 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Student Interaction Patterns with Large Language Model-Powered Course Assistants in Computer Science Courses
Sep 10, 2025Providing students with flexible and timely academic support is a challenge at most colleges and universities, leaving many students without help outside scheduled hours. Large language models (LLMs) are promising for bridging this gap, but interactions between students and LLMs are rarely overseen by educators. We developed and studied an LLM-powered course assistant deployed across multiple computer science courses to characterize real-world use and understand pedagogical implications. By Spring 2024, our system had been deployed to approximately 2,000 students across six courses at three institutions. Analysis of the interaction data shows that usage remains strong in the evenings and nights and is higher in introductory courses, indicating that our system helps address temporal support gaps and novice learner needs. We sampled 200 conversations per course for manual annotation: most sampled responses were judged correct and helpful, with a small share unhelpful or erroneous; few responses included dedicated examples. We also examined an inquiry-based learning strategy: only around 11% of sampled conversations contained LLM-generated follow-up questions, which were often ignored by students in advanced courses. A Bloom's taxonomy analysis reveals that current LLM capabilities are limited in generating higher-order cognitive questions. These patterns suggest opportunities for pedagogically oriented LLM-based educational systems and greater educator involvement in configuring prompts, content, and policies.
Classic Graph Structural Features Outperform Factorization-Based Graph Embedding Methods on Community Labeling
Jan 20, 2022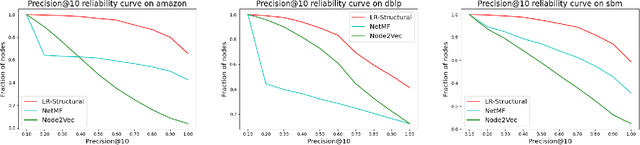
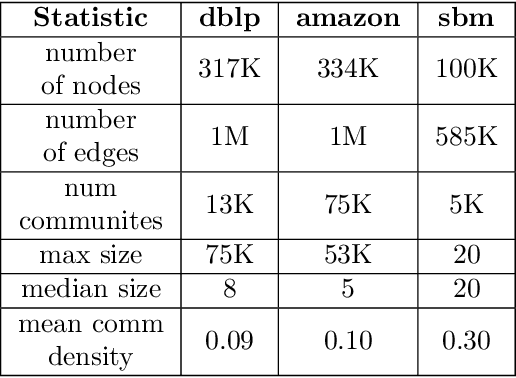
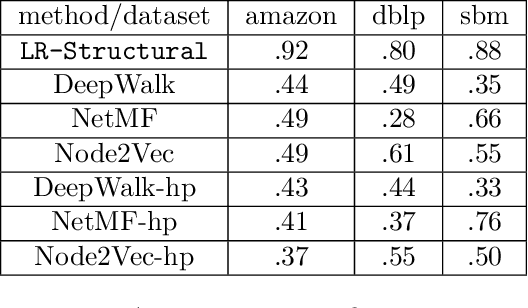

Graph representation learning (also called graph embeddings) is a popular technique for incorporating network structure into machine learning models. Unsupervised graph embedding methods aim to capture graph structure by learning a low-dimensional vector representation (the embedding) for each node. Despite the widespread use of these embeddings for a variety of downstream transductive machine learning tasks, there is little principled analysis of the effectiveness of this approach for common tasks. In this work, we provide an empirical and theoretical analysis for the performance of a class of embeddings on the common task of pairwise community labeling. This is a binary variant of the classic community detection problem, which seeks to build a classifier to determine whether a pair of vertices participate in a community. In line with our goal of foundational understanding, we focus on a popular class of unsupervised embedding techniques that learn low rank factorizations of a vertex proximity matrix (this class includes methods like GraRep, DeepWalk, node2vec, NetMF). We perform detailed empirical analysis for community labeling over a variety of real and synthetic graphs with ground truth. In all cases we studied, the models trained from embedding features perform poorly on community labeling. In constrast, a simple logistic model with classic graph structural features handily outperforms the embedding models. For a more principled understanding, we provide a theoretical analysis for the (in)effectiveness of these embeddings in capturing the community structure. We formally prove that popular low-dimensional factorization methods either cannot produce community structure, or can only produce ``unstable" communities. These communities are inherently unstable under small perturbations.
The impossibility of low rank representations for triangle-rich complex networks
Mar 27, 2020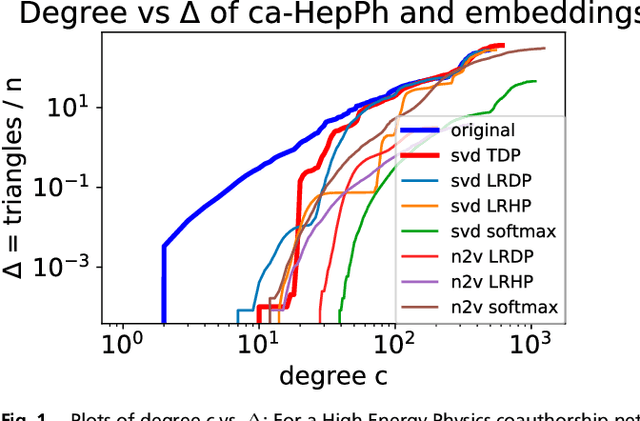
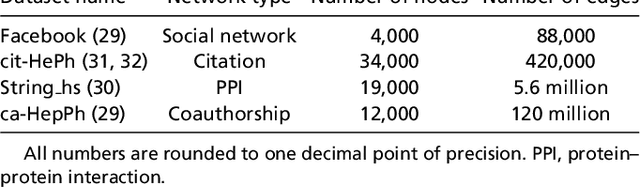
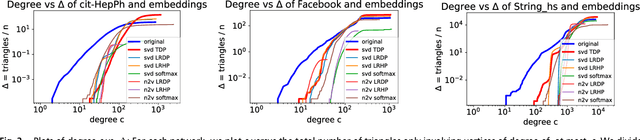
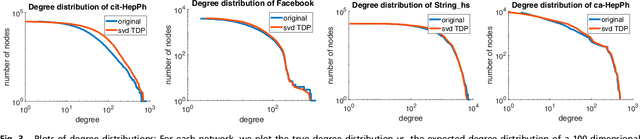
The study of complex networks is a significant development in modern science, and has enriched the social sciences, biology, physics, and computer science. Models and algorithms for such networks are pervasive in our society, and impact human behavior via social networks, search engines, and recommender systems to name a few. A widely used algorithmic technique for modeling such complex networks is to construct a low-dimensional Euclidean embedding of the vertices of the network, where proximity of vertices is interpreted as the likelihood of an edge. Contrary to the common view, we argue that such graph embeddings do not}capture salient properties of complex networks. The two properties we focus on are low degree and large clustering coefficients, which have been widely established to be empirically true for real-world networks. We mathematically prove that any embedding (that uses dot products to measure similarity) that can successfully create these two properties must have rank nearly linear in the number of vertices. Among other implications, this establishes that popular embedding techniques such as Singular Value Decomposition and node2vec fail to capture significant structural aspects of real-world complex networks. Furthermore, we empirically study a number of different embedding techniques based on dot product, and show that they all fail to capture the triangle structure.