 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Privacy Risks in Language Models: A Case Study on Summarization Tasks
Oct 20, 2023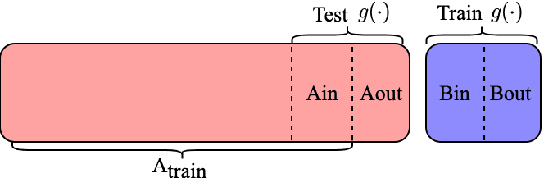
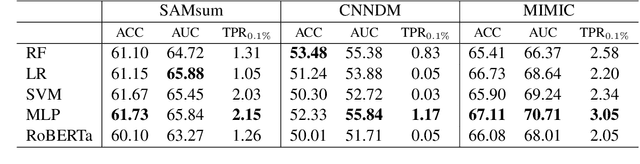
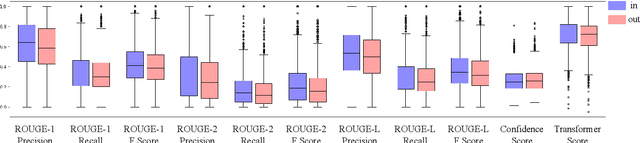
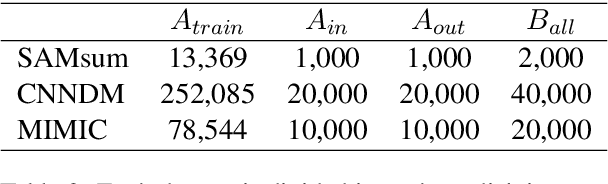
Large language models have revolutionized the field of NLP by achieving state-of-the-art performance on various tasks. However, there is a concern that these models may disclose information in the training data. In this study, we focus on the summarization task and investigate the membership inference (MI) attack: given a sample and black-box access to a model's API, it is possible to determine if the sample was part of the training data. We exploit text similarity and the model's resistance to document modifications as potential MI signals and evaluate their effectiveness on widely used datasets. Our results demonstrate that summarization models are at risk of exposing data membership, even in cases where the reference summary is not available. Furthermore, we discuss several safeguards for training summarization models to protect against MI attacks and discuss the inherent trade-off between privacy and utility.
AttributeNet: Attribute Enhanced Vehicle Re-Identification
Feb 07, 2021
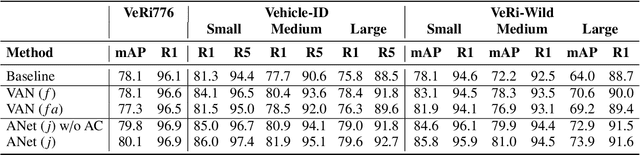
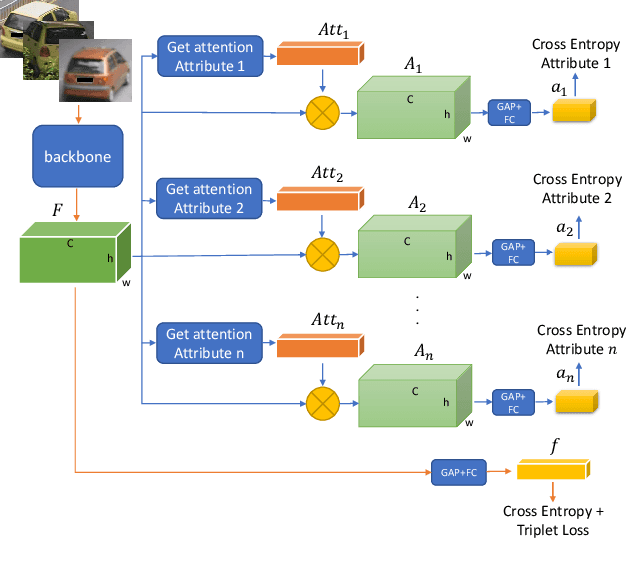
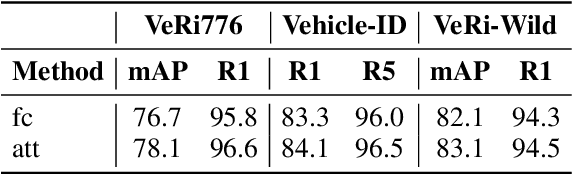
Vehicle Re-Identification (V-ReID) is a critical task that associates the same vehicle across images from different camera viewpoints. Many works explore attribute clues to enhance V-ReID; however, there is usually a lack of effective interaction between the attribute-related modules and final V-ReID objective. In this work, we propose a new method to efficiently explore discriminative information from vehicle attributes (e.g., color and type). We introduce AttributeNet (ANet) that jointly extracts identity-relevant features and attribute features. We enable the interaction by distilling the ReID-helpful attribute feature and adding it into the general ReID feature to increase the discrimination power. Moreover, we propose a constraint, named Amelioration Constraint (AC), which encourages the feature after adding attribute features onto the general ReID feature to be more discriminative than the original general ReID feature. We validate the effectiveness of our framework on three challenging datasets. Experimental results show that our method achieves state-of-the-art performance.
Top-DB-Net: Top DropBlock for Activation Enhancement in Person Re-Identification
Oct 12, 2020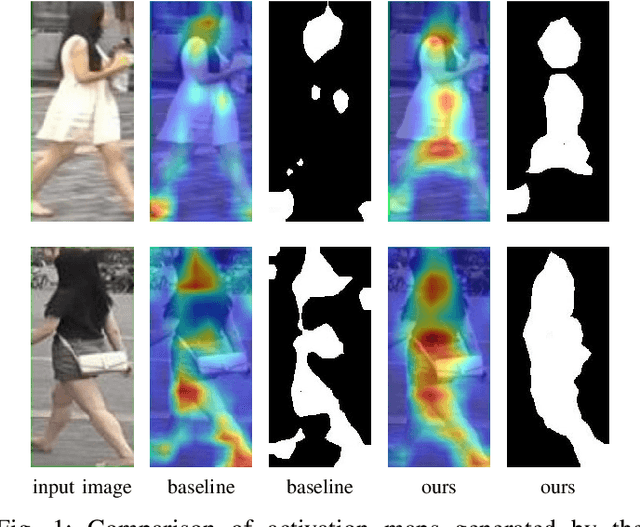

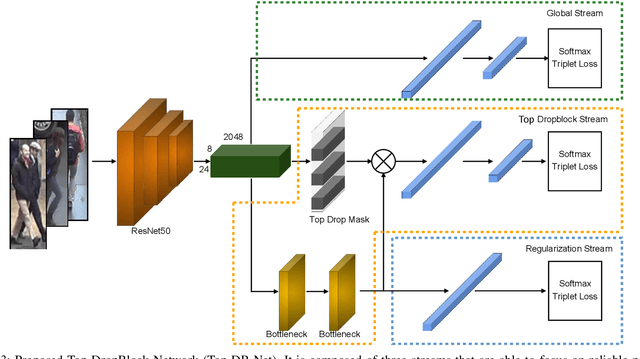
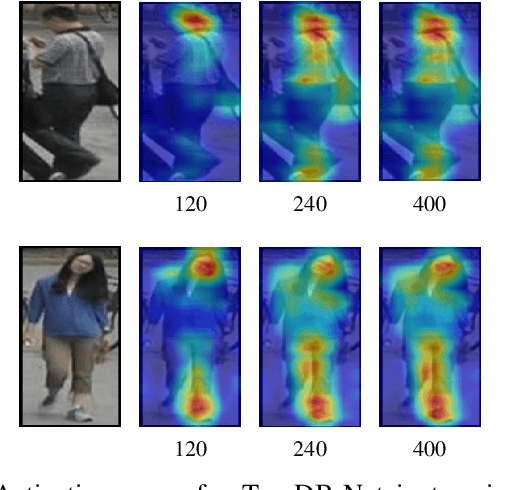
Person Re-Identification is a challenging task that aims to retrieve all instances of a query image across a system of non-overlapping cameras. Due to the various extreme changes of view, it is common that local regions that could be used to match people are suppressed, which leads to a scenario where approaches have to evaluate the similarity of images based on less informative regions. In this work, we introduce the Top-DB-Net, a method based on Top DropBlock that pushes the network to learn to focus on the scene foreground, with special emphasis on the most task-relevant regions and, at the same time, encodes low informative regions to provide high discriminability. The Top-DB-Net is composed of three streams: (i) a global stream encodes rich image information from a backbone, (ii) the Top DropBlock stream encourages the backbone to encode low informative regions with high discriminative features, and (iii) a regularization stream helps to deal with the noise created by the dropping process of the second stream, when testing the first two streams are used. Vast experiments on three challenging datasets show the capabilities of our approach against state-of-the-art methods. Qualitative results demonstrate that our method exhibits better activation maps focusing on reliable parts of the input images.
* Accepted on 25th International Conference on Pattern Recognition (ICPR2020)
MIMICS: A Large-Scale Data Collection for Search Clarification
Jun 17, 2020



Search clarification has recently attracted much attention due to its applications in search engines. It has also been recognized as a major component in conversational information seeking systems. Despite its importance, the research community still feels the lack of a large-scale data for studying different aspects of search clarification. In this paper, we introduce MIMICS, a collection of search clarification datasets for real web search queries sampled from the Bing query logs. Each clarification in MIMICS is generated by a Bing production algorithm and consists of a clarifying question and up to five candidate answers. MIMICS contains three datasets: (1) MIMICS-Click includes over 400k unique queries, their associated clarification panes, and the corresponding aggregated user interaction signals (i.e., clicks). (2) MIMICS-ClickExplore is an exploration data that includes aggregated user interaction signals for over 60k unique queries, each with multiple clarification panes. (3) MIMICS-Manual includes over 2k unique real search queries. Each query-clarification pair in this dataset has been manually labeled by at least three trained annotators. It contains graded quality labels for the clarifying question, the candidate answer set, and the landing result page for each candidate answer. MIMICS is publicly available for research purposes, thus enables researchers to study a number of tasks related to search clarification, including clarification generation and selection, user engagement prediction for clarification, click models for clarification, and analyzing user interactions with search clarification.
Multi-Stream Networks and Ground-Truth Generation for Crowd Counting
Mar 11, 2020

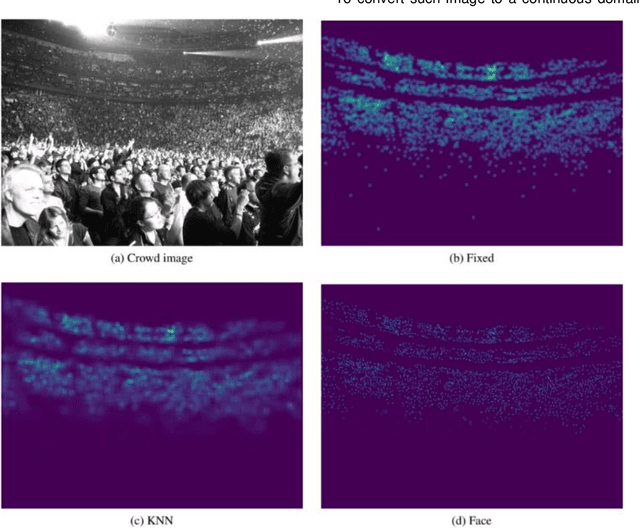
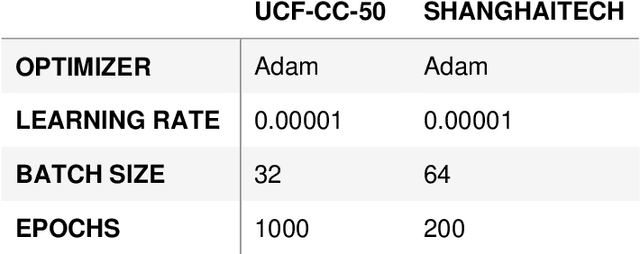
Crowd scene analysis has received a lot of attention recently due to the wide variety of applications, for instance, forensic science, urban planning, surveillance and security. In this context, a challenging task is known as crowd counting, whose main purpose is to estimate the number of people present in a single image. A Multi-Stream Convolutional Neural Network is developed and evaluated in this work, which receives an image as input and produces a density map that represents the spatial distribution of people in an end-to-end fashion. In order to address complex crowd counting issues, such as extremely unconstrained scale and perspective changes, the network architecture utilizes receptive fields with different size filters for each stream. In addition, we investigate the influence of the two most common fashions on the generation of ground truths and propose a hybrid method based on tiny face detection and scale interpolation. Experiments conducted on two challenging datasets, UCF-CC-50 and ShanghaiTech, demonstrate that using our ground truth generation methods achieves superior results.
Improved Person Re-Identification Based on Saliency and Semantic Parsing with Deep Neural Network Models
Jul 15, 2018



Given a video or an image of a person acquired from a camera, person re-identification is the process of retrieving all instances of the same person from videos or images taken from a different camera with non-overlapping view. This task has applications in various fields, such as surveillance, forensics, robotics, multimedia. In this paper, we present a novel framework, named Saliency-Semantic Parsing Re-Identification (SSP-ReID), for taking advantage of the capabilities of both clues: saliency and semantic parsing maps, to guide a backbone convolutional neural network (CNN) to learn complementary representations that improves the results over the original backbones. The insight of fusing multiple clues is based on specific scenarios in which one response is better than another, thus favoring the combination of them to increase performance. Due to its definition, our framework can be easily applied to a wide variety of networks and, in contrast to other competitive methods, our training process follows simple and standard protocols. We present extensive evaluation of our approach through five backbones and three benchmarks. Experimental results demonstrate the effectiveness of our person re-identification framework. In addition, we combine our framework with re-ranking techniques to achieve state-of-the-art results on three benchmarks.