 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Privacy Risks in Language Models: A Case Study on Summarization Tasks
Paper and Code
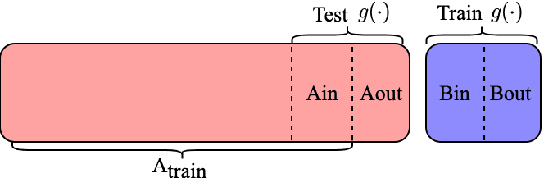
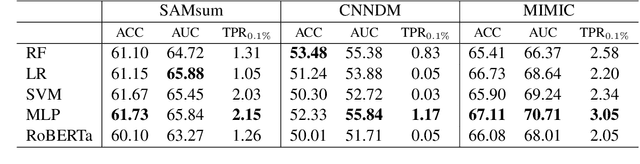
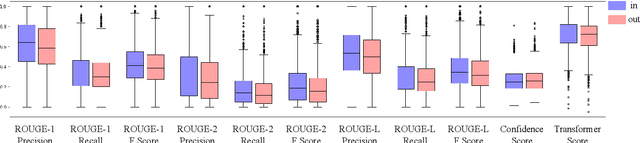
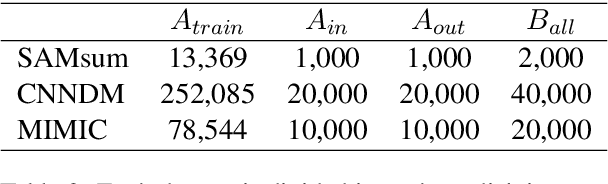
Large language models have revolutionized the field of NLP by achieving state-of-the-art performance on various tasks. However, there is a concern that these models may disclose information in the training data. In this study, we focus on the summarization task and investigate the membership inference (MI) attack: given a sample and black-box access to a model's API, it is possible to determine if the sample was part of the training data. We exploit text similarity and the model's resistance to document modifications as potential MI signals and evaluate their effectiveness on widely used datasets. Our results demonstrate that summarization models are at risk of exposing data membership, even in cases where the reference summary is not available. Furthermore, we discuss several safeguards for training summarization models to protect against MI attacks and discuss the inherent trade-off between privacy and utility.