial Terrain Sampling: An Experience Report from OWLAT Deployment
Dec 04, 2023Extraterrestrial autonomous lander missions increasingly demand adaptive capabilities to handle the unpredictable and diverse nature of the terrain. This paper discusses the deployment of a Deep Meta-Learning with Controlled Deployment Gaps (CoDeGa) trained model for terrain scooping tasks in Ocean Worlds Lander Autonomy Testbed (OWLAT) at NASA Jet Propulsion Laboratory. The CoDeGa-powered scooping strategy is designed to adapt to novel terrains, selecting scooping actions based on the available RGB-D image data and limited experience. The paper presents our experiences with transferring the scooping framework with CoDeGa-trained model from a low-fidelity testbed to the high-fidelity OWLAT testbed. Additionally, it validates the method's performance in novel, realistic environments, and shares the lessons learned from deploying learning-based autonomy algorithms for space exploration. Experimental results from OWLAT substantiate the efficacy of CoDeGa in rapidly adapting to unfamiliar terrains and effectively making autonomous decisions under considerable domain shifts, thereby endorsing its potential utility in future extraterrestrial missions.
Robust Allocations with Diversity Constraints
Sep 30, 2021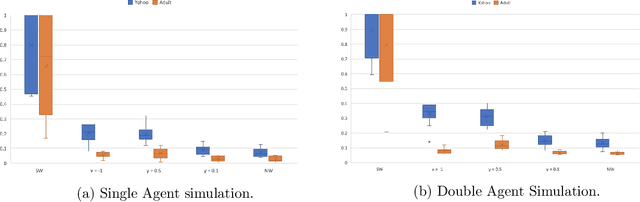
We consider the problem of allocating divisible items among multiple agents, and consider the setting where any agent is allowed to introduce diversity constraints on the items they are allocated. We motivate this via settings where the items themselves correspond to user ad slots or task workers with attributes such as race and gender on which the principal seeks to achieve demographic parity. We consider the following question: When an agent expresses diversity constraints into an allocation rule, is the allocation of other agents hurt significantly? If this happens, the cost of introducing such constraints is disproportionately borne by agents who do not benefit from diversity. We codify this via two desiderata capturing robustness. These are no negative externality -- other agents are not hurt -- and monotonicity -- the agent enforcing the constraint does not see a large increase in value. We show in a formal sense that the Nash Welfare rule that maximizes product of agent values is uniquely positioned to be robust when diversity constraints are introduced, while almost all other natural allocation rules fail this criterion. We also show that the guarantees achieved by Nash Welfare are nearly optimal within a widely studied class of allocation rules. We finally perform an empirical simulation on real-world data that models ad allocations to show that this gap between Nash Welfare and other rules persists in the wild.
GNSS Radio Occultation on Aerial Platforms with Commercial Off-The-Shelf Receivers
Sep 27, 2021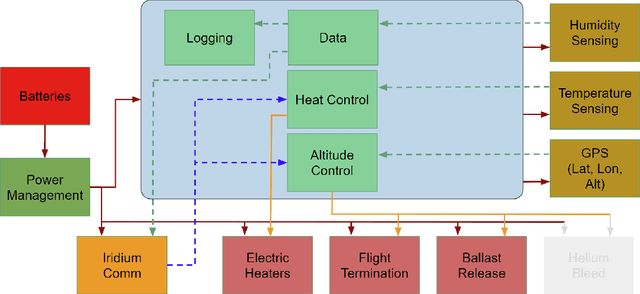



In recent decades, GNSS Radio Occultation soundings have proven an invaluable input to global weather forecasting. The success of government-sponsored programs such as COSMIC is now complemented by commercial low-cost cubesat implementations. The result is access to more than 10,000 soundings per day and improved weather forecasting accuracy. This movement towards commercialization has been supported by several agencies, including the National Aeronautics and Space Administration (NASA), National Oceanic and Atmospheric Administration (NOAA) and the U.S. Air Force (USAF) with programs such as the Commercial Weather Data Pilot (CWDP). This has resulted in further interest in commercially deploying GNSS-RO on complementary platforms. Here, we examine a so far underutilized platform: the high-altitude weather balloon. Such meteorological radiosondes are deployed twice daily at over 900 locations globally and form an essential in-situ data source as a long-standing input to weather forecasting models. Adding GNSS-RO capability to existing radiosonde platforms would greatly expand capability, allowing for persistent and local area monitoring, a feature particularly useful for hurricane and other severe weather monitoring. A prohibitive barrier to entry to this inclusion is cost and complexity as GNSS-RO traditionally requires highly specialized and sensitive equipment. This paper describes a multi-year effort to develop a low-cost and scalable approach to balloon GNSS-RO based on Commercial-Off-The-Shelf (COTS) GNSS receivers. We present hardware prototypes and data processing techniques which demonstrate the technical feasibility of the approach through results from several flight testing campaigns.
Satellite Navigation for the Age of Autonomy
May 19, 2020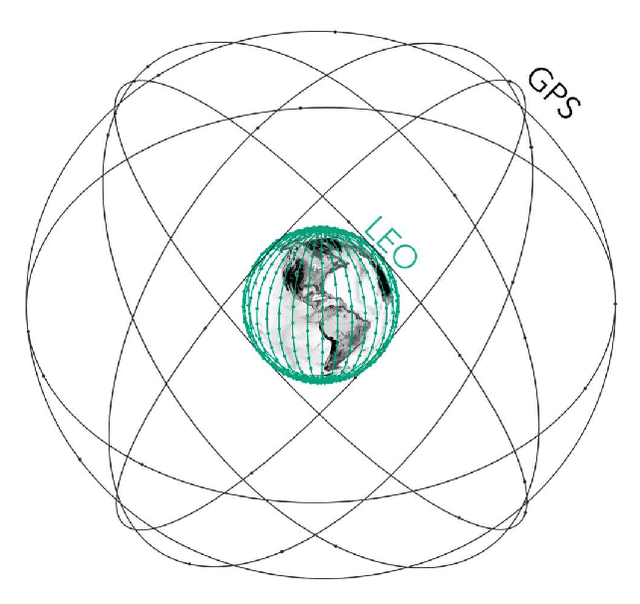
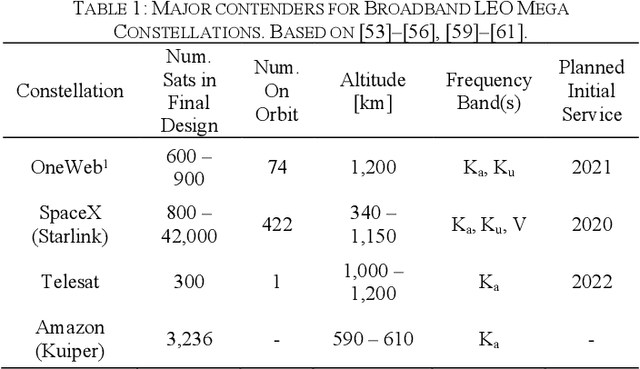
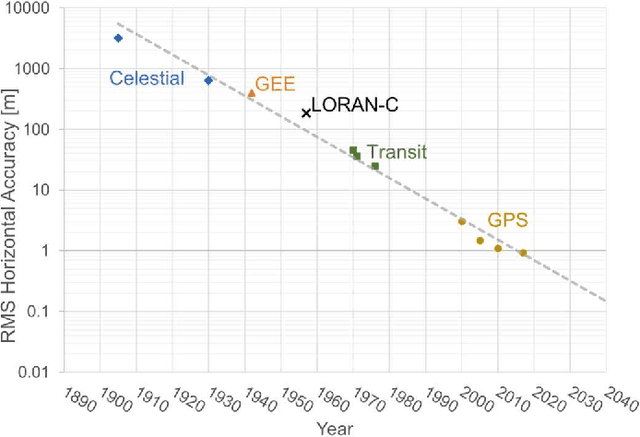

Global Navigation Satellite Systems (GNSS) brought navigation to the masses. Coupled with smartphones, the blue dot in the palm of our hands has forever changed the way we interact with the world. Looking forward, cyber-physical systems such as self-driving cars and aerial mobility are pushing the limits of what localization technologies including GNSS can provide. This autonomous revolution requires a solution that supports safety-critical operation, centimeter positioning, and cyber-security for millions of users. To meet these demands, we propose a navigation service from Low Earth Orbiting (LEO) satellites which deliver precision in-part through faster motion, higher power signals for added robustness to interference, constellation autonomous integrity monitoring for integrity, and encryption / authentication for resistance to spoofing attacks. This paradigm is enabled by the 'New Space' movement, where highly capable satellites and components are now built on assembly lines and launch costs have decreased by more than tenfold. Such a ubiquitous positioning service enables a consistent and secure standard where trustworthy information can be validated and shared, extending the electronic horizon from sensor line of sight to an entire city. This enables the situational awareness needed for true safe operation to support autonomy at scale.
* 11 pages, 8 figures, 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS)