 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Contribution Quality in Online Deliberations Using a Large Language Model
Aug 21, 2024
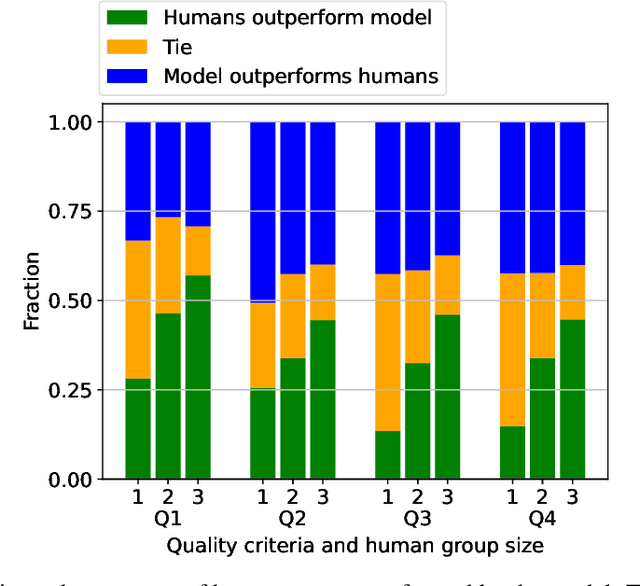
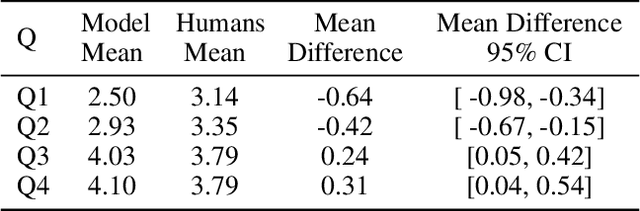

Deliberation involves participants exchanging knowledge, arguments, and perspectives and has been shown to be effective at addressing polarization. The Stanford Online Deliberation Platform facilitates large-scale deliberations. It enables video-based online discussions on a structured agenda for small groups without requiring human moderators. This paper's data comes from various deliberation events, including one conducted in collaboration with Meta in 32 countries, and another with 38 post-secondary institutions in the US. Estimating the quality of contributions in a conversation is crucial for assessing feature and intervention impacts. Traditionally, this is done by human annotators, which is time-consuming and costly. We use a large language model (LLM) alongside eight human annotators to rate contributions based on justification, novelty, expansion of the conversation, and potential for further expansion, with scores ranging from 1 to 5. Annotators also provide brief justifications for their ratings. Using the average rating from other human annotators as the ground truth, we find the model outperforms individual human annotators. While pairs of human annotators outperform the model in rating justification and groups of three outperform it on all four metrics, the model remains competitive. We illustrate the usefulness of the automated quality rating by assessing the effect of nudges on the quality of deliberation. We first observe that individual nudges after prolonged inactivity are highly effective, increasing the likelihood of the individual requesting to speak in the next 30 seconds by 65%. Using our automated quality estimation, we show that the quality ratings for statements prompted by nudging are similar to those made without nudging, signifying that nudging leads to more ideas being generated in the conversation without losing overall quality.