 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassic Graph Structural Features Outperform Factorization-Based Graph Embedding Methods on Community Labeling
Paper and Code
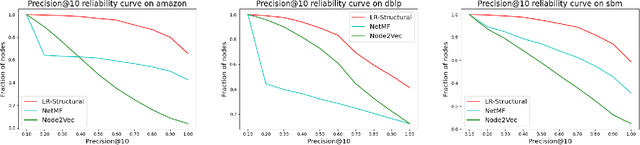
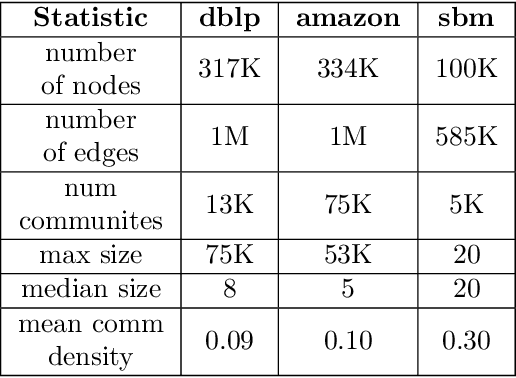
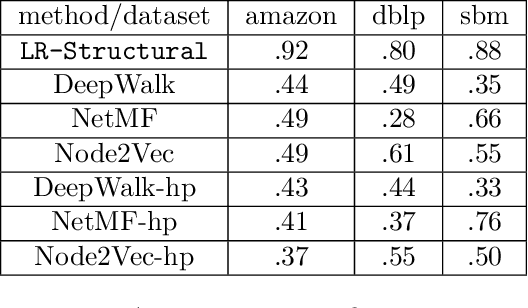

Graph representation learning (also called graph embeddings) is a popular technique for incorporating network structure into machine learning models. Unsupervised graph embedding methods aim to capture graph structure by learning a low-dimensional vector representation (the embedding) for each node. Despite the widespread use of these embeddings for a variety of downstream transductive machine learning tasks, there is little principled analysis of the effectiveness of this approach for common tasks. In this work, we provide an empirical and theoretical analysis for the performance of a class of embeddings on the common task of pairwise community labeling. This is a binary variant of the classic community detection problem, which seeks to build a classifier to determine whether a pair of vertices participate in a community. In line with our goal of foundational understanding, we focus on a popular class of unsupervised embedding techniques that learn low rank factorizations of a vertex proximity matrix (this class includes methods like GraRep, DeepWalk, node2vec, NetMF). We perform detailed empirical analysis for community labeling over a variety of real and synthetic graphs with ground truth. In all cases we studied, the models trained from embedding features perform poorly on community labeling. In constrast, a simple logistic model with classic graph structural features handily outperforms the embedding models. For a more principled understanding, we provide a theoretical analysis for the (in)effectiveness of these embeddings in capturing the community structure. We formally prove that popular low-dimensional factorization methods either cannot produce community structure, or can only produce ``unstable" communities. These communities are inherently unstable under small perturbations.