 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Discoveries of Algorithmist I: Promise of Provable Algorithm Synthesis at Scale
Mar 23, 2026Designing algorithms with provable guarantees that also work well in practice remains difficult, requiring both mathematical reasoning and careful implementation. Existing approaches that bridge worst-case theory and empirical performance, such as beyond-worst-case analysis and data-driven algorithm selection, typically assume prior distributional knowledge or restrict attention to a fixed pool of algorithms. Recent progress in LLMs suggests a new possibility: provable algorithm synthesis on the fly. To study this, we built Algorithmist, an autonomous researcher agent on top of GitHub Copilot that runs a multi-agent research-and-review loop, with separate stages for idea generation, algorithm and proof development, proof-guided implementation, and review of proofs, code, and their alignment. We evaluate Algorithmist on research-level tasks in private data analysis and clustering. When asked to design practical methods that jointly satisfy privacy, approximation, and interpretability requirements, it produced provably sound and empirically effective algorithms, together with research-style writeups and audited implementations. It also found improved algorithms in some settings, explained principled barriers in others, and uncovered a subtle proof bug in prior published work. More broadly, our results suggest a new paradigm in which LLM systems generate research-paper-quality algorithmic artifacts tailored to each dataset and deployment setting. They also point to a proof-first code-synthesis paradigm, in which code is developed alongside a structured natural-language proof intermediate representation and kept aligned with it throughout synthesis.
Dyna-Mind: Learning to Simulate from Experience for Better AI Agents
Oct 10, 2025



Reasoning models have recently shown remarkable progress in domains such as math and coding. However, their expert-level abilities in math and coding contrast sharply with their performance in long-horizon, interactive tasks such as web navigation and computer/phone-use. Inspired by literature on human cognition, we argue that current AI agents need ''vicarious trial and error'' - the capacity to mentally simulate alternative futures before acting - in order to enhance their understanding and performance in complex interactive environments. We introduce Dyna-Mind, a two-stage training framework that explicitly teaches (V)LM agents to integrate such simulation into their reasoning. In stage 1, we introduce Reasoning with Simulations (ReSim), which trains the agent to generate structured reasoning traces from expanded search trees built from real experience gathered through environment interactions. ReSim thus grounds the agent's reasoning in faithful world dynamics and equips it with the ability to anticipate future states in its reasoning. In stage 2, we propose Dyna-GRPO, an online reinforcement learning method to further strengthen the agent's simulation and decision-making ability by using both outcome rewards and intermediate states as feedback from real rollouts. Experiments on two synthetic benchmarks (Sokoban and ALFWorld) and one realistic benchmark (AndroidWorld) demonstrate that (1) ReSim effectively infuses simulation ability into AI agents, and (2) Dyna-GRPO leverages outcome and interaction-level signals to learn better policies for long-horizon, planning-intensive tasks. Together, these results highlight the central role of simulation in enabling AI agents to reason, plan, and act more effectively in the ever more challenging environments.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
On the Emergence of Thinking in LLMs I: Searching for the Right Intuition
Feb 10, 2025



Recent AI advancements, such as OpenAI's new models, are transforming LLMs into LRMs (Large Reasoning Models) that perform reasoning during inference, taking extra time and compute for higher-quality outputs. We aim to uncover the algorithmic framework for training LRMs. Methods like self-consistency, PRM, and AlphaZero suggest reasoning as guided search. We ask: what is the simplest, most scalable way to enable search in LLMs? We propose a post-training framework called Reinforcement Learning via Self-Play (RLSP). RLSP involves three steps: (1) supervised fine-tuning with human or synthetic demonstrations of the reasoning process, (2) using an exploration reward signal to encourage diverse and efficient reasoning behaviors, and (3) RL training with an outcome verifier to ensure correctness while preventing reward hacking. Our key innovation is to decouple exploration and correctness signals during PPO training, carefully balancing them to improve performance and efficiency. Empirical studies in the math domain show that RLSP improves reasoning. On the Llama-3.1-8B-Instruct model, RLSP can boost performance by 23% in MATH-500 test set; On AIME 2024 math problems, Qwen2.5-32B-Instruct improved by 10% due to RLSP. However, a more important finding of this work is that the models trained using RLSP, even with the simplest exploration reward that encourages the model to take more intermediate steps, showed several emergent behaviors such as backtracking, exploration of ideas, and verification. These findings demonstrate that RLSP framework might be enough to enable emergence of complex reasoning abilities in LLMs when scaled. Lastly, we propose a theory as to why RLSP search strategy is more suitable for LLMs inspired by a remarkable result that says CoT provably increases computational power of LLMs, which grows as the number of steps in CoT \cite{li2024chain,merrill2023expresssive}.
DiscQuant: A Quantization Method for Neural Networks Inspired by Discrepancy Theory
Jan 11, 2025Quantizing the weights of a neural network has two steps: (1) Finding a good low bit-complexity representation for weights (which we call the quantization grid) and (2) Rounding the original weights to values in the quantization grid. In this paper, we study the problem of rounding optimally given any quantization grid. The simplest and most commonly used way to round is Round-to-Nearest (RTN). By rounding in a data-dependent way instead, one can improve the quality of the quantized model significantly. We study the rounding problem from the lens of \emph{discrepancy theory}, which studies how well we can round a continuous solution to a discrete solution without affecting solution quality too much. We prove that given $m=\mathrm{poly}(1/\epsilon)$ samples from the data distribution, we can round all but $O(m)$ model weights such that the expected approximation error of the quantized model on the true data distribution is $\le \epsilon$ as long as the space of gradients of the original model is approximately low rank (which we empirically validate). Our proof, which is algorithmic, inspired a simple and practical rounding algorithm called \emph{DiscQuant}. In our experiments, we demonstrate that DiscQuant significantly improves over the prior state-of-the-art rounding method called GPTQ and the baseline RTN over a range of benchmarks on Phi3mini-3.8B and Llama3.1-8B. For example, rounding Phi3mini-3.8B to a fixed quantization grid with 3.25 bits per parameter using DiscQuant gets 64\% accuracy on the GSM8k dataset, whereas GPTQ achieves 54\% and RTN achieves 31\% (the original model achieves 84\%). We make our code available at https://github.com/jerry-chee/DiscQuant.
Towards Foundation Models for Mixed Integer Linear Programming
Oct 10, 2024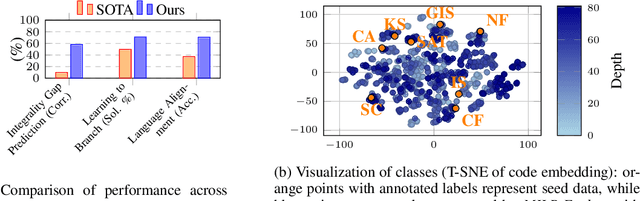

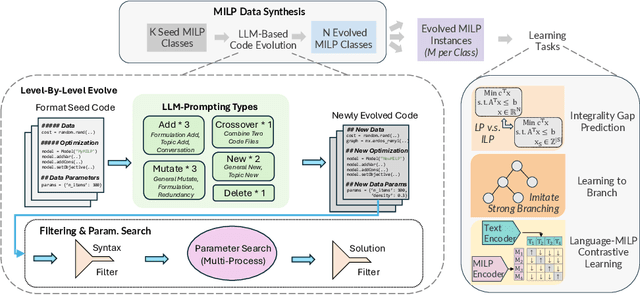
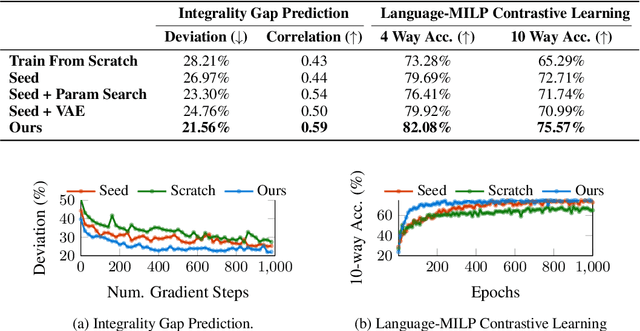
Mixed Integer Linear Programming (MILP) is essential for modeling complex decision-making problems but faces challenges in computational tractability and requires expert formulation. Current deep learning approaches for MILP focus on specific problem classes and do not generalize to unseen classes. To address this shortcoming, we take a foundation model training approach, where we train a single deep learning model on a diverse set of MILP problems to generalize across problem classes. As existing datasets for MILP lack diversity and volume, we introduce MILP-Evolve, a novel LLM-based evolutionary framework that is capable of generating a large set of diverse MILP classes with an unlimited amount of instances. We study our methodology on three key learning tasks that capture diverse aspects of MILP: (1) integrality gap prediction, (2) learning to branch, and (3) a new task of aligning MILP instances with natural language descriptions. Our empirical results show that models trained on the data generated by MILP-Evolve achieve significant improvements on unseen problems, including MIPLIB benchmarks. Our work highlights the potential of moving towards a foundation model approach for MILP that can generalize to a broad range of MILP applications. We are committed to fully open-sourcing our work to advance further research.
Differentially Private Training of Mixture of Experts Models
Feb 11, 2024

This position paper investigates the integration of Differential Privacy (DP) in the training of Mixture of Experts (MoE) models within the field of natural language processing. As Large Language Models (LLMs) scale to billions of parameters, leveraging expansive datasets, they exhibit enhanced linguistic capabilities and emergent abilities. However, this growth raises significant computational and privacy concerns. Our study addresses these issues by exploring the potential of MoE models, known for their computational efficiency, and the application of DP, a standard for privacy preservation. We present the first known attempt to train MoE models under the constraints of DP, addressing the unique challenges posed by their architecture and the complexities of DP integration. Our initial experimental studies demonstrate that MoE models can be effectively trained with DP, achieving performance that is competitive with their non-private counterparts. This initial study aims to provide valuable insights and ignite further research in the domain of privacy-preserving MoE models, softly laying the groundwork for prospective developments in this evolving field.
TinyGSM: achieving >80% on GSM8k with small language models
Dec 14, 2023



Small-scale models offer various computational advantages, and yet to which extent size is critical for problem-solving abilities remains an open question. Specifically for solving grade school math, the smallest model size so far required to break the 80\% barrier on the GSM8K benchmark remains to be 34B. Our work studies how high-quality datasets may be the key for small language models to acquire mathematical reasoning. We introduce \texttt{TinyGSM}, a synthetic dataset of 12.3M grade school math problems paired with Python solutions, generated fully by GPT-3.5. After finetuning on \texttt{TinyGSM}, we find that a duo of a 1.3B generation model and a 1.3B verifier model can achieve 81.5\% accuracy, outperforming existing models that are orders of magnitude larger. This also rivals the performance of the GPT-3.5 ``teacher'' model (77.4\%), from which our model's training data is generated. Our approach is simple and has two key components: 1) the high-quality dataset \texttt{TinyGSM}, 2) the use of a verifier, which selects the final outputs from multiple candidate generations.
Classification with Partially Private Features
Dec 11, 2023
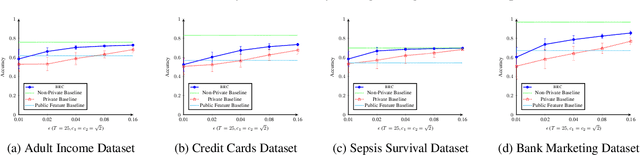
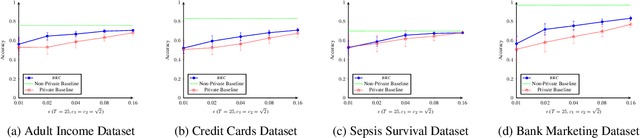
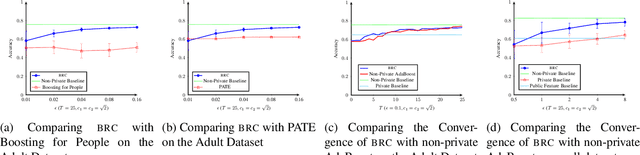
In this paper, we consider differentially private classification when some features are sensitive, while the rest of the features and the label are not. We adapt the definition of differential privacy naturally to this setting. Our main contribution is a novel adaptation of AdaBoost that is not only provably differentially private, but also significantly outperforms a natural benchmark that assumes the entire data of the individual is sensitive in the experiments. As a surprising observation, we show that boosting randomly generated classifiers suffices to achieve high accuracy. Our approach easily adapts to the classical setting where all the features are sensitive, providing an alternate algorithm for differentially private linear classification with a much simpler privacy proof and comparable or higher accuracy than differentially private logistic regression on real-world datasets.
Privately Aligning Language Models with Reinforcement Learning
Oct 25, 2023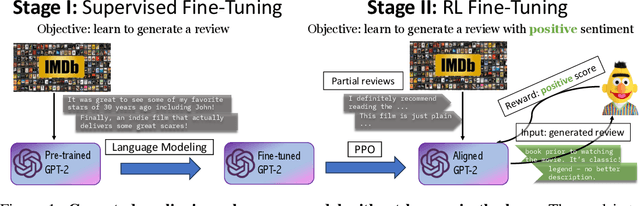
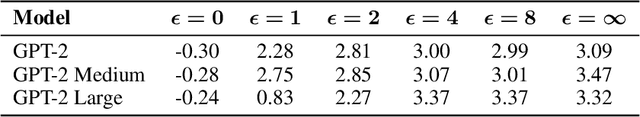

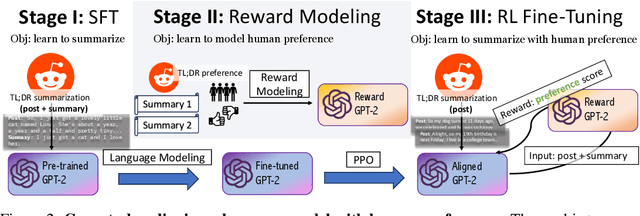
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.